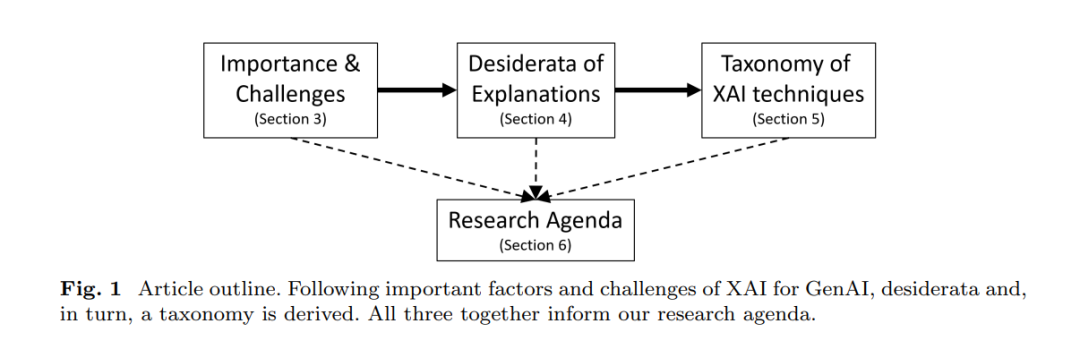
生成人工智能(GenAI)标志着人工智能从“识别”能力转变为能够为广泛任务“生成”解决方案的能力。随着生成的解决方案和应用变得日益复杂和多面,解释性(XAI)的新需求、目标和可能性也随之涌现。在本工作中,我们详细讨论了随着GenAI兴起,XAI为何变得重要及其对解释性研究的挑战。我们还揭示了解释应满足的新兴和出现的期望,例如涵盖可验证性、互动性、安全性和成本方面。为此,我们专注于综述现有工作。此外,我们提供了一个相关维度的分类体系,使我们能更好地描述现有的XAI机制和GenAI的方法。我们讨论了从训练数据到提示的不同途径以确保XAI。我们的论文为非技术读者提供了简短但精确的GenAI技术背景,重点介绍文本和图像以更好地理解为GenAI新颖或调整的XAI技术。然而,由于关于GenAI的作品众多,我们决定忽略与评估和使用解释相关的XAI的详细方面。因此,该手稿既适合技术导向的人员,也适合其他学科,如社会科学家和信息系统研究者。我们的研究路线图提供了超过十个未来调查的方向。
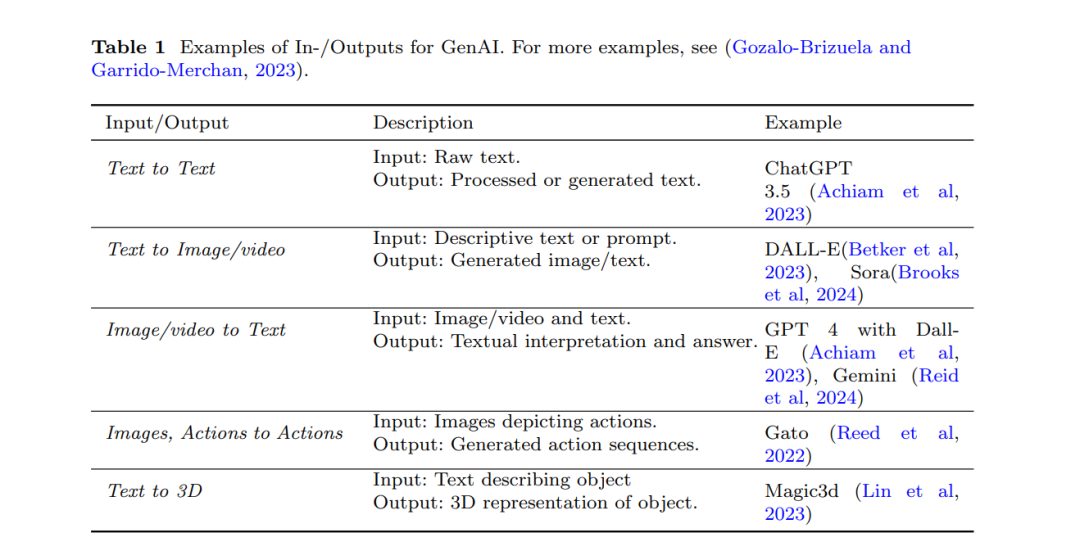
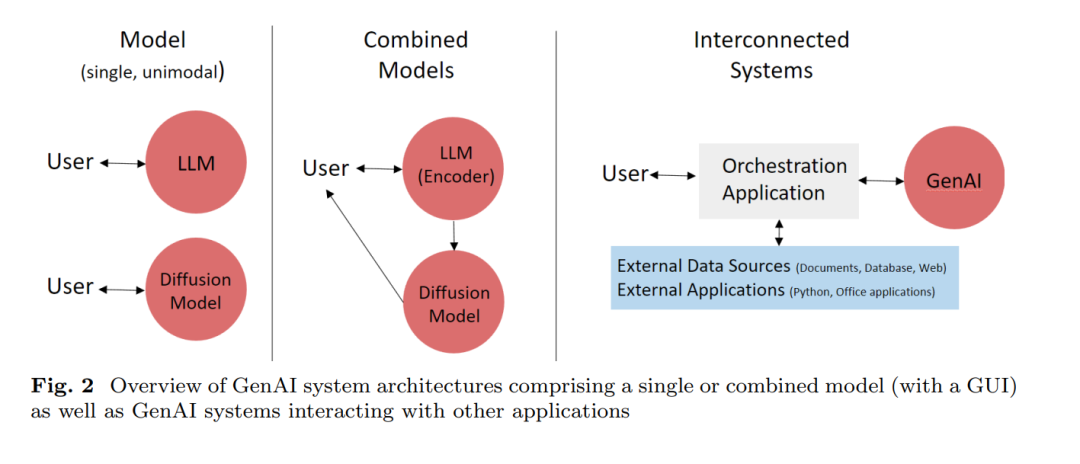
生成人工智能(GenAI)展示了引起全球广泛关注的显著能力,涉及多个领域——从监管机构(欧洲联盟,2023年),教育工作者(Baidoo-Anu和Ansah,2023年),程序员(Sobania等人,2023年)到医疗人员(Thirunavukarasu等人,2023年)。对于企业(Porter,2023年),GenAI有潜力每年解锁数万亿美元的价值(麦肯锡公司,2023年)。同时,它也被认为是对人类的威胁(《卫报》,2023年)。这些相反的观点是理解和解释GenAI的关键动力。生成人工智能代表了由基础模型驱动的AI的下一个层次(Schneider等人,2024b),AI能够创造文本、图像、音频、3D解决方案和视频(Gozalo-Brizuela和Garrido-Merchan,2023年;Cao等人,2023年),可以通过文本提示(White等人,2023年)由人类控制——参见表1,了解公共GenAI系统的示例。这是AI从主要能“识别”到能“生成”的重大进步。GenAI展示了前所未有的能力,如通过大学级考试(Choi等人,2021年;Katz等人,2024年)。它在被认为不适合机器的领域也取得了显著的成果,例如创造力(Chen等人,2023a)。它对每个人都是可访问的,如商业系统ChatGPT(Achiam等人,2023年)和Dall-E(Betker等人,2023年;Ramesh等人,2022年)所示。早期的生成人工智能方法,如生成对抗网络(GANs),也能生成作品,但通常比现代模型如变压器和扩散架构更难以控制。 对于GenAI的可解释人工智能(GenXAI)技术能够生成帮助理解AI的解释,例如针对单个输入或整个模型的输出。传统上,解释由于多种需求而服务于多种目的;例如,它们可以增加信任并支持模型的调试(Meske等人,2022年)。对AI的理解需求在前GenAI时代更为广泛。例如,解释可以支持生成内容的可验证性,从而有助于解决GenAI的主要问题之一:幻觉(如第3.1节所论述)。不幸的是,尽管过去几年试图设计解决方案来解决这些问题,可解释人工智能(即使是前GenAI模型)仍然存在一些尚未解决的问题(Longo等人,2024年;Meske等人,2022年)。例如,最近一项关于XAI对人机交互影响的方法比较(Silva等人,2023年)发现,最好的方法(反事实)和最差的方法(仅使用概率分数)之间的得分差距仅为20%,这暗示复杂的现有方法与更复杂的方法相比优势有限。因此,XAI技术距离最佳状态仍有很大差距。其他工作甚至公开称解释性研究的“现状大体上是无效的”(R¨auker等人,2023年)。因此,还有很多工作要做,了解当前的努力并在此基础上进行改进是至关重要的——尤其是在减少高风险(《卫报》,2023年)的同时利用机会(Schneider等人,2024b)。 这篇研究手稿是朝这个方向进展的真诚尝试。我们的目标不仅是(仅)列出和结构现有的XAI技术,因为在当前领域阶段,需要解决更基本的问题,如识别GenXAI的关键挑战和期望。为此,我们因此选择了更多叙述性的审查方法(King和He,2005年)并伴随着来自信息系统领域的分类发展方法(Nickerson等人,2013年)。已有多篇关于XAI的综述关注前GenAI时代,主要是技术焦点(Adadi和Berrada,2018年;Zini和Awad,2022年;Dwivedi等人,2023年;Schwalbe和Finzel,2023年;R¨auker等人,2023年;Saeed和Omlin,2023年;Speith,2022年;Minh等人,2022年;Bodria等人,2023年;Theissler等人,2022年;Guidotti等人,2019年;Guidotti,2022年)和跨学科或社会科学焦点(Miller,2019年;Meske等人,2022年;Longo等人,2024年)。特别是,通过利用这些综述,我们进行了一项元综述来构建我们的方法,同时也借鉴了前GenAI的知识。然而,我们也揭示了与GenAI相关的尚未涵盖的新方面。许多综述调查了GenAI的各个方面(不包括XAI)(Xu等人,2023年;Lin等人,2022年;Xing等人,2023年;Yang等人,2023b;Zhang等人,2023a,c;Pan等人,2023年)。我们利用这些综述为我们的技术背景。GenAI的某些子领域,例如知识识别和编辑(Zhang等人,2024年),使用孤立的XAI技术作为工具,但不旨在一般性地详细论述它。虽然我们未能识别任何讨论GenAI的XAI的综述,但一些研究手稿对大型语言模型(LLM)的XAI采取了更全面、部分带有观点的观点(Singh等人,2024年;Liao和Vaughan,2023年)或显式综述LLM的XAI(Zhao等人,2023a;Luo和Specia,2024年)。以前的工作没有提供一份全面的GenAI XAI的期望、动机和挑战清单和分类。特别是,我们的许多新方面在之前的工作中找不到。除此之外,即使只关注LLM,我们与以前的工作也有相当大的不同。 我们首先提供技术背景。 为了推导出贡猩,我们按照图1所述进行:然后,我们提供了GenAI的XAI的动机和挑战,尤其指向GenAI带来的新方面,如GenAI在整个社会的广泛影响和用户需要交互调整通常复杂、难以评估的输出的需求。基于此,我们推导出期望,即解释应 ideally fulfill的要求,如支持互动和验证输出。然后,我们为GenAI的现有和未来的XAI技术推导出一个分类,为了分类XAI,我们使用与GenXAI技术的输入、输出和内部属性相关的维度,这些维度将它们与前GenAI区分开来,例如自我解释以及不同的来源和XAI的驱动因素,例如提示和训练数据。 使用识别的挑战和期望,本手稿的其余部分专注于讨论GenXAI的新维度和 RESULTING TAXONOMY,讨论与GenAI相关的XAI方法。最后,我们提供未来的方向 我们的关键贡献包括描述GenAI的XAI需求、解释的期望和包括新维度的机制和算法的分类。