

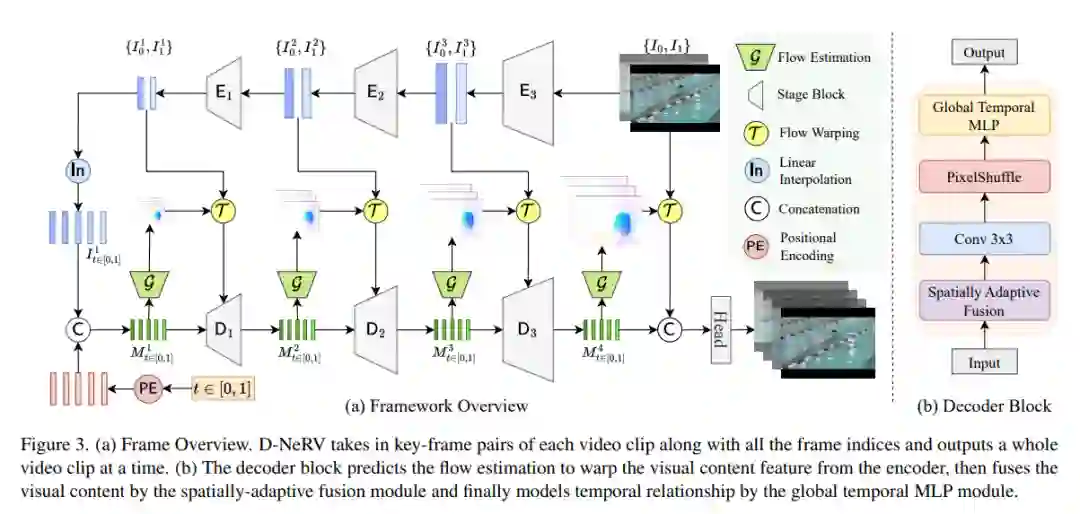
隐神经表示(INR)在表示3D场景和图像方面得到了越来越多的关注,最近被应用于视频编码(如NeRV [1], E-NeRV[2])。虽然取得了很好的结果,但现有的基于INR的方法仅限于编码少量具有冗余视觉内容的短视频(例如UVG数据集中的7个5秒视频),导致模型设计独立适合单个视频帧,不能有效地扩展到大量不同的视频。**本文专注于开发用于更实际设置的神经表示——对具有不同视觉内容的长视频和/或大量视频进行编码。**不是将视频划分为小的子集并用单独的模型进行编码,而是用统一的模型对长而多样的视频进行联合编码,以取得更好的压缩效果。基于这种观察,本文提出D-NeRV,一种新的神经表示框架,通过(i)将特定片段的视觉内容与运动信息解耦,(ii)在隐式神经网络中引入时间推理,以及(iii)采用面向任务的流作为中间输出,以减少空间冗余,来编码各种视频。在视频压缩任务上,新模型在UCF101和UVG数据集上很大程度上超过了NeRV和传统的视频压缩技术。此外,当用作高效的数据加载器时,D-NeRV在UCF101数据集上的动作识别任务中,在相同的压缩比下,比NeRV提高了3%- 10%的准确率。 https://www.zhuanzhi.ai/paper/d760654c1ffaca3eb81e4d8c4bd965d0
成为VIP会员查看完整内容
相关内容

CVPR 2023大会将于 6 月 18 日至 22 日在温哥华会议中心举行。CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议,会议的主要内容是计算机视觉与模式识别技术。
CVPR 2023 共收到 9155 份提交,比去年增加了 12%,创下新纪录,今年接收了 2360 篇论文,接收率为 25.78%。作为对比,去年有 8100 多篇有效投稿,大会接收了 2067 篇,接收率为 25%。
Arxiv
0+阅读 · 2023年5月12日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年5月12日