本文综述了近年来发展起来的多模态智能视觉语言预训练(VLP)方法。我们将这些方法分为三类: (i) 用于图像-文本任务的VLP,如图像标题、图像-文本检索、视觉问题回答和视觉基础; (ii) 用于核心计算机视觉任务的VLP,如(开集)图像分类、目标检测和分割;以及 (iii) 视频文本任务的VLP,如视频字幕、视频文本检索和视频问答。对于每个类别,都对最先进的方法进行了全面的回顾,并使用特定的系统和模型作为案例研究,讨论已经取得的进展和仍然面临的挑战。对于每个类别,讨论了研究界正在积极探索的高级主题,如大基础模型、统一建模、上下文内少样本学习、知识、鲁棒性和现实中的计算机视觉等。
人类通过许多渠道感知世界,比如通过眼睛看到的图像,或通过耳朵听到的声音。尽管任何单独的通道都可能是不完整的或有噪声的,但为了更好地理解世界,人类可以自然地对齐和融合从多个通道收集到的信息。人工智能的核心目标之一是开发一种算法,使计算机能够有效地从多模态(或多通道)数据中学习。这些数据类似于通过视觉和语言获得的视觉和声音,帮助人类理解周围的世界。例如,计算机可以通过搜索与文本查询最相关的图像(或反之),以及使用自然语言描述图像的内容来模仿这种能力。视觉与语言(VL),一个位于计算机视觉和自然语言处理(NLP)之间的热门研究领域,旨在实现这一目标。受语言模型预训练在自然语言处理中的巨大成功(例如BERT (Devlin et al.,2019)、RoBERTa (Liu et al.,2019d)、T5 (Rafael et al.,2020)和GPT-3 (Brown et al.,2020)的启发,视觉语言预训练(VLP)最近在两个群体中引起了迅速增长的关注。随着学习通用可转移的视觉和视觉语言表示的希望,VLP已成为现代视觉语言研究的一个日益重要的训练范式。最近,有一些关于VLP的相关调研论文。Zhang等人(2020a)关注的是预训练时代之前的任务特定VL方法,并对VLP模型进行了简明的讨论。Du等人(2022);Li等人(2022e)关注的是VLP,但主要是图像-文本任务,没有涉及视频-文本任务。Ruan和Jin(2022)专注于视频-文本任务的VLP。Chen等人(2022a)回顾了用于图像-文本和视频-文本任务的VLP方法。然而,讨论并不深入。本文的贡献总结如下。
-
我们对现代VLP进行了全面的综述,不仅涵盖了它在传统图像-文本和视频-文本任务中的成功应用(例如,图像/视频字幕、检索和问题回答),还展示了它在核心计算机视觉任务(例如,图像分类、目标检测和分割)中的巨大潜力。
-
我们对VLP前沿的高级主题进行深入讨论,从大基础模型、统一建模、上下文少样本学习、知识增强VLP、多语言VLP、模型鲁棒性、模型压缩,到开放计算机视觉。
-
我们描绘了研究社区开发并向公众发布的VL系统的景观,通过案例研究展示了我们所取得的进展和我们所面临的挑战。
本文基于我们的CVPR 2022教程,以计算机视觉和NLP社区的研究人员作为我们的主要目标受众。它详细介绍了理解现代VLP方法所需的重要思想和见解,并为对VL表示学习的大规模预训练及其在计算机视觉和多模态任务中的应用感兴趣的学生、研究人员、工程师和从业人员提供了宝贵的资源。
本文的结构如下。
- 第一章介绍了VL研究的概况,并对VL研究从任务具体方法到大规模预训练的转变进行了历史回顾。
- 第二章介绍了早期针对特定任务的VL方法,用于可视化问题回答、图像字幕和图像文本检索,这是理解现代VLP方法的基础。
- 第三章描述了图像文本任务的VLP方法,如图像字幕、图像文本检索、视觉问答和视觉接地。
- 第四章描述了计算机视觉核心任务的VLP方法,包括(开放词汇)图像分类、目标检测和分割。
- 第五章描述了视频文本任务中的VLP方法,如视频字幕、视频文本检索和视频问答。
- 第六章简要回顾了工业中开发的VL系统以及在现实环境中部署这些VL系统的挑战。
- 第七章对全文进行总结,并对研究趋势进行了讨论。
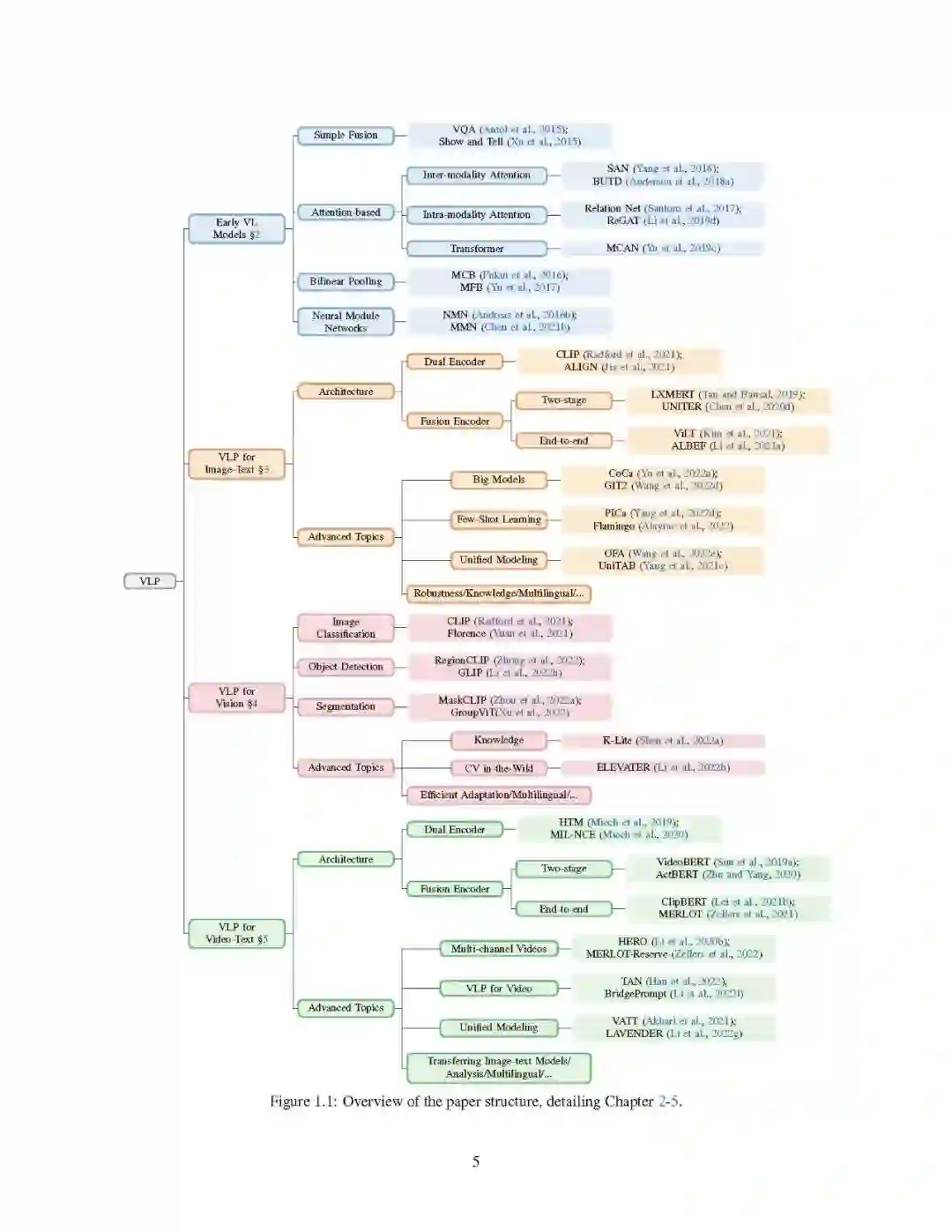
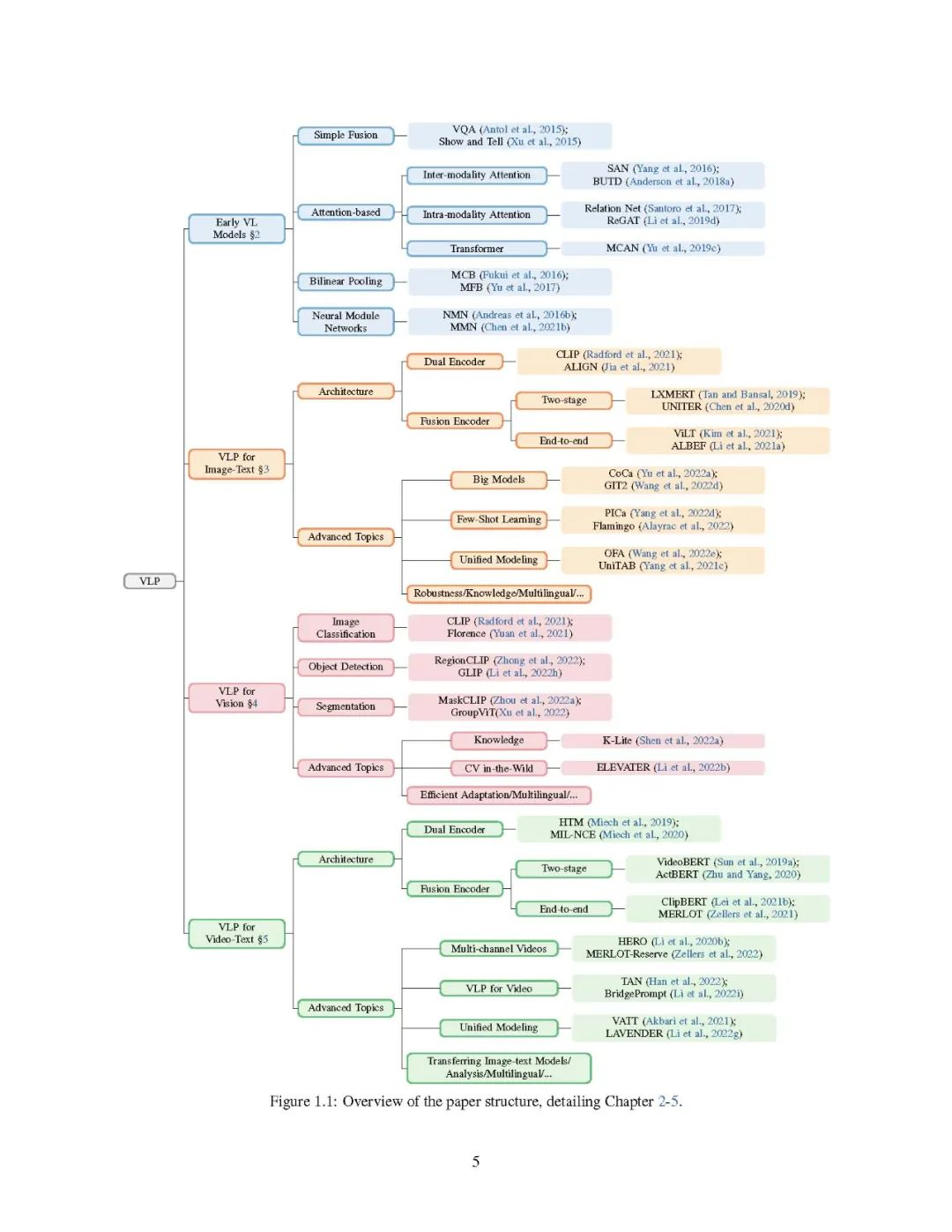
第2-5章是本文的核心章节。这些章节的结构概览见图1.1。由于VLP的浪潮始于图像文本任务,我们首先对从早期的任务特定方法(第2章)到最新的具有图像文本输入的VLP方法(第3章)的过渡进行了全面回顾。在第4章中,我们讨论了如何将核心计算机视觉任务视为具有开放词汇表预测的图像-文本任务,在经过对比预先训练的图像-文本模型(如CLIP (Radford et al,2021年))的支持下,并进一步使计算机视觉在荒野中实现(Li et al,2022b)。将图像-文本任务扩展到更多的模式,我们在第5章中介绍了VLP方法如何通过视频-文本输入服务于更多的应用。 我们生活在一个多模态的世界里,我们的大脑自然地学会处理从环境中接收到的多感官信号,以帮助我们理解周围的世界。更具体地说,视觉是人类感知的很大一部分,而语言是人类交流的很大一部分。根据其定义,一个多模态AI系统应该具有有效和高效处理这种多模态信号的能力。在不断增长的VL研究文献中,本文将VL问题分为三类,具体如下:
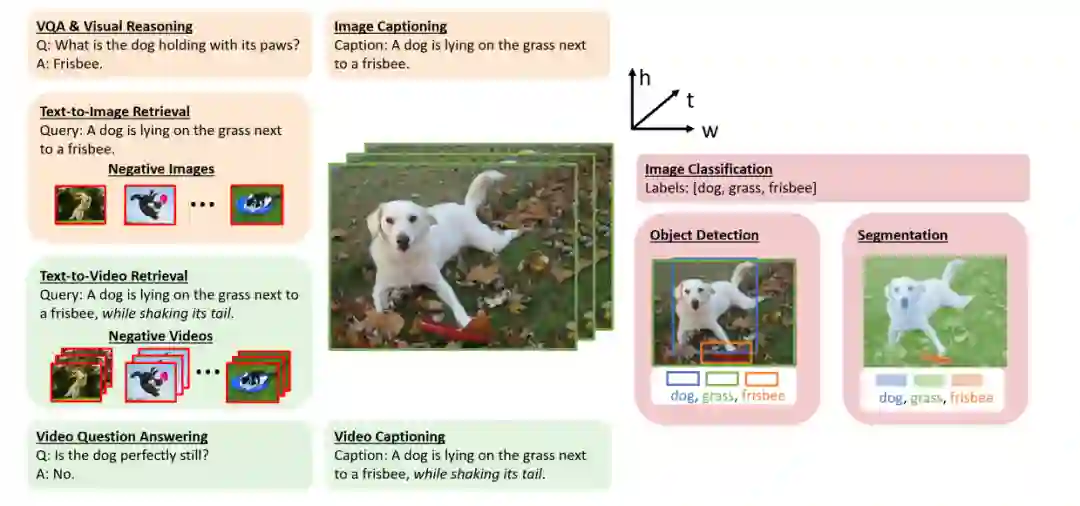
- 图像-文字任务。可以说,VL研究中最重要和研究最充分的任务是图像文本检索、图像标题(Vinyals等人,2015年)和视觉问题回答(VQA) (Antol等人,2015年)(图1.2中橙色突出)。围绕这些任务,提出并研究了许多相关的任务。
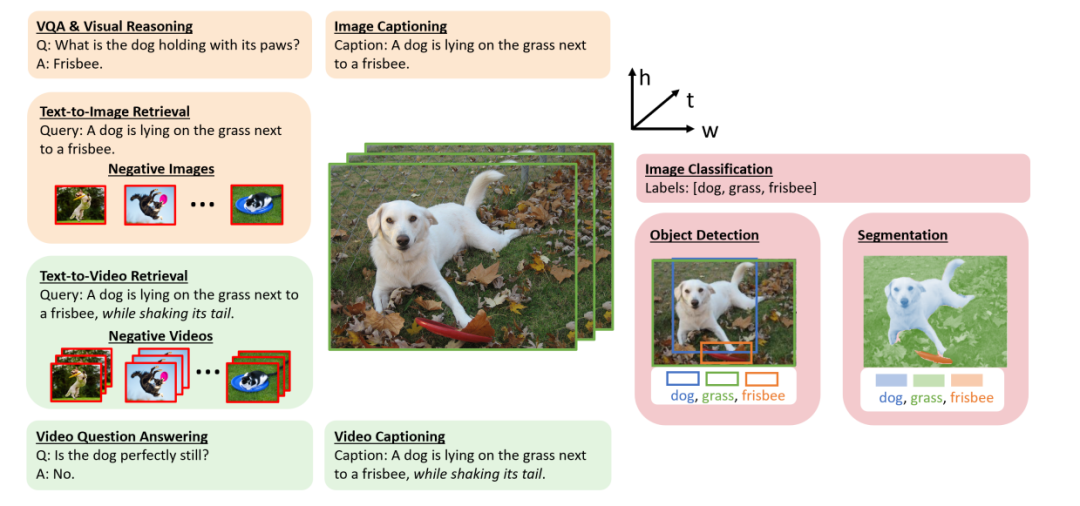
本文涉及的三类VL问题中的代表性任务:图像-文本任务、视觉任务作为VL问题和视频-文本任务。
VQA和视觉推理。作为视觉问题回答的延伸,研究人员为视觉推理开发了数据集(Hudson和Manning, 2019b;Suhr et al., 2019)、视觉常识推理(Zellers et al., 2019)、视觉对话(Das et al., 2017)、基于知识的VQA (Marino et al., 2019)、基于场景文本的VQA (Singh et al., 2019)等。这些任务要求的答案可以是开放式的自由形式的文本,也可以从多项选择中选择。 图像描述。除了需要生成短单句的场景(Lin et al., 2014),研究人员还开发了用于图像段落描述(Krause et al., 2017)、基于场景文本的图像描述(Sidorov et al., 2020)、视觉叙事(Huang et al., 2016)等的数据集。——图像文字检索。流行的图像文本检索数据集是基于图像标题数据集的(Chen等人,2015;普卢默等人,2015)。在给定图像(或文本)查询的情况下,AI模型需要从大型语料库中检索最相关的文本(或图像)。 视觉接地。而不是文本输出,参考表达理解和短语基础(Yu et al., 2016;Plummer et al., 2015)需要边界框输出,其中模型需要预测与输入文本查询对应的边界框。- 文本到图像的生成。它可以被认为是图像字幕的双重任务,其中系统需要基于文本输入创建高保真图像。第3.6节对此任务进行了简要讨论。 *
- 计算机视觉任务作为VL问题。图像分类、目标检测和分割(图1.2中以粉色突出显示)是计算机视觉的核心视觉识别任务。传统上,这些任务被认为是纯粹的视觉问题。随着CLIP (Radford et al., 2021)和ALIGN (Jia et al., 2021)的出现,研究人员意识到语言监督可以在计算机视觉任务中发挥重要作用。首先,利用从网络上抓取的有噪声的图像-文本数据,可以对视觉编码器进行大规模的从无到有的预训练。其次,我们不再将监督信号(如类标签)视为单一热点向量,而是考虑标签背后的语义意义,将这些计算机视觉任务视为VL问题。该视角将传统的闭集分类或检测模型推广到识别现实应用程序中未见的概念,如开放词汇表对象检测。
视频文字任务。除了静态图像,视频是另一种重要的视觉形式。当然,所有上述的图像-文本任务都有相应的视频-文本任务,例如视频字幕、检索和问题回答(图1.2中用绿色突出显示)。与图像相比,视频输入的唯一性要求AI系统不仅要捕获单个视频帧中的空间信息,还要捕获视频帧之间固有的时间依赖性。
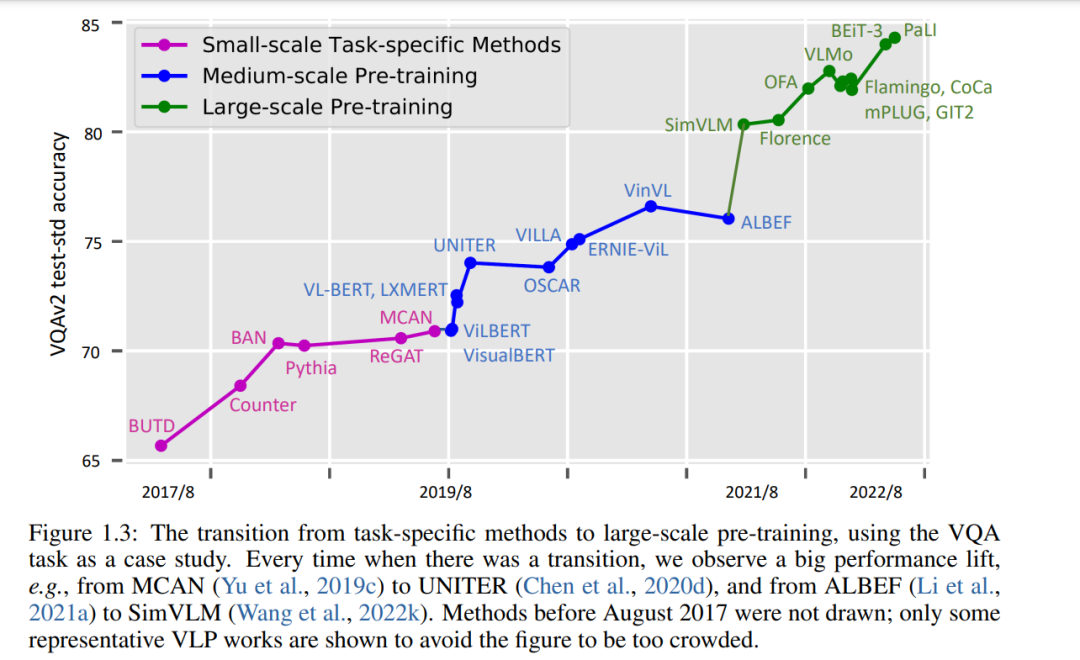
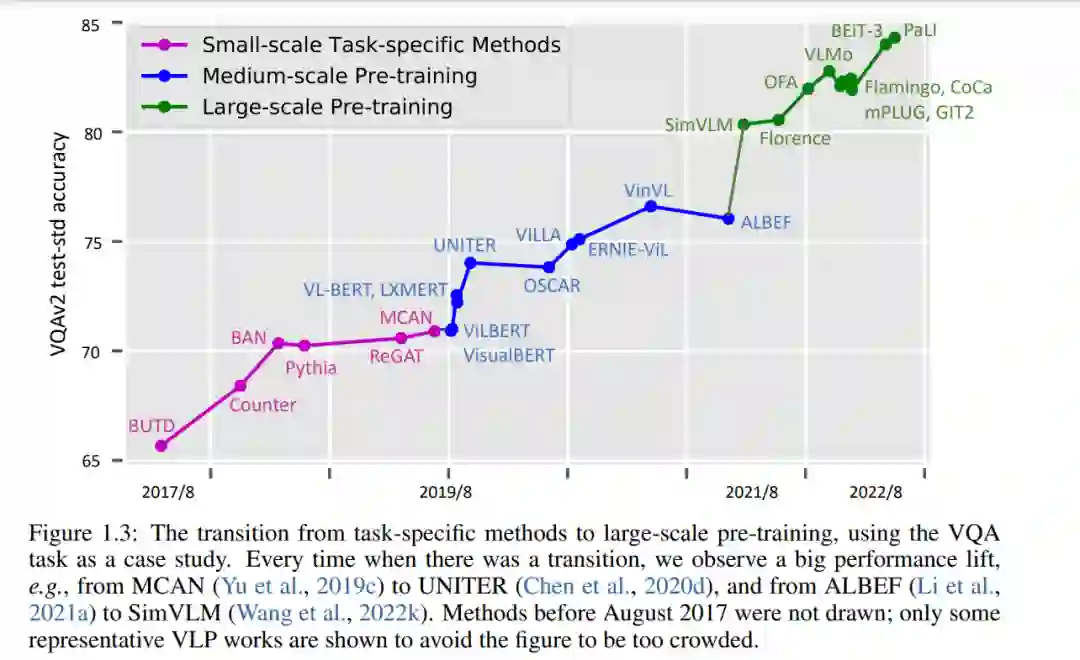
从历史的角度看,VL研究的进展可分为三个阶段。在图1.3中,我们使用流行的VQA任务的表现来说明研究从任务特定方法向中等规模和大规模的预训练过渡。
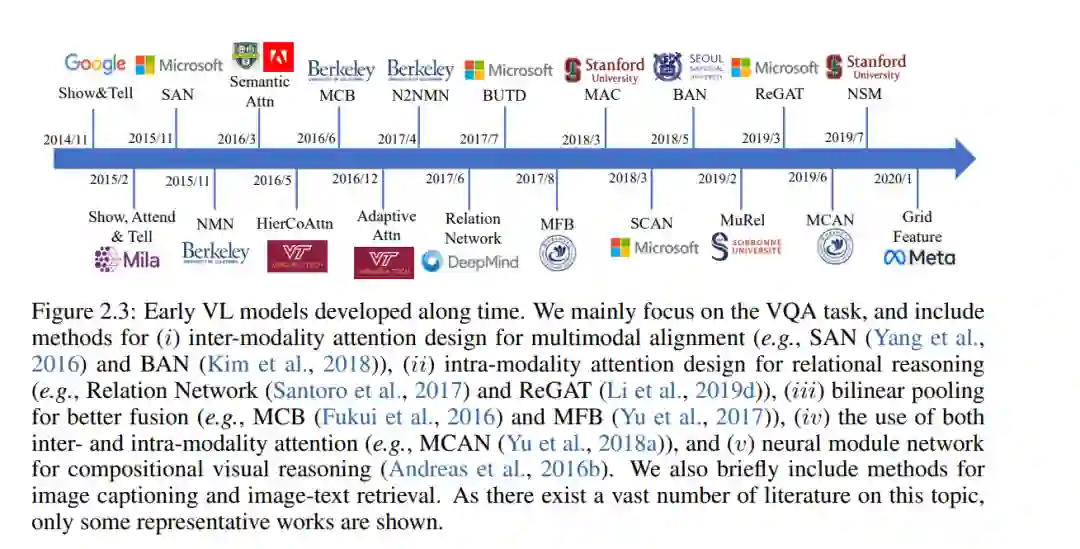
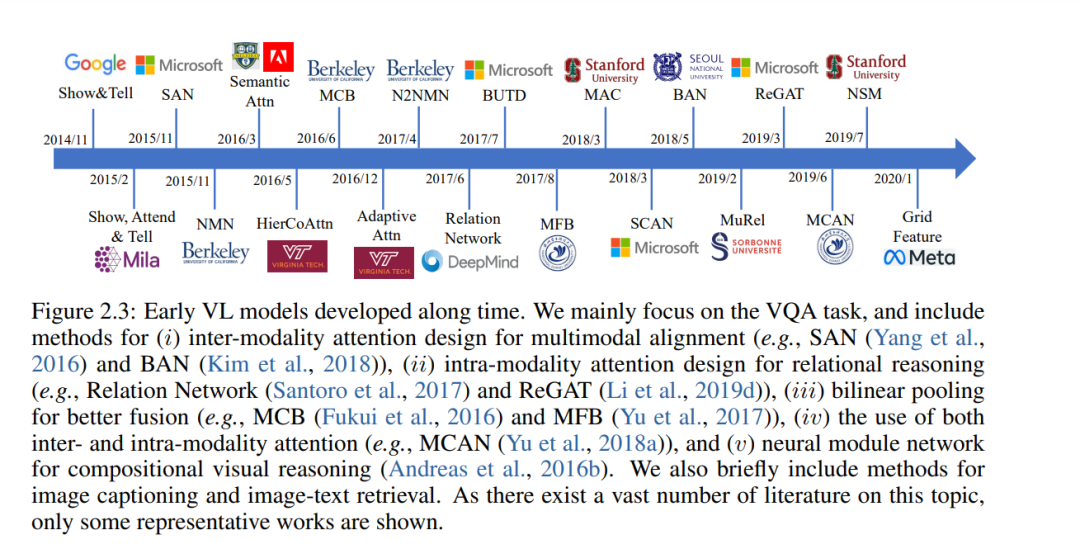
小规模任务具体方法设计(2014/11-2019/8)。在这个阶段,许多特定于任务的方法已经被开发出来用于图像字幕和VQA。例如,一个重要的工作方向是基于预提取的视觉特征(例如,ResNet (He et al., 2016)、Faster RCNN (Ren et al., 2015b)、C3D (Tran et al., 2015))、预训练的词嵌入(例如,GLoVe (Pennington et al., 2014)、word2vec (Mikolov et al., 2013b)和LSTM (Hochreiter和Schmidhuber, 1997)设计各种注意机制,我们将在第二章中回顾。这些注意方法设计已被用于捕获多模态对齐、执行对象关系推理和建模多步推理。
中等规模的预训练(2019/8-2021/8)。受BERT (Devlin et al., 2019)在NLP中的巨大成功的启发,VL领域已逐渐转向使用基于transformer的多模态融合模型,这些模型在中等规模的设置下预先训练过,例如,使用最多4M图像的图像-文本数据集(总共约10M图像-文本对),模型大小从110M (BERT-base)到340M (BERT-large)不等。中型VLP模型的典型例子包括unite (Chen等人,2020d)和OSCAR (Li等人,2020e),这将在第3章中描述。
大规模的训练(2021/8-now)。随着CLIP (Radford et al., 2021)和ALIGN (Jia et al., 2021)的出现,它们旨在从从网络抓取的噪声图像-文本对中训练图像-文本双编码器,大规模VLP显示出了巨大的前景,并正在成为VL研究的基础。我们见证了大型多模态基础模型的蓬勃发展,例如SimVLM (Wang等人,2022k)、Florence (Yuan等人,2021)、Flamingo (Alayrac等人,2022)、CoCa (Yu等人,2022a)和GIT (Wang等人,2022d)。VLP的高计算成本可以通过将预训练的模型适应广泛的下游任务来分摊。用于预训练的图像文本对的数量已经增加到12B以上,模型大小增长到5B,如GIT (Wang et al., 2022d)。我们将在第3.5.1节中详细讨论大模型。
什么是好的视觉语言预训练模型?
**虽然VLP是一个新兴的领域,出现了许多令人兴奋的新论文,但作为一个社区,我们所追求的北极星是什么仍不清楚。**我们提供我们对方向的看法。我们认为一个好的VLP模型应该:
**在广泛的下游任务中取得良好的表现。**可以在两级粒度中考虑任务覆盖率。首先,问题类型比较广泛,例如,一个模型可以执行第3章的VQA、图像字幕和文本到图像生成等图像-文本任务,第4章的图像分类、目标检测和分割等核心计算机视觉任务,第5章的视频-文本任务,如视频QA和字幕。其次,对于每一种问题类型,都有广泛的数据集覆盖,这些数据集表示不同的使用场景。例如,Li等人(2022b)提出了20个图像分类数据集和35个对象检测数据集,以说明野外的各种场景。
**以最小的成本适应新任务。**将VLP模型部署到新任务时,适应成本需要较低。可以考虑各种效率指标来衡量适应成本,包括推理速度、用于进一步模型权值更新的GPU使用情况、训练样本的数量和可训练参数的数量。这是一个尚未明确定义的领域,但已经有了一些早期的努力。例如,Li等人(2022b)通过将适应成本分解为样本效率和参数效率提供了一个定义。
总而言之,一个好的VLP模型的北极星是一个具有固定模型权重(或进行廉价的微调)的统一模型,它可以很好地执行上述所有任务。这是社区正在共同努力的一个雄心勃勃的目标。制定一个中心基准本身就是一个开放的研究问题。我们主张在对标VLP模型时考虑以下因素:任务的覆盖率、这些任务的性能以及适应的成本。
【CVPR2022教程】微软《视觉语言预训练进展》教程,400+页ppt
**视频:**https://www.bilibili.com/video/BV1Xa411W7un/?vd_source=36c95221716f9643e89a58ff57229235