最近,高度成功但不透明的机器学习模型激增,这引发了对可解释性的迫切需求。该毕业论文通过新颖的定义、方法和科学综述解决了可解释性问题,确保可解释性在现实问题的背景下是有用的。我们首先定义什么是可解释性,以及围绕它的一些需求,强调语境的作用被低估。然后,我们深入研究解释/改进神经网络模型的新方法,专注于如何最好地评分、使用和提取交互。接下来,我们将从神经网络转向相对简单的基于规则的模型,研究如何在维护极其简洁的模型的同时提高预测性能。最后,我们总结了促进可解释数据科学的开源软件和数据的工作。在每个案例中,我们深入到一个特定的背景,这激发了所提出的方法论,从宇宙学到细胞生物学到医学。所有代码都可以在github.com/csinva上找到。
本论文工作
机器学习模型最近因其准确预测各种复杂现象的能力而受到相当大的关注。然而,人们越来越认识到,除了预测之外,这些模型还能够产生关于数据中包含的领域关系的有用信息(即解释)。更准确地说,可解释机器学习可以定义为“从机器学习模型中提取有关数据中包含的关系或该模型学习到的关系的相关知识”186。解释有其自身的用途,如医学[153]、科学[13,278]和决策[37],以及审计预测本身,以应对监管压力[97]和公平[74]等问题。在这些领域中,解释已被证明有助于评估学习模型,提供修复模型的信息(如果需要),并与领域专家[47]建立信任。然而,随着可解释技术的爆炸式增长[186,193,291,273,90,11,300,100],可解释方法在实践中的使用引起了相当大的关注[4]。此外,我们还不清楚如何在现实环境中评估可解释技术,以促进我们对特定问题的理解。
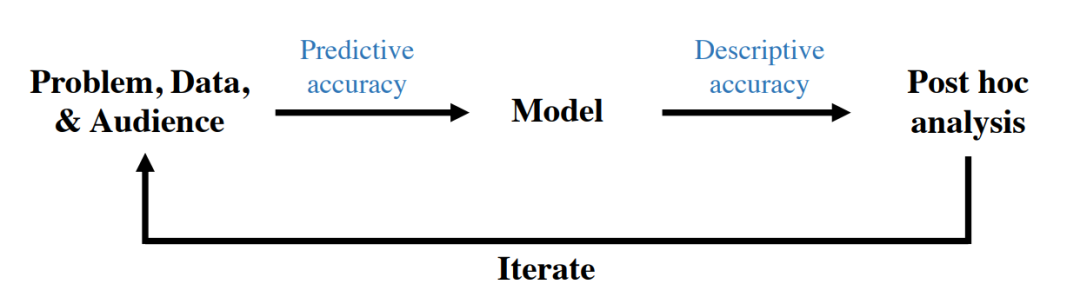
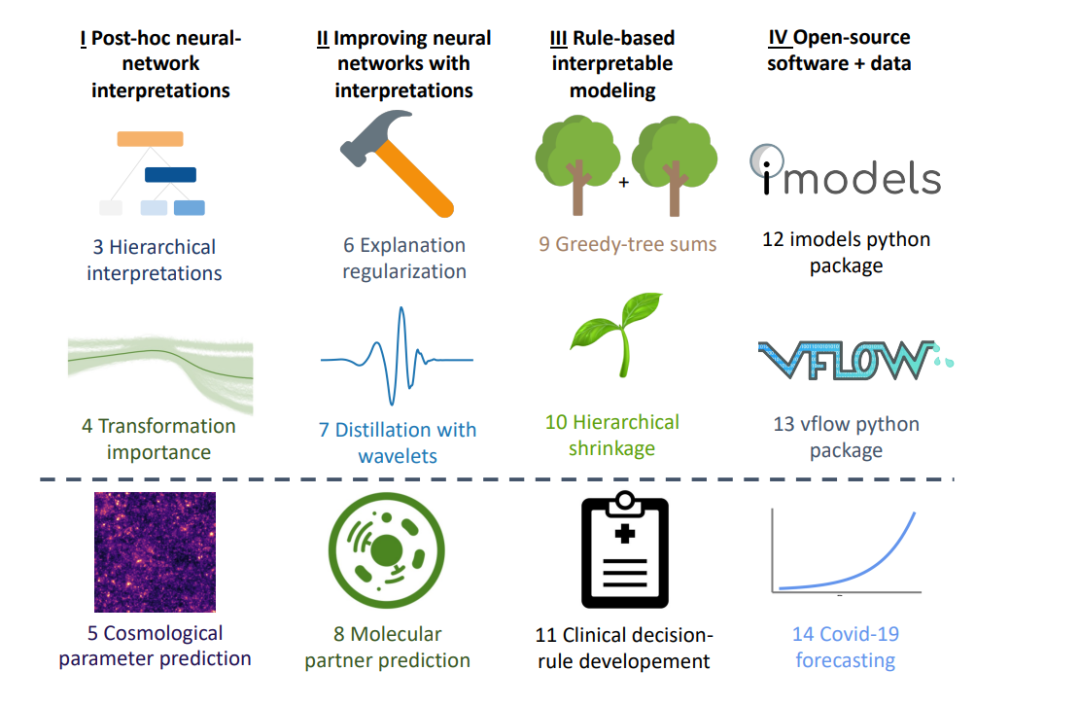
概述数据科学生命周期的不同阶段,其中可解释性很重要。 为此,我们首先回顾了2019年PNAS论文[186](与Jamie Murdoch、Reza Abbasi-Asl、Karl Kumbier和Bin Yu合著)之后对可解释性的一些要求。然后我们讨论了一些批判性评价解释的方法。然后,我们阐述了新的方法,以解决机器学习模型的可解释性的差距。至关重要的是,这种方法是在现实世界问题的背景下与领域专家一起开发和评估的。这项工作跨越了不同的层次,试图从黑盒模型中提取洞察力,并尽可能用更简单的模型替换它们。图1.1显示了本文的概述,旨在解决严格基于现实问题的可解释性问题。第一部分从解释神经网络事后解释的不同方法开始。这些方法使理解神经网络中不同特征之间的相互作用成为可能,并以宇宙学参数预测为背景(第5章)。第二部分接着展示了如何使用这些解释方法直接改善神经网络。要么通过正则化(第6章),要么通过蒸馏(第7章)。这在分子伙伴预测(第8章)的背景下得到了展示。接下来,第三部分介绍了用于构建高度预测的基于规则的模型的改进方法,这些模型非常简洁,基于临床决策规则开发问题。最后,第四部分介绍了新的开源软件和不可解读建模数据。
第一部分: 事后神经网络解释
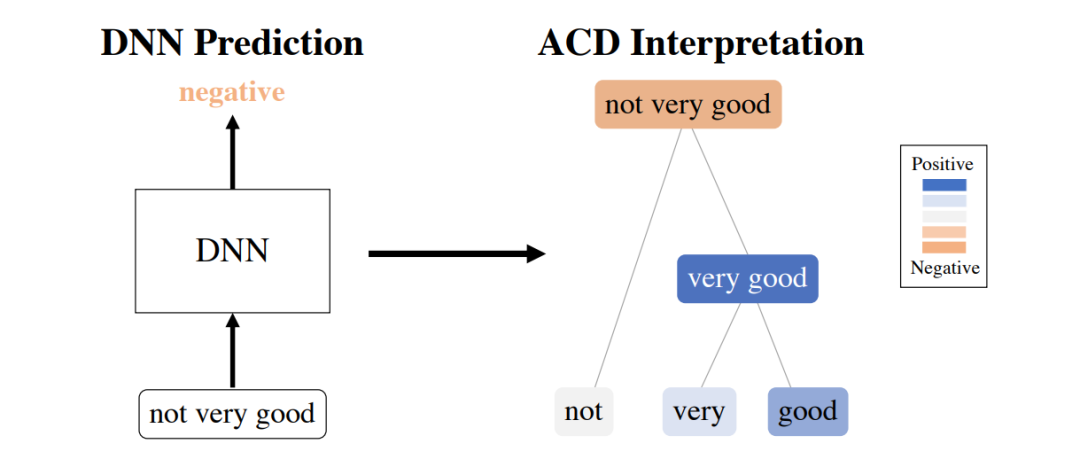
之前的大量工作集中于为单个特征分配重要性,如图像中的像素或文档中的单词。对于不同的体系结构,有几种方法产生了特征级的重要性。它们可以分为基于梯度的[255,264,240,18]、基于分解的[185,242,17]和其他的[59,83,218,303],方法之间有许多相似之处[10,159]。虽然已经开发了许多方法来将重要性归因于模型输入的单个特征,但用于理解关键特征之间的交互作用的工作相对较少。这些交互是解释现代深度学习模型的关键部分,因为它们使结构化数据具有强大的预测性能。第一部分介绍了最近开发的两种方法,用于提取(已经训练过的)DNN已经学习到的特征之间的交互。第3章介绍了聚集上下文分解(ACD),它通过贪婪地打分和组合组级重要性来生成层次重要性。这使得简单有效地可视化哪些特性对单个预测是重要的。第4章介绍了转换重要性(TRIM),它允许计算模型输入转换交互的分数。这两种方法都可以更好地理解宇宙参数预测(第5章),其中的可解释性允许人们在将模型应用于真实天文数据时相信模型的预测。
第二部分: 利用解释改进神经网络
在第一部分中介绍了解释交互和转换的方法之后,第二部分介绍了使用这些属性直接改进模型的两种方法。在引入和评估解释方法时,这是一个重要且经常被忽略的步骤,它有助于用直接的用例来建立解释的效用。

第三部分: 基于规则的可解释建模
本节将完全脱离深度学习,而将重点放在基于规则的建模上。只要有可能,首先拟合一个简单的模型比拟合一个复杂的模型,然后用事后的解释来检查它更可取。一个足够简单的基于规则的模型可以被完全理解,并且很容易用手模拟、记忆和推理反事实。
第四部分:开源软件与数据
在数据科学和机器学习领域,好的开源软件和数据存储库与好的想法一样有用(如果不是更有用的话)。这一部分涵盖了上述研究中产生的两个python包,以及一个为开源建模而策划的数据存储库。