来自清华大学的韩旭博士论文,入选2022年度“CCF优秀博士学位论文奖”初评名单!
https://www.ccf.org.cn/Focus/2022-12-08/781244.shtml
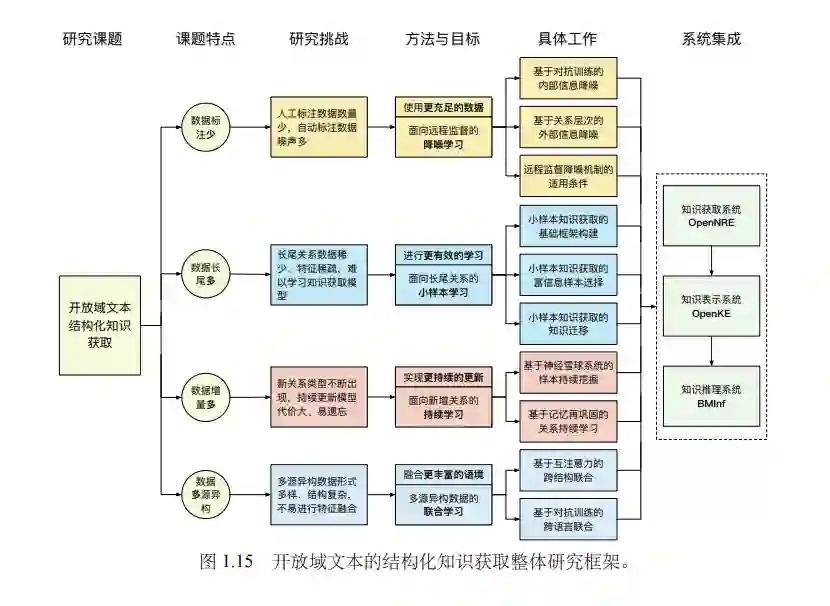
知识图谱以结构化符号系统组织人类知识,是推动人工智能发展、支撑智能 服务应用的基础技术。相比于现实世界中的海量知识,已有知识图谱距离完善仍 有较大距离。开放域文本规模大、形式多、内容丰富,从开放域文本中自动获取结 构化知识,是扩充知识图谱的有效手段。本文面向开放域文本结构化知识获取中 “一少三多” 四大挑战,即标注数据少、长尾数据多、增量数据多、数据多源异构, 进行了四方面工作:
(1)面向远程监督的降噪学习,包括:基于内部信息的远程监督降噪,利用对 抗训练挖掘数据内部信息来过滤远程监督自动标注数据中的噪声样本;基于外部 信息的远程监督降噪,利用实体间关系的层次结构作为外部信息来从自动标注数 据中选择高质量样本;远程监督降噪的适用条件分析,系统评测各类远程监督降 噪算法,剖析各类降噪机制的适用条件。 (2)面向长尾关系的小样本学习,包括:小样本知识获取的框架构建,基于元 学习与度量学习构建针对知识获取的小样本学习框架;小样本知识获取的富信息 样本选择,基于混合注意力机制选择富信息样本来强化小样本学习能力;小样本 知识获取的知识迁移,基于预训练语言模型学习无标注数据来缓解样本不足。
(3)面向新增关系的持续学习,包括:知识获取的样本持续挖掘,基于神经雪 球系统持续挖掘开放域文本中适于训练知识获取模型的样本;知识获取的模型持 续学习,基于记忆再巩固进行开放域文本上实体间新关系的持续学习,规避灾难 性遗忘问题。
(4)多源异构数据的联合学习,包括:联合跨结构信息的知识获取,基于互注 意力进行非结构化文本与结构化知识图谱的跨结构联合;联合跨语言信息的知识 获取,基于对抗训练在统一语义空间中进行多语言文本的跨语言联合;联合文本 与规则的知识获取,基于预训练语言模型提示微调进行文本与逻辑规则的联合。
基于上述四方面工作,本文形成了开放域文本的结构化知识获取算法体系。围 绕该算法体系,本文也将从工程实现角度出发,介绍如何构建高效的知识应用系 统。上述算法与系统有利于进一步丰富知识图谱的知识规模,促进当前数据驱动 的深度学习善于刻画特征以及符号表示的结构化知识善于认知推理的双重优势结 合,对于揭示自然语言处理机理、实现智能语言理解具有重要意义。