自大语言模型(LLMs)问世以来,研究工作主要集中在提升其指令执行与演绎推理能力,而是否能够真正实现新知识的发现仍是一个悬而未决的问题。在追求通用人工智能(AGI)的过程中,人们对模型的期待已不再仅限于执行指令或检索信息,更希望其具备学习、推理并通过构建新假设与理论来生成新知识的能力,从而加深我们对世界的理解。
本综述以皮尔士(Peirce)提出的“溯因(abduction)、演绎(deduction)与归纳(induction)”三段论架构为指导,提供了一个结构化视角,以审视基于 LLM 的假设发现能力。我们对当前在假设生成、应用与验证方面的研究进行了系统梳理,既总结了关键成果,也指出了尚待解决的核心问题。 通过整合这一领域的多项研究线索,我们展示了 LLM 如何有潜力从“信息执行器”转变为真正的“创新引擎”,从而为科研、科学探索以及现实问题的解决带来深远影响。
1 引言
人类智能的一个核心支柱在于发现假设与学习规则的能力,我们将这种能力称为假设发现(hypothesis discovery)或规则学习(rule learning)。早期的人工智能系统在这一方面表现不佳,原因在于形式化的符号推理方法缺乏构建创造性规则所需的常识背景知识(Yu 等, 2024a)。 近年来,自然语言处理(NLP)的发展带来了预训练于大规模文本语料的大语言模型(LLMs),这些模型在内部嵌入了大量常识性知识,使其能够胜任诸如提出新假设和推导新结论等需要丰富背景知识的任务。
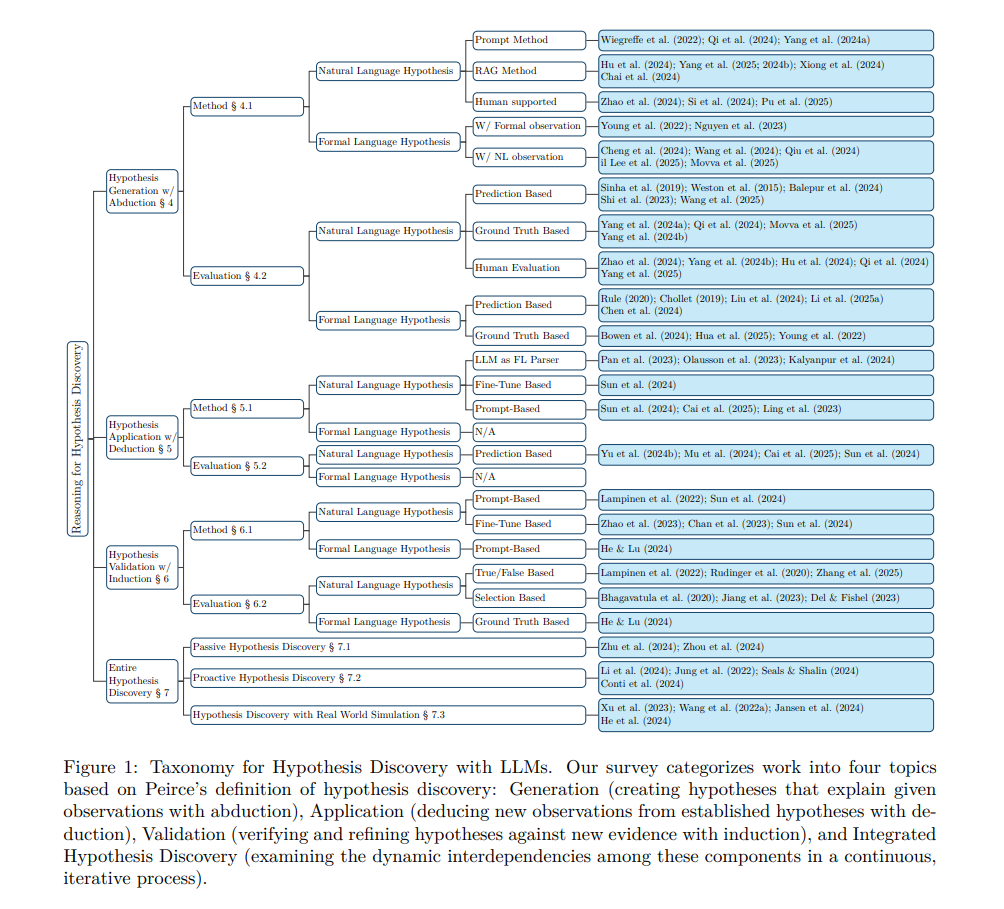
假设发现本质上依赖于一种融合了溯因(abduction)、归纳(induction)与演绎(deduction)的综合推理能力。不同学者对这三者有不同定义。例如,Gilbert H. Harman 将归纳视为溯因的一种特殊情况,定义其为“对最佳解释的推理(Inference to the Best Explanation, IBE)”(Harman, 1965;Douven, 2021)。尽管这一定义易于理解,但它过于简化了假设发现的核心过程。尤其是,“最佳”解释这一概念本身就存在歧义,往往依赖于不同语境下的附加假设。此外,该框架也未能充分体现现实世界中的动态过程:我们往往不会立即得出一个“最佳”解释,而是通过持续实验、获取新观察、不断修正假设来推进认知。 基于上述考虑,本文采纳查尔斯·皮尔士(Charles Peirce)对假设发现与推理的定义。该定义认为,假设发现始于通过“溯因”提出解释性假设来解释观察现象,随后通过“演绎”反复应用这些假设以解决问题或推导新知识,最后通过“归纳”对假设进行验证(Frankfurt, 1958;Peirce, 1974;Burks, 1946;Minnameier, 2004)(详见图 2 的说明)。
本综述结构如下:
第2节介绍 LLM 支持下的假设发现所需的背景知识,包括相关的推理方式和表示方法; * 第3节回顾以往关于 LLM 推理与假设发现的综述,指出其多聚焦于演绎推理任务或特定领域应用的局限性; * 第4节探讨提出假设的方法(即溯因); * 第5节介绍应用这些假设的方法(即演绎); * 第6节则重点讨论通过新观察来验证假设的技术(即归纳); * 第7节综合分析整个假设发现循环,探讨三种推理方式之间的相互依赖关系,展示如何通过溯因、演绎与归纳的迭代组合,逐步构建更稳健的假设体系。
在每一阶段,我们将讨论现有方法、数据集基准、评估机制,并指出当前存在的挑战与未来研究方向。 本综述的整体分类框架如图1所示。