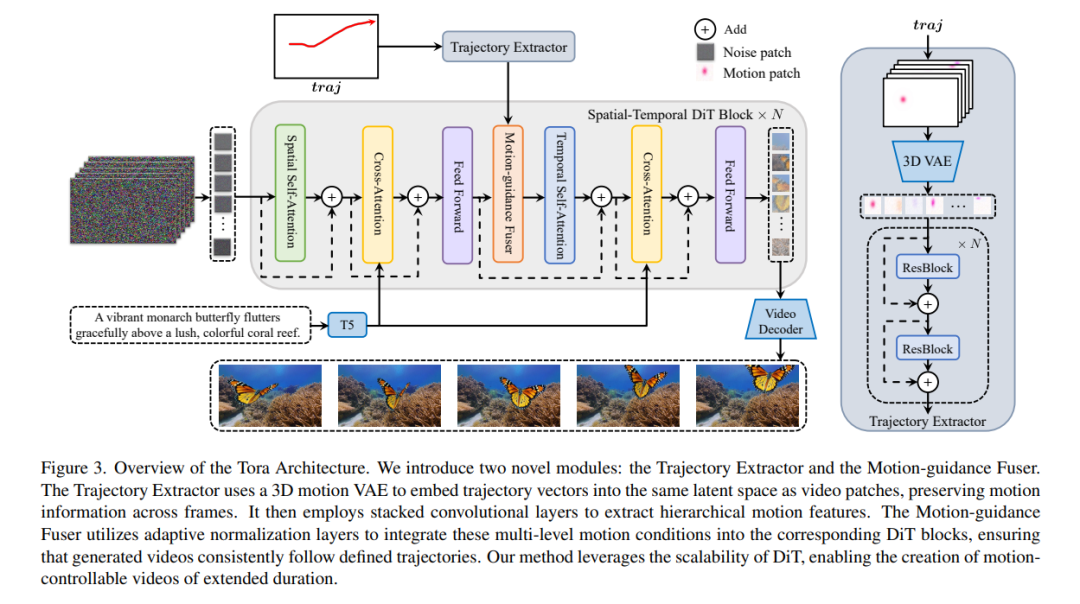
- VGGT:基于视觉几何的Transformer模型
我们提出了VGGT,这是一种前馈神经网络,能够直接从场景的一个、几个甚至数百个视角中推断出所有关键的3D属性,包括相机参数、点云图、深度图和3D点轨迹。这一方法在3D计算机视觉领域迈出了重要一步,因为传统模型通常局限于单一任务并专门优化。VGGT不仅简单高效,能够在不到一秒的时间内重建图像,而且在性能上超越了需要后处理(如视觉几何优化技术)的替代方案。该网络在多个3D任务中实现了最先进的成果,包括相机参数估计、多视角深度估计、密集点云重建和3D点跟踪。我们还展示了使用预训练的VGGT作为特征骨干网络能够显著提升下游任务的性能,例如非刚性点跟踪和前馈式新视角合成。代码和模型已公开,可在以下链接获取:https://github.com/facebookresearch/vggt。
https://arxiv.org/pdf/2503.11651
- 基于循环增强的视觉-语言Transformer模型:面向鲁棒的多模态文档检索
跨模态检索正因其在大规模训练、新颖的架构与学习设计以及在LLM和多模态LLM中的应用而受到研究界的广泛关注和认可。在本文中,我们进一步设计了一种支持多模态查询(由图像和文本组成)的方法,并能够在多模态文档集合中进行检索,其中图像和文本是交替出现的。我们的模型ReT采用了从视觉和文本骨干网络的不同层次提取的多级表示,无论是在查询端还是文档端。为了实现多层次的跨模态理解和特征提取,ReT引入了一种基于Transformer的新型循环单元,该单元在不同层次上整合了文本和视觉特征,并借鉴了LSTM经典设计的Sigmoid门控机制。在M2KR和M-BEIR基准上的大量实验表明,ReT在各种设置下均实现了最先进的性能。我们的源代码和训练模型已公开,可在以下链接获取:https://github.com/aimagelab/ReT。 https://arxiv.org/abs/2503.01980

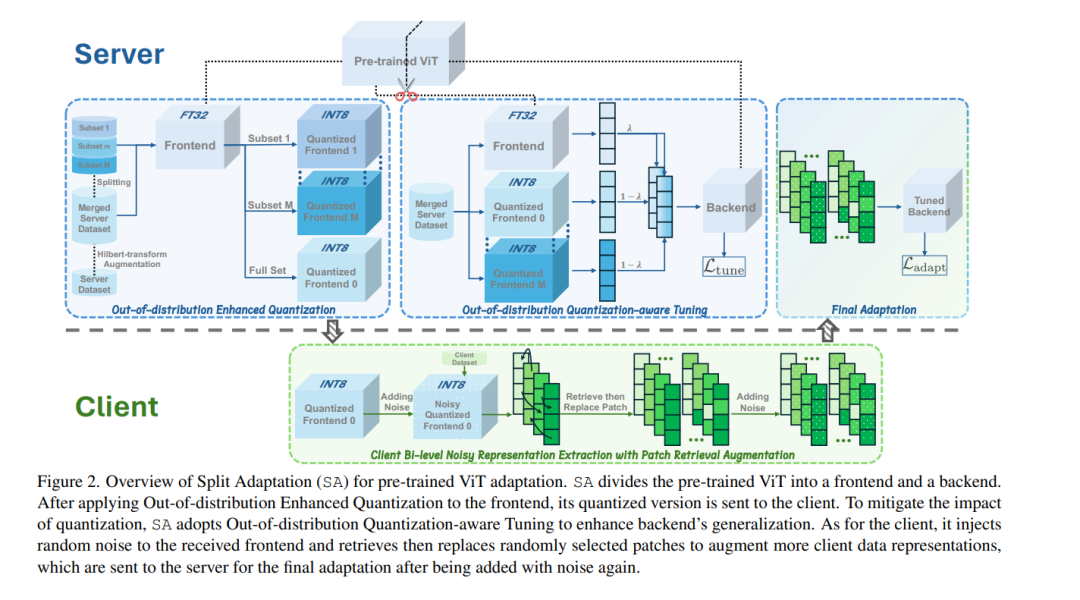
- 分割自适应预训练视觉Transformer
在大规模数据集上广泛预训练的视觉Transformer(ViTs)已成为基础模型的核心组成部分,使其能够在多种下游任务中以最小的适应成本实现卓越性能。因此,如何在不同领域(包括隐私敏感领域)中适应预训练的ViTs引起了越来越多的关注,尤其是在客户通常不愿共享数据的情况下。现有的适应方法通常需要直接访问数据,这使得它们在上述限制条件下难以实施。一个简单的解决方案可能是将预训练的ViT发送给客户进行本地适应,但这会引发模型知识产权保护问题,并给客户带来沉重的计算负担。为了解决这些问题,我们提出了一种新颖的分割自适应(SA)方法,该方法能够在保护数据和模型的同时实现有效的下游适应。SA受到分割学习(SL)的启发,将预训练的ViT分为前端和后端,仅将前端与客户共享以提取数据表示。但与常规SL不同,SA用低比特量化值替换前端参数,防止模型直接暴露。SA允许客户在前端和提取的数据表示中添加双层噪声,从而确保数据保护。相应地,SA结合了数据级和模型级的分布外增强,以减轻噪声注入对适应性能的影响。我们的SA专注于具有挑战性的少样本适应,并采用补丁检索增强来缓解过拟合问题。在多个数据集上的大量实验验证了SA相对于最先进方法的优越性,并展示了其在防止模型泄露的同时抵御高级数据重建攻击的能力,且客户端的计算成本极低。源代码可在以下链接获取:https://github.com/conditionWang/Split_Adaptation。 https://arxiv.org/pdf/2503.00441
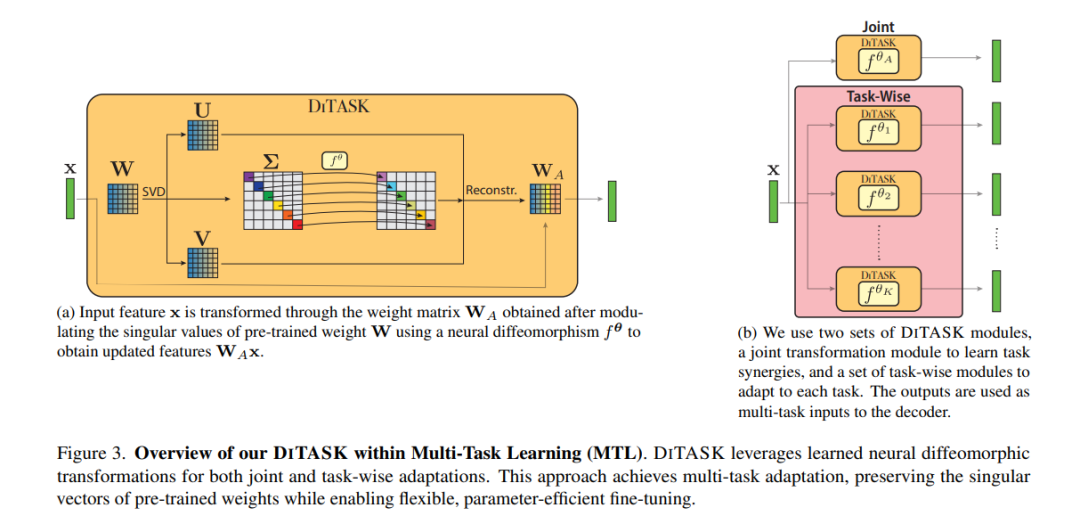
- DITASK:基于微分同胚变换的多任务微调
预训练的视觉Transformer(ViTs)已成为计算机视觉领域的强大工具。然而,如何高效地将其适应于多任务仍然是一个挑战,这源于需要在修改学习到的权重矩阵所编码的丰富隐藏表示的同时,避免任务之间的干扰。当前的高效参数方法(如LoRA)通过低秩更新迫使任务在受限的子空间内竞争,最终导致性能下降。我们提出了DITASK,这是一种新颖的微分同胚多任务微调方法,通过保留权重矩阵的奇异向量来维持预训练表示,同时通过奇异值的神经微分同胚变换实现任务特定的适应。通过这种方法,DITASK能够以最少的额外参数实现共享和任务特定的特征调制。我们的理论分析表明,DITASK在优化过程中实现了全秩更新,保留了预训练特征的几何结构,并为高效多任务学习(MTL)建立了新的范式。在PASCAL MTL和NYUD数据集上的实验表明,DITASK在四个密集预测任务中实现了最先进的性能,且使用的参数比现有方法少75%。我们的代码可在以下链接获取:[此处插入链接]。
- Tora:面向轨迹的扩散Transformer视频生成模型
近年来,扩散Transformer(DiT)在生成高质量视频内容方面展现了卓越的能力。然而,基于Transformer的扩散模型在生成具有可控运动的视频方面的潜力仍未得到充分探索。本文提出了Tora,这是首个面向轨迹的DiT框架,能够同时整合文本、视觉和轨迹条件,从而实现具有有效运动指导的可扩展视频生成。具体而言,Tora由轨迹提取器(TE)、时空DiT和运动指导融合器(MGF)组成。TE通过3D运动压缩网络将任意轨迹编码为分层的时空运动补丁。MGF将这些运动补丁整合到DiT模块中,以生成准确遵循指定轨迹的一致性视频。我们的设计与DiT的可扩展性无缝结合,允许精确控制视频内容的动态特性,包括不同的时长、宽高比和分辨率。大量实验表明,与基础DiT模型相比,Tora在实现高运动保真度方面表现出色,同时能够准确模拟物理世界中的复杂运动。代码已在以下链接公开:https://github.com/alibaba/Tora。