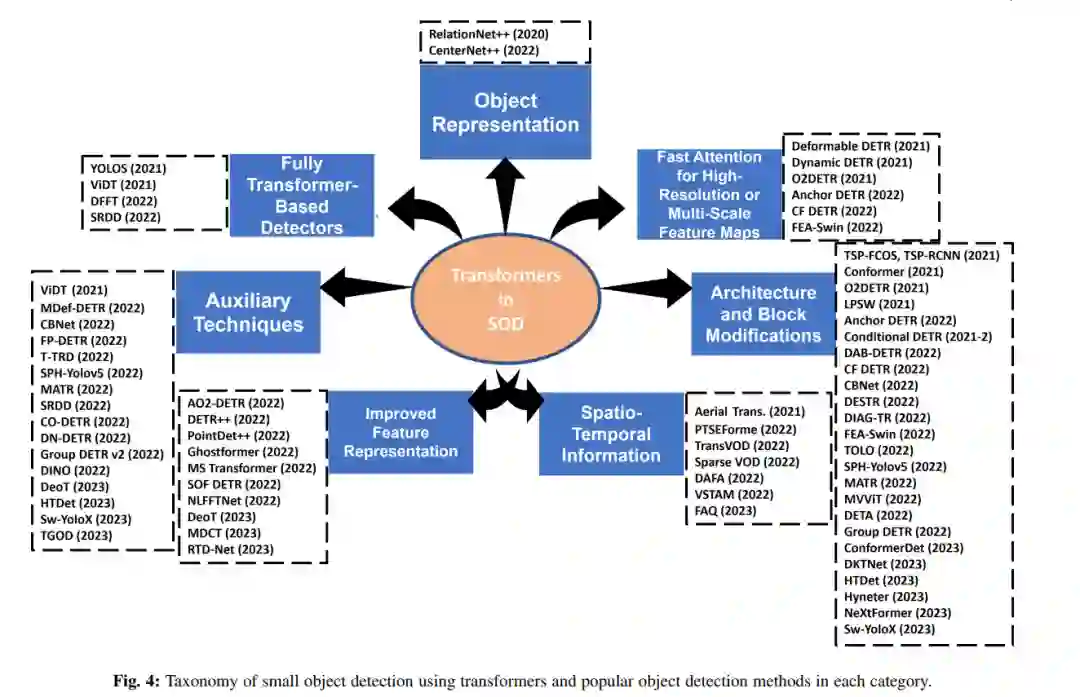
Transformer在计算机视觉领域迅速普及,特别是在目标识别和检测领域。在检查了最先进的目标检测方法的结果后,我们注意到Transformer在几乎每个视频或图像数据集上的表现都优于成熟的基于CNN的检测器。虽然基于Transformer的方法仍然处于小目标检测(SOD)技术的前沿,但本文旨在探索这种广泛的网络提供的性能优势,并确定其SOD优势的潜在原因。由于小目标的低可见性,小目标已被确定为检测框架中最具挑战性的对象类型之一。我们旨在研究可能提高Transformer在SOD中性能的潜在策略。这项综述提出了一个关于已开发的Transformer的SOD任务的60多项研究的分类,跨越2020年至2023年。这些研究涵盖了各种检测应用,包括通用图像、航拍图像、医学图像、主动毫米图像、水下图像和视频中的小目标检测。我们还编译并列出了12个适合SOD的大规模数据集的列表,这些数据集在以前的研究中被忽视了,并使用流行的度量标准(如平均平均精度(mAP)、每秒帧数(FPS)、参数数量等)比较了所评述的研究的性能。

小目标检测(SOD)已被认为是当前最先进的目标检测方法(SOTA)面临的一个重大挑战[1]。“小目标”指的是占据输入图像一小部分的物体。例如,在广泛使用的MS COCO数据集[2]中,它定义了在典型的480 × 640图像中边框为32 × 32像素或更小的物体(图1)。其他数据集也有自己的定义,例如占据图像10%的物体。小目标经常被遗漏或检测到错误的边框,有时还有错误的标签。SOD中定位不足的主要原因是输入图像或视频帧中提供的信息有限,加剧了它们在深度网络中通过多个层时所经历的空间退化。由于小目标经常出现在各种应用领域,如行人检测[3]、医学图像分析[4]、人脸识别[5]、交通标志检测[6]、交通灯检测[7]、船舶检测[8]、基于合成孔径雷达(SAR)的目标检测[9],因此值得研究现代深度学习SOD技术的性能。本文比较了基于Transformer的检测器和基于卷积神经网络(CNN)的检测器在小目标检测方面的性能。在明显优于CNN的情况下,我们试图揭示Transformer强大性能背后的原因。一个直接的解释可能是Transformer对输入图像中成对位置之间的相互作用进行了建模。这是一种有效的上下文编码方式。而且,众所周知,上下文是人类和计算模型检测和识别小目标的主要信息来源[10]。然而,这可能不是解释Transformer成功的唯一因素。具体而言,我们的目标是沿着几个维度分析这种成功,包括对象表示、高分辨率或多尺度特征图的快速注意力、完全基于Transformer的检测、架构和块修改、辅助技术、改进的特征表示和时空信息。此外,我们指出了可能增强Transformer在SOD中性能的方法。
在我们之前的工作中,我们调查了许多在深度学习中使用的策略,以提高光学图像和视频中小目标检测的性能,直至2022年[11]。我们表明,除了适应新的深度学习结构(如Transformer)外,流行的方法包括数据增强、超分辨率、多尺度特征学习、上下文学习、基于注意力的学习、区域建议、损失函数正则化、利用辅助任务和时空特征聚合。此外,我们观察到Transformer是大多数数据集中定位小目标的主要方法之一。然而,鉴于[11]主要评估了超过160篇专注于基于CNN的网络的论文,没有对以Transformer为中心的方法进行深入探索。认识到该领域的增长和探索步伐,现在有一个及时的窗口来深入研究当前面向小目标检测的Transformer模型。本文的目标是全面了解在应用于小目标检测时,变换器令人印象深刻的性能的贡献因素,以及它们与用于通用目标检测的策略的区别。为了奠定基础,我们首先强调了著名的基于Transformer的SOD目标检测器,并将其与基于CNN的方法的进步进行比较。
自2017年以来,该领域已经发表了许多综述文章。在我们之前的调查中[11],对这些综述进行了广泛的讨论和列表。最近的另一篇调查文章[12]也主要关注基于CNN的技术。当前调查的叙述与前人截然不同。本文的重点是将焦点具体缩小到Transformer上——这是以前没有探讨过的一个方面——将Transformer定位为图像和视频SOD的主要网络架构。这需要为这种创新架构量身定制一个独特的分类法,有意识地将基于CNN的方法边缘化。鉴于这个主题的新颖性和复杂性,我们的综述主要将2022年后的工作优先考虑。此外,我们还阐明了在更广泛的应用领域中用于小目标定位和检测的新数据集。本调查中研究的主要方法是为小目标定位和分类量身定制的方法,或间接解决了SOD的挑战。驱动我们分析的是这些论文中针对小目标的检测结果。然而,早期的研究指出了SOD的结果,但要么证明了低于标准的性能,要么忽略了开发方法中特定的SOD参数,因此没有考虑纳入本综述。在本调查中,我们假设读者已经熟悉通用对象检测技术、它们的架构和相关的性能指标。如果读者需要对这些领域有基础的了解,我们建议读者参考我们以前的工作[11]。
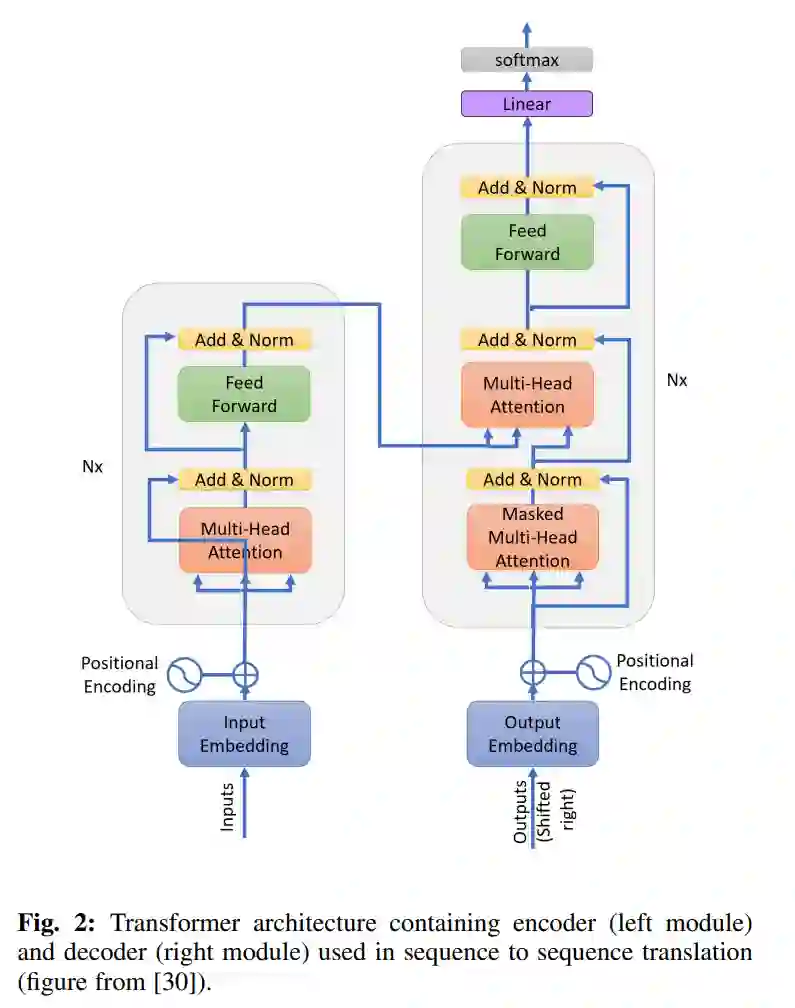
本文的结构如下:第2节概述了基于CNN的物体检测器、Transformer及其组件,包括编码器和解码器。本节还涉及了基于Transformer的物体检测器的两个初始迭代:DETR和ViT-FRCNN。在第3节中,我们对基于Transformer的SOD技术进行了分类,并全面深入研究了每类技术。第4节展示了用于SOD的不同数据集,并在一系列应用中对它们进行了评估。在第5节中,我们分析并比较了这些结果与早期从CNN网络得出的结果。本文在第6节中总结了结论。