

随着信息技术在社会各领域的深入渗透, 人类社会所拥有的数据总量达到了一个前所未有的高度. 一方 面, 海量数据为基于数据驱动的机器学习方法获取有价值的信息提供了充分的空间; 另一方面, 高维度、过冗余 以及高噪声也是上述繁多、复杂数据的固有特性. 为消除数据冗余、发现数据结构、提高数据质量, 原型学习是 一种行之有效的方式. 通过寻找一个原型集来表示目标集, 以从样本空间进行数据约简, 在增强数据可用性的同 时, 提升机器学习算法的执行效率. 其可行性在众多应用领域中已得到证明. 因此, 原型学习相关理论与方法的 研究是当前机器学习领域的一个研究热点与重点. 主要介绍了原型学习的研究背景和应用价值, 概括介绍了各类 原型学习相关方法的基本特性、原型的质量评估以及典型应用; 接着, 从原型学习的监督方式及模型设计两个视 角重点介绍了原型学习的研究进展, 其中, 前者主要涉及无监督、半监督和全监督方式, 后者包括基于相似度、 行列式点过程、数据重构和低秩逼近这四大类原型学习方法; 最后, 对原型学习的未来发展方向进行了展望.
http://www.jos.org.cn/jos/article/abstract/6365
引言
在当今信息爆炸时代, 信息的种类和数量空前激增. 面对如此海量的数据, 以机器学习尤其是深度学习 为核心的人工智能技术得到了长足的发展. 然而需要指出的是, 数据在量上的膨胀未必能带来在质上的提高. 如何有效地选择“用的了”且“用的好”的数据、如何从数据中获取最有用的信息, 成为摆在机器学习研究中的 重要问题. 诚如《大趋势》的作者奈斯比特所说: “我们被数据淹没, 但却渴求着知识”[1]. 一方面, 海量数据为 基于数据驱动的机器学习方法获取有价值的信息提供了充分的空间; 另一方面, 高维度、过冗余以及高噪声 也是上述繁多、复杂数据的固有特性. 这不但造成存储资源的巨大浪费, 而且还会显著提升学习算法的复杂 度. 更严重的是: 它们还会将真正有价值的信息湮没, 从而恶化学习算法的性能. 为消除数据冗余、发现数据 结构、提高数据质量, 从特征空间与样本空间进行数据约简是两种行之有效的方式, 在增强数据可用性的同 时, 提升机器学习算法的执行效率. 其中, 前者涉及到的技术包括特征降维(dimensionality reduction)[2,3]和特 征选择(feature selection)[4,5]; 而后者则涉及样本空间的原型生成(prototype generation)[6]和原型选择(prototype selection)[7]. 本文将样本空间的原型生成与选择, 统称为原型学习(prototype learning).
实质上, 原型学习问题涉及到众多领域的应用场景, 因而作为机器学习的研究重点之一, 与原型学习相 关的理论与方法的研究得到了国际上众多学者的普遍关注. 在国际有关机器学习的主流会议, 如 Advances in Neural Information Processing Systems (NIPS)、Int’l Conf. on Machine Learning (ICML)、Int’l Joint Conf. on Artificial Intelligence (IJCAI)和 AAAI Conf. on Artificial Intelligence (AAAI)等, 以及 IEEE Trans. on Pattern Analysis and Machine Intelligence (IEEE TPAMI)、Journal of Machine Learning Research (JMLR)等重要国际杂志 上, 每年都有大量的关于原型学习的最新工作发表. 此外, 来自美国东北大学的 Ehsan Elhamifar 教授、耶鲁大 学的 Amin Karbasi 教授、IBM Research AI 的 Rameswar Panda 研究科学家等人在 Computer Vision and Pattern Recognition (CVPR 2016、CVPR 2018、CVPR2019)国际会议上, 专门组织了关于原型选择中的算法与优化的 专题讲座[8,9]. 通过对以上大量文献的梳理可以看出: 原型学习的研究成果有助于挖掘出数据中最具价值的信 息, 提高用于机器学习的数据质量, 降低机器学习算法的计算复杂度、节约目标数据的存储成本、实现机器 学习模型的轻量化(模型压缩)等. 同时, 这也为大数据时代下的计算机视觉、图像与自然语言处理、生物医学、 信息推荐等领域提供理论基础与技术支撑, 满足与原型学习有关的应用需求.
鉴于原型学习问题在机器学习中的重要性, 国内一些研究机构近些年也对此开展了相关研究, 诸如南京 理工大学的杨静宇教授课题组[10]、西安电子科技大学的焦李成教授课题组[11]、清华大学的张长水教授课题 组[12]、南京大学的周志华教授课题组[13]、北京大学的张志华教授课题组[14]、中国科学院自动化研究所的刘成 林研究员课题组[15]等. 这些课题组的工作主要围绕监督条件下的核学习、主动学习以及示例学习中的原型选 择、矩阵列选择问题、图像分类中的原型学习等进行研究. 此外, 国内的一些研究学者还基于粗糙集理论从 数据的不确定性角度开展数据约简研究[16], 这类方法虽然能够有效去除数据冗余进而发现数据结构, 但是对 获得的原型的代表性缺乏直观物理解释, 并且原型的质量还不足以满足众多应用的需求. 更为重要的是: 尽 管目前国内外学者已经发表了大量关于原型学习的研究成果, 但是关于原型学习的综述性文献却很稀少, 对 于原型的定义与解释也不够清晰. 因此, 本文梳理了原型学习领域的相关文献, 对不同文献所采用的方案、面 向的应用以及存在的问题进行了归纳总结. 通过对前人工作的学习与理解, 我们能够发现原型学习领域研究 近几十年来的理论与应用发展脉络. 同时, 通过分析近几年原型学习领域的最新研究成果, 我们可以把握当 前主流的研究兴趣与方向, 探究诸多应用背景对原型学习的具体需求, 从而对未来原型学习研究的理论与应用发展方向进行一定的预测, 进而更高效地地服务实际应用.
**1 原型学习的相关概念与研究意义 **
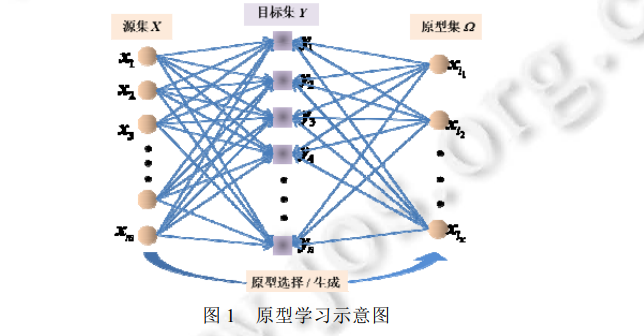
为了能够更好地理解原型学习的物理意义, 本节首先从广义上明确地阐述原型学习的定义及重要组成部 分, 这也是首次赋予原型学习明确的概念. 进而介绍机器学习中原型学习的研究背景, 尤其是在计算机视觉、 模式识别、数据可视化、资源配置、信息推荐等领域的应用价值与研究意义。 原型学习, 通常也被称为数据/示例选择(data/instance selection)[17,18]、子集选择(subset selection)[19]、样例 选择(exemplar/representative selection)[20,21]、核心集构造(core-set construction)[22,23].原型学习问题可以定义 为[7,24]: 假设有一个源集(source set) X={x1,x2,...,xm}和一个目标集(target set) Y={y1,y2,...,yn}, 分别包含 m 和 n 个 元素, 原型学习旨在从源集 X中寻找一个原型集/OmegaX, 使得/Omega能够最大程度地保持目标集 Y 所蕴含的信息; 同 时, /Omega中所有元素具有最少的重叠信息.
如何从海量数据中合理地选择原型, 在机器学习和数据科学中占有重要地位. 目前, 原型学习问题已经 是机器学习中主动学习、自步学习、生成对抗网络、支持向量机、模型压缩等算法的核心. 如图 4(a)所示, 通 过学习目标集的原型, 来重构支持向量机(support vector machine, SVM)、Logistic 回归、决策树(decision tree) 等机器学习算法[2529]的分类面; 如图 4(b)所示, 除了图像等视觉数据, 通过原型学习, 还可以对社交网络、人 际关系网络、大脑神经元网络等图数据进行采样. 因此, 原型学习不仅面向图像、文本等视觉数据类型, 还可 以面向图数据等多元化数据类型[30], 实现其原型集的选择.

**2 原型学习的研究概况 **
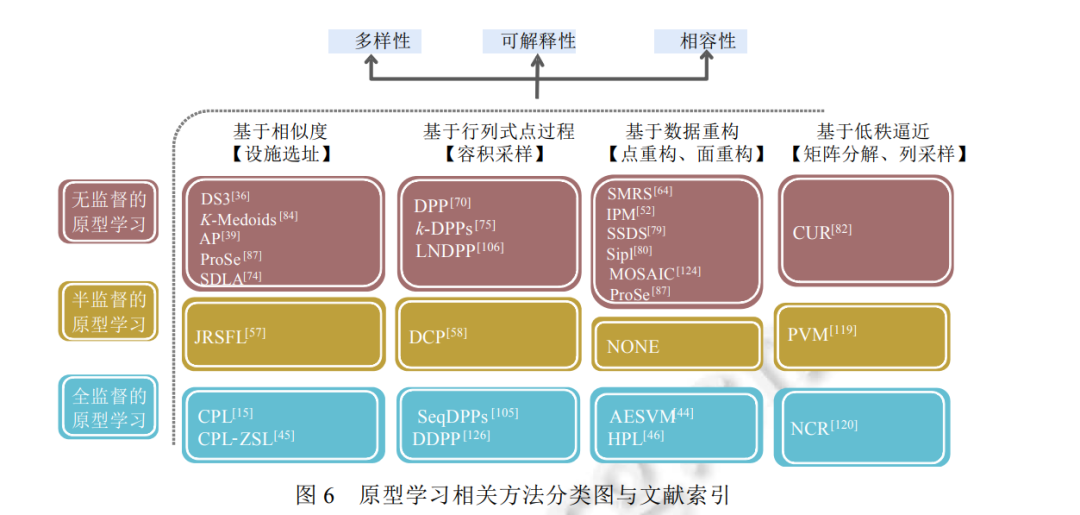
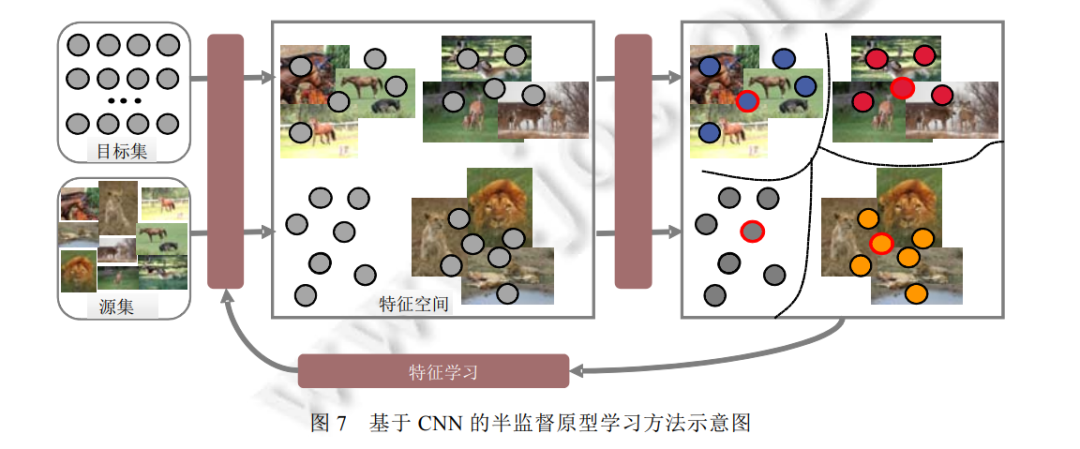
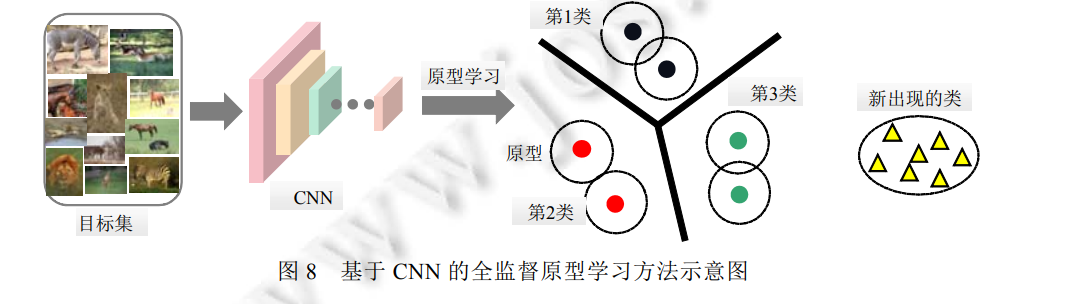
本节从原型学习的相关方法以及原型质量的定性/定量评估两个层面, 对原型学习的国内外研究现状进行梳理和概述。 原型学习的相关方法 从技术角度, 原型的获取可以通过两种方式: 一类是直接从源集中选取代表性的数据来构成原型集, 称 为选择法; 另外一类则是在源集中通过融合方式重新生成一组具有代表性的点, 称为生成法. 实际应用中, 若源集未被特定给出, 一般默认目标集同时担任源集. 目前, 根据是否有语义信息约束, 原型学习方法可以分 为无监督[52,55,56]、半监督[57,58]和全监督[45,5861]的原型学习. 其中, * 全监督下的原型学习一般根据样本对分类结果的贡献度来选择对模型最具可解释性的样本原型, 诸 如最为经典的学习矢量量化(learning vector quantization, LVQ)方法[62,63]以及第一个基于深度学习的 原型学习方法——卷积原型学习(convolutional prototype learning, CPL)方法[15]; * 半监督下的原型学习需要通过带标签样本向不带标签样本的信息传递来推理出所有样本的权重及相 关性, 进而令权重较高的样本担任目标集的原型. 文献[57]提出了一种集成原型选择与特征学习的算 法, 这也是在半监督场景下学习原型的最新代表作; * 最后, 作为最常见、研究频率最高的场景, 无监督原型学习通常根据目标集的固有分布与结构来选择 对数据最具代表性的样本原型, 诸如 Elhamifar 教授在文献[36]中提出的基于非相似性的稀疏子集选 择(dissimilarity-based sparse subset selection, DS3)方法以及在文献[64]中提出的稀疏建模样例选择 (sparse modeling representative selection, SMRS)方法.
图6 利用现有文献举例阐述了原型学习的 3 种监督方式和 4 类原型学习模型. 从中发现: 除基于数据重 构的原型学习模型之外, 基于相似度、行列式点过程以及低秩逼近的三大类原型学习模型均能在不同的监督 方式下工作. 原因在于: 现有的基于数据重构的原型学习方法还未充分考虑如何有效利用少量数据的语义信 息, 来进一步提高原型的代表性.
**2.2 原型的质量评估 **
在原型学习中, 所学原型的质量, 尤其是原型的多样性、可解释性和相容性, 直接决定了机器学习、数据 分析与处理、计算机视觉等原型学习相关应用的效率. 因而, 如何评价原型质量的好坏至关重要. 现有的原型 学习方法涉及定性和定量两种评价方式, 但并不存在一个统一的评价标准. 总的来说, 定性评价通常观察并 可视化原型在目标集中的位置, 以证明所学原型完全覆盖了目标集的分布, 并揭示了它的结构信息[79,87]. 而 定量评价则需要依赖具体任务与算法. 对于全监督原型学习方法, 分类、检索等任务的性能间接反映出原型 的质量. 例如: CPL[15]在 CNN 中额外引入原型学习损失函数, 从而不仅提高了在大数据集上的图像识别性能, 还能够识别新出现的图像种类. 而识别精度的提高, 主要源于所学原型的强判别性和代表性. 与全监督场景 类似, 半监督原型学习方法通常也借用图像分类、检索、视频分析等任务的性能来反映原型的质量[65]. 此外, k-NN、SVM、CNN 等分类算法通常也被用于评价原型的判别性和多样性. 其中, 从原始训练集中选择出的原 型充当分类算法的约简训练集, 用于执行测试集的分类任务[36,63,74,79].
不同于上述两类有监督原型学习场景, 无监督原型学习方法通常利用原型学习最直观的应用, 诸如视频 摘要[64,83]、推荐系统[51]和运动分割[36,87], 以评价原型的代表性和相容性. 特别地, 无监督下的原型一般被赋予 明确的物理意义, 比如视频摘要中的关键帧和运动分割中的运动目标, 因此, 原型的可解释性也得到了充分 保证.
**3 原型学习的监督方式 **
原型学习中, 语义信息约束了原型学习的监督方式. 目前, 原型学习方法依据监督方式可以分为 3 类: (1) 无监督原型学习[52,55,56]; (2) 半监督原型学习[57,58]; (3) 全监督原型学习[15,5861].
**4 原型学习的相关模型 **
为了获取满足机器学习算法、数据分析与处理、计算机视觉、模式识别、信息推荐、资源配置等后续任务需求的高质量原型, 现有的原型学习方法通常设计各种各样的目标优化函数, 以约束原型的可解释性、多 样性以及相容性. 依据模型的优化目标, 目前, 原型学习方法主要包括 4 类: (1) 基于相似度/非相似度的原型 学习; (2) 基于行列式点过程(DPP)的原型选择; (3) 基于数据重构的原型学习; (4) 基于低秩逼近的原型选择. 本节从原型学习的模型设计视角, 详细描述目前原型学习的常用方法, 并分析该类方法所面临的各种问 题及诸多挑战.
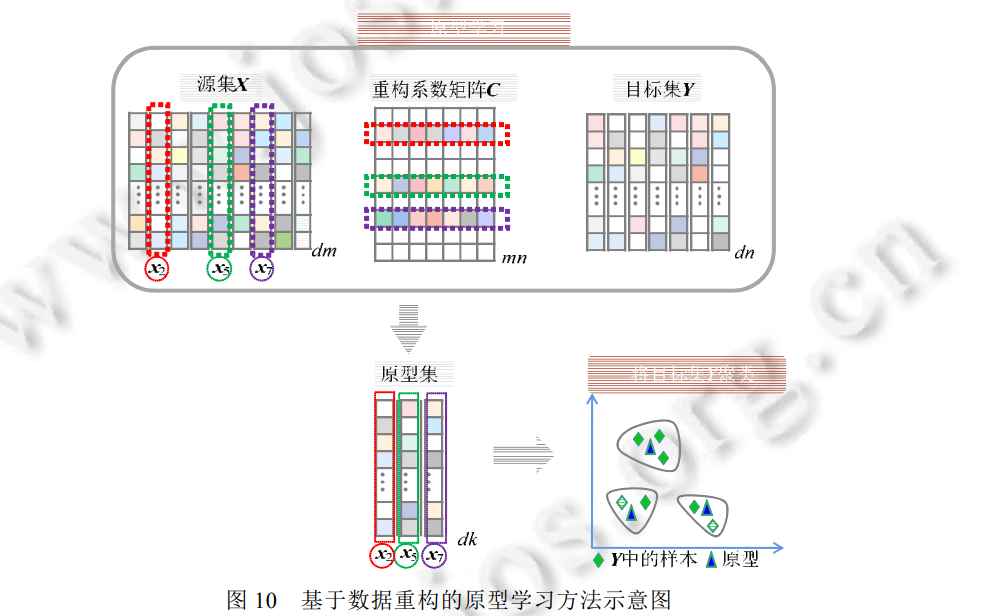
**5 总结与展望 **
本节将对原型学习的现有工作加以概括和总结, 并针对目前研究内容的缺陷, 对原型学习未来的工作给 予规划和展望.
**5.1 原型学习的工作总结 **
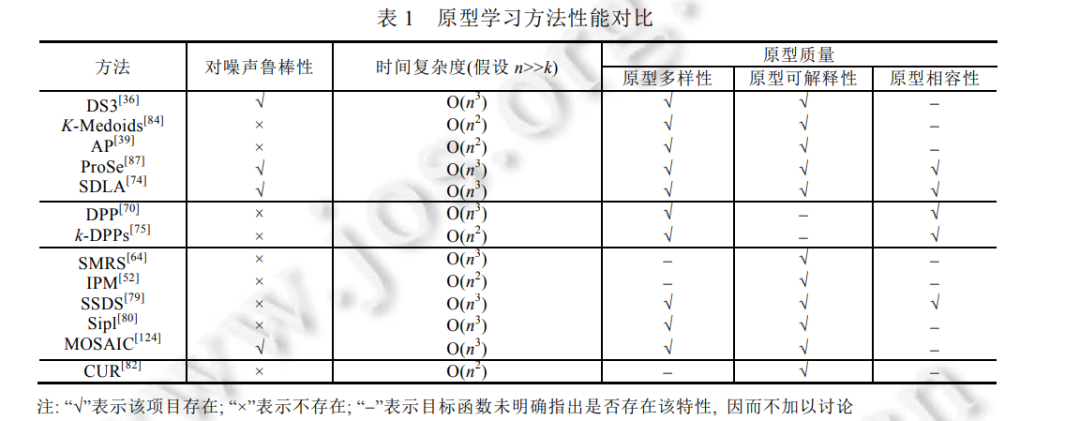
本文通过对现有文献的梳理和总结, 分别从原型学习的监督方式与模型设计两个层面, 介绍了已有的原 型学习方法. 目前, 原型学习方法依据监督方式可以分为无监督、半监督和全监督原型学习. 其中, 无监督场景最为常 见, 而半监督研究成果最为稀少. 然而, 由于语义信息的约束, 全监督下学习的原型具有更强的判别性, 而无 监督学习出的原型由于充分挖掘出目标集的分布与结构信息, 因此具有更强的代表性. 另外, 依据模型设计 的目标, 现有的原型学习方法主要有基于相似度/非相似度、行列式点过程、数据重构和低秩逼近的原型学习 这 4 种. 其中, 基于数据重构的原型学习对服从子空间分布的目标集更有效; 而基于相似度/非相似度的原型 学习虽然不限制数据特质, 但是需要事先提供一个极具判别力的度量空间; 基于行列式点过程的原型学习方 法能够利用行列式约束原型的多样性, 但是优化目标单一, 忽略了原型的可解释性等其他质量指标; 最后, 基于低秩逼近的原型学习原理最为直观, 同时也容易实现, 但是关于矩阵运算的复杂度在一定程度上限制了 该类方法在大规模数据集上的实施. 表 1 选取了无监督下常用的四大类原型学习方法作为对比参考, 因为其 他监督方式下的代表性方法较少, 所以在此不多加讨论. 由表1可以看出, 目前绝大部分原型学习方法都没有 灵活应对噪声的能力. 此外, 在原型学习时引入的约束越多, 原型的质量也越高, 分类效果越好. 但同时, 该 算法的复杂度随之有所提高.
**5.2 原型学习的未来方向 **
通过分析近几年原型学习领域的最新研究成果, 探究诸多应用背景对原型学习的具体需求, 本文对未来 原型学习研究的理论与应用发展方向进行了一定的预测, 具体包括:** 知识迁移驱动的原型生成 **
原型质量与原型学习模型可利用的信息量成正比关系. 显然, 提供的信息越多, 获取的原型越能更好地 捕获目标数据的分布. 然而, 现有的原型学习只利用有限的目标数据且无任何监督信息, 这必然会弱化原型 的可解释性. 为了充分利用大数据时代已标注的海量数据资源, 未来工作应沿着跨域引入辅助集的方向探索, 而非传统的监督式原型学习[119,120]. 但同时, 尽可能约简与目标集相关的假设和先验知识, 以增加其适用范 围. 例如, 为了将训练好的复杂模型的“知识”迁移到一个结构更为简单的小型网络中, 进而方便模型部署, Hinton 等人曾提出了蒸馏网络模型[121]. 受该模型启发, 文献[122]提出了数据蒸馏的概念: 保持模型固定, 尝 试将大型训练数据集中的知识提炼成小数据. 其中, 这些合成的少量数据不需要一定来自正确的数据分布, 但当作为模型的训练数据学习时, 能达到近似在原始数据上训练的效果. 未来, 是否可以将模型蒸馏和数据 蒸馏进行融合以进行原型学习十分值得探讨. 其核心思想是: 利用一个额外的有标记的辅助数据集, 即使其 语义标签集合与目标数据集的语义标签集合没有任何交集, 但通过模型知识蒸馏并迁移到目标数据集, 可以 生成一个小规模的原型集. 这样不仅可以描述目标数据集的分布, 还可以泛化到其他数据集, 并对其进行分 类、预测等多种推理任务. 以一个小样本学习的任务为例: 为了识别“犀牛”和“斑马”这两个物种, 专家分别标 注了 5 个样本. 从如此极少量样本中快速学习一个分类模型, k 近邻分类器固然可行, 但是如若可以利用庞大的已标注的数据集以及预训练模型(比如 ImageNet 数据集中的“黄牛”和“白马”)进行知识迁移, 以更加全面地 学习“犀牛”和“斑马”的原型, 进而利用原型进行 k 近邻分类, 那么性能在一定程度会得以提升.
** 有缺陷数据的原型生成 **
对于给定的目标集数据, 通常在底层特征空间和高层语义空间容易出现缺陷. 对于前者, 现有的大多数 原型学习算法通常假设数据点可以用低维子空间很好地逼近. 然而, 实际应用中的很多数据具有显著的噪声 点、离群值和缺失值, 因此低维子空间(或者它们的并集)可能无法很好地拟合数据[36,123,124]. 这一事实要求原 型学习算法同时具有鲁棒性, 能够在所有这些缺陷存在的情况下识别极具信息量的数据点. 然而, 现有的有 缺陷数据的原型生成算法主要针对特定类型的噪声和异常值. 比如文献[123]提出一种可伸缩的列/行子空间 追踪算法, 用于从含有任意幅度的稀疏噪声的数据中选择原型. 对于后者, 现有的原型学习方法基本上都是 以无、自、半监督和全监督的方式实施, 并未考虑标签也容易存在缺陷. 比如, 数据只给出了粗粒度标签或者 有噪声的标签. 对此, 弱监督的原型学习则需要引起极大的重视, 包括不确切监督和不精确监督, 以迎合实际 应用场景的迫切需求.
** 原型分布式学习 **
鉴于隐私保护等安全考量, 目标数据极有可能来自不同的工作站且无法集中受理, 这也为原型学习带来 极大的挑战. 随着目前硬件设备计算能力的快速升级以及分步式计算框架的逐渐成熟, 针对分布式环境下的 原型学习研究是十分有潜力的一个方向, 具体的研究内容包括将经典的原型学习算法在分布式框架下实施, 亦或是设计全新的面向分步式系统的原型学习算法. 这一方向的优势在于: 通过最大化利用分步式计算的效 能, 不仅保护各个工作站的数据信息, 同时还可以有效解决传统原型学习算法的准确率与效率无法同时满足 的问题.
** 面向深度学习的原型学习 **
原型学习方法通过识别信息量最大的训练实例来提高大规模数据集机器学习的数据效率, 已经受到越来 越多的关注. 然而, 由于它们依赖于需要学习的特征表示, 因此在深度学习中应用它们的成本可能高得令人 望而却步. 随着深度学习算法的普及, 面向深度学习的原型学习研究显得越来越重要. 目前, 在相关领域内, 已经存在一些研究工作[17]着眼于如何通过一个小代理模型来执行原型学习, 从而大大提高计算效率. 因此, 设计一个与下游任务有关且泛化能力极强的代理模型也是十分有潜力的研究方向. 例如, 通过从目标模型中 移除隐藏层, 使用更小的体系结构, 并训练更少的时间段, 这样创建的代理模型可以将训练速度提高一个数 量级. 此外, 得益于深度学习已经取得的出色性能, 将原型学习模型与深度学习框架相结合, 也是未来发展的 必然趋势[17,122,125,126].
** 原型的质量评价体系 **
目前, 几乎所有的原型学习算法都需要依赖其他各种应用(诸如视频摘要、聚类和分类检索)来证明它们的 有效性. 换言之, 原型学习问题迫切需要一个统一的数据驱动的评价标准, 而非任务驱动的评价标准, 以精准 度量原型的质量, 尤其是可解释性、代表性和多样性. 事实上, 原型选择的目的是通过采集最具信息量的样本 子集, 形成对目标集的有效刻画. 而相对于非原型来说, 原型之所以具有很好的可解释性(代表性)的原因在于 其具有很强的显著性. 目前, 得到广泛研究的通过自下而上的(bottom-up)方式来获得原型集的方法, 难以对 选择出的原型的代表性给出定量的解释. 针对该问题, 未来拟通过图传递模型, 建立一种基于显著性采样的 自上而下(top-down)原型选择机制, 从而有效地获得评价潜在原型显著性的置信度. 此外, 对于选择出来的原 型, 未来还可以通过 Nyström 方法来计算样本矩阵恢复的质量, 进而以此定量评价选出原型的质量.
