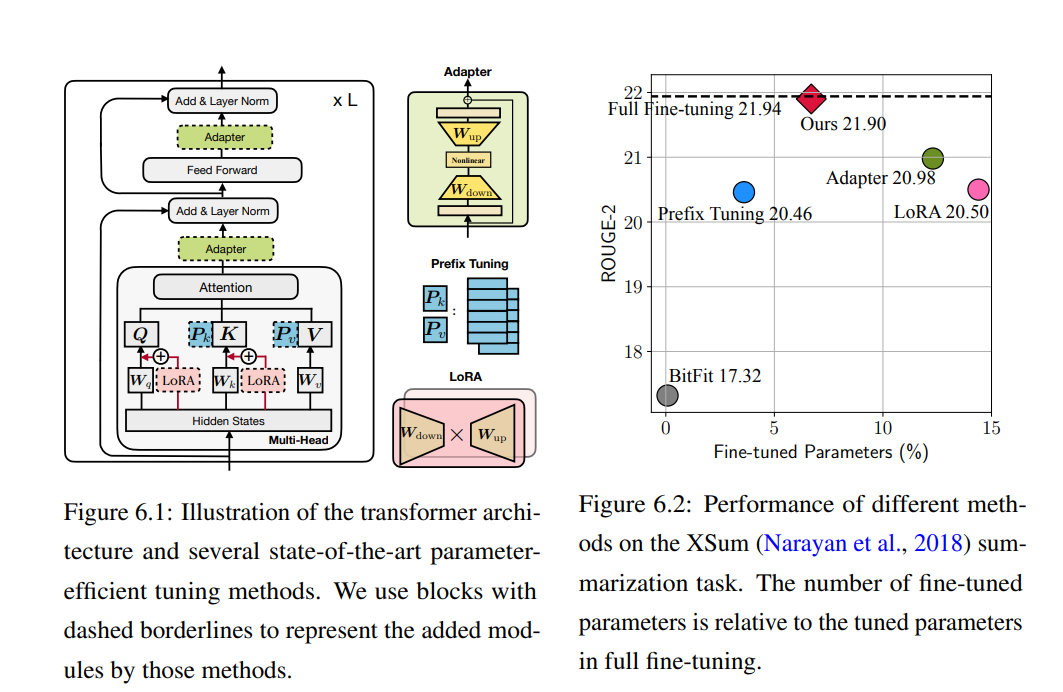
**自然语言生成(NLG)已经从深度学习技术的发展中取得了显著的成功。随着大规模的预训练成为NLP中事实上的标准,大量的训练数据和模型参数始终能够在标准NLG任务中获得最先进的性能。**虽然相当成功,但目前的NLG方法在几个方面都是低效的,这阻碍了它们在更广泛和实际的环境中的使用:(1)它们是标签低效的-条件神经生成(例如机器翻译)通常需要大量的注释样本来训练,这限制了它们在低资源环境中的应用;(2)它们的参数效率不高——通常的做法是对预训练的模型进行微调,使其适应下游任务,然而,这些模型可以扩展到数万亿的参数(Fedus等人,2021年),这将在服务大量任务时造成大量的内存占用;(3)最后,我们重点研究了趋势模型类——检索增强NLG模型的计算效率低下问题。它们从外部数据存储中检索以辅助生成,由于额外的计算,添加的数据存储和检索过程会引起不小的空间和时间成本。
**本文旨在对高效NLG的研究问题有更深入的理解,并利用这些见解来设计更好的方法。**具体来说,(1)在标签效率方面,研究了无监督和半监督的条件生成,利用丰富的无标签文本数据,从而减轻了对大量标注样本的需求。所提出的方法在各种NLG任务上进行了验证;(2)在参数效率方面,本文提出了一个统一的框架来连接参数高效的迁移学习,其中只需要更新少数参数,就可以使大型预训练模型适应下游任务。所提出框架为这一方向提供了新的理解,以及为参数高效的NLG实例化最先进的方法;(3)对于检索增强NLG的计算效率,我们设计了新的模型或后适应检索组件,以压缩数据存储,减少检索计算,并加快推理。 语言是人类交流的主要媒介。在人工智能中,语言是机器与人交流的主要接口之一,因此机器需要能够理解并生成自然语言。本文重点研究后者,即自然语言生成。自然语言生成是最基本的范畴之一的任务在NLP,横跨在机器翻译(Bahdanau et al ., 2015),文本摘要(Rush et al ., 2015),对话生成(Sordoni et al ., 2015),数据描述(Novikova et al ., 2017),等等。随着近年来深度学习在NLP领域的快速发展(Hochreiter and Schmidhuber, 1997;Bahdanau等人,2015;Vaswani et al., 2017),我们已经见证了这些任务的巨大进展。特别是大规模的自监督预训练(Peters等人,2018;Devlin等人,2019a;)将NLG任务的性能提升到了一个新的水平(Lewis等人,2020a;Raffel等人,2020)。最近,越来越大的预训练语言模型显示出了将所有NLP任务作为生成任务处理的潜力,在适当的文本提示下实现有竞争力的零次或少次结果(Radford et al., 2019; Brown et al., 2020; Schick and Schütze, 2021c; Du et al., 2021; Liu et al., 2021a; Sanh et al., 2022)。尽管取得了巨大的成功,但目前的NLG方法在许多方面都是低效的,这阻止了它们在更广泛的环境中使用。在本文中,我们考虑了以下三个方面的低效率。
标签低效: 最先进的自然语言生成模型通常是深度编码器-解码器或仅解码器的神经网络,通常由自注意力transformer架构提供动力(Vaswani等人,2017)。这些模型以端到端的方式在具有交叉熵损失的并行示例上进行训练。模型训练需要大量的标注样本才能达到合理的性能。例如,翻译系统通常用数百万个句子对进行训练,以达到实际性能(Akhbardeh等人,2021);流行的文本摘要基准也由数十万个并行示例组成(Hermann等人,2015;Narayan等人,2018)。然而,带标签的示例通常是稀缺资源——丰富的注释只存在于某些领域。此外,目前大多数数据集都是以英语为中心的,而世界上有7000多种语言,这意味着大多数语言的任务标签都不容易获得。这对应用通用的深度NLG模型提出了挑战。
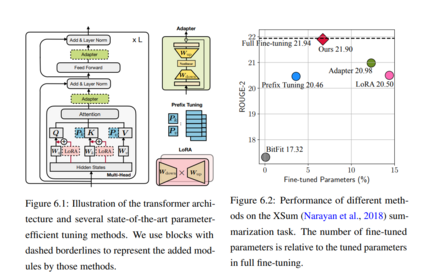
**参数低效:**自监督预训练技术已在各种NLP任务上取得了巨大成功(Peters等人,2018;Devlin等人,2019a;Liu等人,2019a;Yang等人,2019)。通常,模型首先只在自监督损失的情况下对原始文本进行预训练,然后在带有标记数据的下游任务上对预训练模型进行微调。这样的管道已经成为当今创建最先进的NLG系统的事实标准。在这个方向上,研究人员正在追求越来越强大的预训练模型,这实际上在大多数情况下导致了更多的参数——越来越大的语言模型由数亿到万亿参数组成(Brown et al., 2020;Fedus等人,2021;Rae等人,2021)。这样,每个单独的微调过程都会获得巨大模型的不同副本,导致微调和推理时的参数利用率低下。当服务于大量任务时,这种参数低效会导致大量内存占用。
本文提出了一系列方法来提高自然语言生成的效率,从而可以在不显著增加资源需求的情况下创建更好的NLG系统。首先描述了如何利用无标记样本来帮助改善无监督或半监督文本生成(第一部分),然后提出了一个参数高效迁移学习(PETL)的统一框架和伴随的最先进的PETL方法(第二部分)。PETL方法旨在微调冻结的大型模型的一小部分参数,以实现与完全微调相当的性能,从而提高参数效率。最后,我们关注通过减少数据存储大小和加快检索过程,在空间和时间上简化检索增强方法(第三部分)。