

近年来,大语言模型(Large Language Models, LLMs)已成为广泛人工智能应用的核心工具。随着 LLMs 的使用范围不断扩展,精准评估其预测中的不确定性变得至关重要。然而,当前方法通常难以准确识别、衡量和解决真正的不确定性,许多研究主要集中在估算模型的置信度。这种差异很大程度上源于对不确定性注入模型的方式、时机和来源缺乏完整的理解。本文提出了一个专门设计的综合框架,用于识别和理解不确定性的类型及来源,并与 LLMs 的独特特性相契合。该框架通过系统地分类和定义每种类型的不确定性,增进了对不确定性多样性格局的理解,为开发能够精准量化这些不确定性的方法奠定了坚实基础。 此外,我们详细介绍了关键相关概念,并深入探讨了当前方法在任务关键型和安全敏感应用中的局限性。本文最后展望了未来研究方向,旨在提升这些方法的可靠性及其在真实场景中的实用性,从而促进其广泛应用。

近年来,大语言模型(Large Language Models, LLMs)在复杂推理和问答任务中表现出了显著的能力(Zhao et al., 2023; Wang et al., 2024c; Liang et al., 2022)。然而,尽管展现了巨大的潜力,LLMs 仍然面临生成错误答案的重大挑战(Ji et al., 2023a; Li et al., 2023a; Huang et al., 2023),在对高精度和高可靠性要求较高的领域,这种情况可能产生严重后果。LLM 输出中信任度不足的一个核心问题在于其决策过程缺乏透明性和可解释性(Zhou et al., 2023; Lin et al., 2023; Yin et al., 2023; Xiao & Wang, 2018; Hullermeier & Waegeman, 2021)。在这种背景下,全面理解和评估模型的不确定性至关重要。例如,在医疗领域,当医生诊断如癌症等关键病症时,不仅需要模型提供高预测准确性,还需要明确了解预测中的不确定性(Gawlikowski et al., 2022a; Wang et al., 2022)。 尽管量化 LLMs 不确定性的必要性已被广泛认可,但对于不确定性的定义和解释在这一新背景下仍未达成一致(Gawlikowski et al., 2022a; Mena et al., 2021; Guo et al., 2022; Hullermeier & Waegeman, 2021; Malinin & Gales, 2018),这进一步增加了其估计的复杂性。不确定性、置信度和可靠性等术语常被混用,但它们实际上代表着需要仔细区分的不同概念(Gawlikowski et al., 2021)。例如,LLM 可能对一个本质上不确定且无答案的问题生成高置信度的回应,但这种回应可能在语境上不恰当或在事实层面上不正确,这表明高置信度并不等同于低不确定性(Gawlikowski et al., 2022b)。因此,现有文献中面临的首个挑战是明确 LLMs 背景下的不确定性定义,并探讨这些交织概念之间的细微差别。 传统上,深度神经网络(DNNs)中的不确定性被划分为两类:固有不确定性(aleatoric),由数据随机性(如传感器噪声)引起;以及认知不确定性(epistemic),源于模型知识的局限性,如数据不足或未建模的复杂性(Gawlikowski et al., 2022a; Mena et al., 2021; Guo et al., 2022; Hullermeier & Waegeman, 2021; Malinin & Gales, 2018)。尽管这些分类在深度学习领域广泛使用,但它们无法完全涵盖 LLMs 的独特挑战,包括处理复杂文本数据、管理极其庞大的参数量,以及面对通常不可访问的训练数据。此外,LLM 生命周期的各个阶段——从预训练到推理——都会引入独特的不确定性,而用户与这些模型的交互同样如此。理解这些不确定性来源,特别是从提高 LLMs 可解释性和鲁棒性的角度来看,至关重要。然而,若没有一个包容性和细粒度的框架来系统地识别和分析 LLMs 中的不确定性来源,实现这一目标是不可能的。
近期,已有大量研究尝试估计 LLMs 的不确定性(Manakul et al., 2023; Beigi et al., 2024; Azaria & Mitchell, 2023a; Kadavath et al., 2022; Kuhn et al., 2023),这些方法大致可以根据其基本机制分为四类:基于 logits 的方法(Lin et al., 2022b; Mielke et al., 2022a; Jiang et al., 2021; Kuhn et al., 2023)、自评估方法(Kadavath et al., 2022; Manakul et al., 2023; Lin et al., 2024a)、基于一致性的方法(Portillo Wightman et al., 2023; Wang et al., 2023),以及内部机制驱动的方法(Beigi et al., 2024)。然而,鉴于 LLMs 的独特特性和不确定性的微妙方面,各类方法在 LLMs 背景下捕捉真正的不确定性或相关因素的有效性,以及在 LLM 生命周期不同阶段中检测到的具体不确定性来源,仍然存在关键问题。这些问题的回答对于开发更可靠、更全面的不确定性估计方法至关重要。
为了解决上述挑战和问题,我们对与不确定性及其相关概念相关的研究进行了关键综述和分析,旨在呈现涵盖 LLMs 不确定性全景的综合综述,特别关注不确定性概念、来源、估计方法与文本数据特征之间的相互作用。据我们所知,这一领域尚缺乏类似的系统性研究**。综上所述,本文的贡献体现在以下几个方面,这些贡献具有开创性和多样性**:
- 标准化了不确定性的定义,并探索了相关概念,从而促进了领域内的交流(第二节)。
- 首次提出了一个全面的框架,用于分析 LLM 生命周期中所有不确定性来源,深入揭示其起源及有效管理策略(第三节)。
- 对当前用于估计和评估 LLM 不确定性的方法进行了评估和比较,讨论了它们的优缺点(第四节)。
- 最后,识别了增强 LLM 不确定性估计的未来研究方向,解决关键研究空白并探讨新兴趋势,以在任务关键型应用中提高可靠性和准确性(第五节)。
在深度学习中,不确定性传统上被划分为三类:(1)模型(认知)不确定性,与模型参数估计中的不确定性相关,反映了模型拟合的能力及其对未见数据的泛化局限性(Der Kiureghian & Ditlevsen, 2009;Lahlou et al., 2023;Hullermeier & Waegeman, 2021;Malinin & Gales, 2018);(2)数据(或固有)不确定性,源于数据本身的复杂性,例如类别重叠和各种噪声(Der Kiureghian & Ditlevsen, 2009;Rahaman & Thiery, 2020;Wang et al., 2019;Malinin & Gales, 2018);(3)分布不确定性,通常由于数据集分布偏移引起,当训练和测试数据分布不同而导致模型在真实场景中面临泛化问题(Malinin & Gales, 2018;Nandy et al., 2021;Gawlikowski et al., 2022a;Chen et al., 2019;Mena et al., 2021)。
尽管这些传统分类在深度学习中应用广泛,但它们无法充分应对 LLMs 所面临的独特挑战。LLMs 的特点包括庞大的参数规模、复杂的文本数据处理,以及通常难以获取的训练数据,这些特性在模型输出中引入了特定的不确定性。此外,与用户在动态环境中的交互,以及数据标注或模型校准中的人为偏差,使不确定性的景观更加复杂。与主要预测数值输出或类别的通用深度学习模型不同,LLMs 生成的是基于知识的输出,这些输出可能包含不一致或过时的信息(Lin et al., 2024b)。这些特性无法通过简单地将不确定性划分为三种传统类型来充分描述。
新框架:LLM 不确定性分类
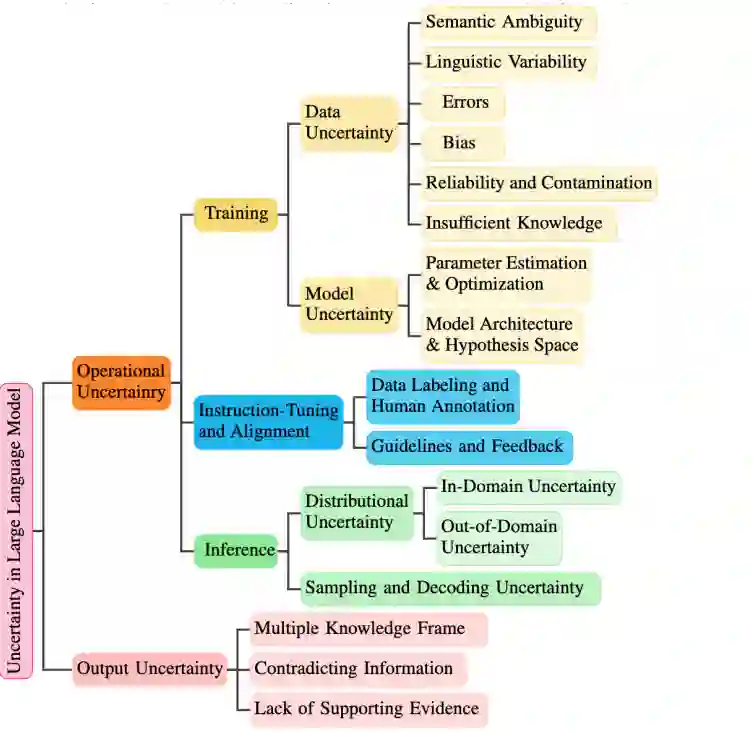
为了应对这些挑战,我们提出了一个新的框架,用于对 LLMs 中的不确定性进行分类,如图 2 所示。该框架将不确定性区分为两类:操作性不确定性和输出不确定性,分别对应模型和数据处理过程以及生成内容的质量。
**1. 操作性不确定性
操作性不确定性贯穿于从预训练到推理的整个生命周期,涵盖数据获取、模型和架构设计、训练与优化过程、校准以及推理活动。这些不确定性源于以下方面:
- 数据处理与模型训练:LLMs 在处理大规模数据集、输入数据及生成文本时无法完全捕捉数据的复杂性。
- 输入数据的模糊性或噪声:输入数据本身的不完整性或多义性增加了操作性不确定性。
**2. 输出不确定性
输出不确定性与生成文本的分析和解释中的挑战相关,具体涉及信息质量及其在决策过程中的可靠性。例如,在医疗场景中,LLM 需要根据患者症状提供诊断建议。若生成的建议缺乏充分的证据支持或包含矛盾信息,医生需要判断这些建议的可信度,这就带来了显著的不确定性。医生在决定进一步调查哪种诊断时可能面临巨大挑战,这突显了 LLM 提供支持充分、输出一致且可靠内容的重要性,以确保其在决策过程中的实用性。
框架的优势
通过区分操作性不确定性和输出不确定性,该框架带来了以下几个关键优势:
- 细粒度视角:捕捉 LLMs 的独特特性,更精准地反映不确定性,从而有助于更好的建模与理解。
- 明确不确定性来源:为开发针对性的量化方法奠定基础,能够准确地量化各类不确定性。
- 针对不同角色的洞见:为开发者、用户和管理员提供具体的指导,帮助其解决各自角色中相关的不确定性问题,从而提升模型鲁棒性、用户交互体验和治理能力。
- 构建对模型输出的信任:通过汇总多种观点和评估输出证据,该框架特别适用于医疗诊断或法律推理等关键领域,增强对 LLM 输出的信任度。
这一框架为更深入地理解 LLMs 的不确定性提供了基础,并为进一步提升其可靠性和实用性指明了方向。