

图神经网络(GNNs)在图表示学习中取得了发展势头,并推动了各种领域的先进水平,例如数据挖掘(如社会网络分析和推荐系统),计算机视觉(如目标检测和点云学习),自然语言处理(如关系提取和序列学习),等等。随着Transformer在自然语言处理和计算机视觉中的出现,图Transformer将图结构嵌入到Transformer架构中,以克服局部邻域聚集的局限性,同时避免严格的结构归纳偏差。本文从面向任务的角度对计算机视觉中的GNNs和图transformer进行了全面的回顾。具体而言,我们将其在计算机视觉中的应用根据输入数据的形式分为五类,即2D自然图像、视频、3D数据、视觉+语言和医学图像。在每个类别中,我们根据一组远景任务进一步划分应用程序。这种面向任务的分类法允许我们检查每个任务是如何由不同的基于GNN的方法处理的,以及这些方法的性能如何。基于必要的初步准备,我们提供了任务的定义和挑战,对代表性方法的深入报道,以及关于见解、局限性和未来方向的讨论。
引言
深度学习[1]为计算机视觉带来了许多突破,其中卷积神经网络(CNN)占据了主导地位,成为许多现代视觉系统的基础设施。特别是,许多最先进的CNN模型,如AlexNet[2]、ResNet[3]和EfficientNet[4],在过去十年中被提出,并在各种视觉问题中取得了前所未有的进展,包括图像分类、目标检测、语义分割和图像处理等。另一方面,现有的视觉系统可以像人类一样建立在各种输入模态之上,如2D图像(如自然图像和医学图像)、视频、3D数据(如点云和网格)以及多模态输入(如图像+文本)。 尽管基于CNN的方法在处理像图像这样的网格状数据结构方面表现出色,但在计算机视觉社区中出现了一种新意识,即数据的非网格拓扑信息对表示学习至关重要,但还有待彻底研究。观察到人类的组合泛化能力在很大程度上依赖于他们表示结构和推理关系的认知机制[5],模仿人类的学习和决策过程可以提高视觉模型的性能,并为最终的预测提供逻辑证据。例如,在物体识别的任务中,最先进的神经网络更倾向于单独感知物体的存在,而不同物体之间的依赖性和相互作用却很少受到关注。
此外,与具有内在边连接和节点概念的自然图数据(如社交网络和生物蛋白质网络)相比,基于规则网格数据(如图像和文本)的图(如关系图)构建缺乏原则性方法,严重依赖于领域知识。另一方面,视觉问题中的一些数据格式,如点云和网格,自然不是定义在笛卡尔网格上的,并且涉及复杂的关系信息。从这个意义上说,无论是规则的还是不规则的视觉数据格式都将受益于拓扑结构和关系的探索,特别是在理解复杂场景、从有限的经验中学习和跨领域的知识转移等具有挑战性的场景。
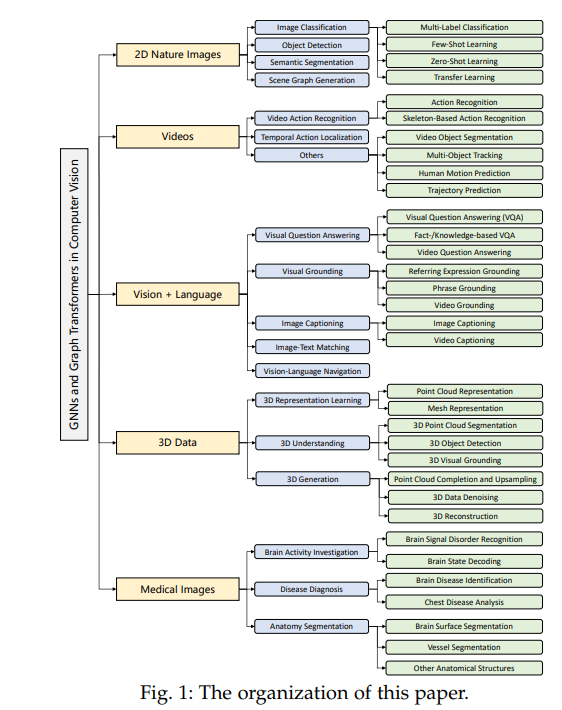
在过去的几年中,在深度学习的最新进展下,GNNs[6]在建模图结构方面展示了突破性的性能。在计算机视觉的范围内,目前许多与GNN相关的研究都有以下两个目标之一:(1)GNN和CNN主干的混合(2)用于表示学习的纯GNN架构。前者通常寻求提高CNN学习到的特征的远程建模能力,适用于以前纯CNN架构解决的视觉任务,如图像分类和语义分割。后者在一些可视化数据格式(如点云)中充当特征提取器,与其他方向相比,它是并行开发的。例如,在点云[7]的三维形状分类任务中,主要有三个研究方向,分别是基于点的MLP方法、基于卷积的方法和基于图的方法。 然而,尽管取得了丰硕的成果,仍然没有一篇综述来系统和及时地回顾基于GNN的计算机视觉的进展。本文对现有研究进行了文献综述,从任务导向的角度对计算机视觉中的图神经网络进行了完整的介绍,包括(i)任务的定义和挑战,(ii)代表性方法的深入覆盖,以及(iii)关于见解、局限性和未来方向的系统讨论。具体而言,我们将GNN在计算机视觉中的应用根据输入数据的形式分为五种类型。在每种类型中,我们根据它们执行的计算机视觉任务对应用程序进行分类。我们还回顾了视觉任务中使用的图变形函数,考虑到它们在架构[8]、[9]方面与GNN的相似性。本次调查的组织如图1所示。 背景知识
在本节中,我们将回顾在计算机视觉中使用的GNN和图transformer。读者可以参考之前的几个GNN调研[10],[11],[12],全面介绍GNN的发展。此外,我们要强调的是,许多现有的基于GNN的视觉方法实际上是使用CNN和GNN的混合,而我们专注于GNN方面。
目录
图像建模 图像分类 多标签分类 少样本学习 零样本学习 迁移学习 目标检测 图像分割 场景图生成 视频理解 视频动作识别 时序动作定位 视觉+语言 视觉问答基准 视觉Grounding 图像描述 3D 数据分析 3D表示学习 3D理解 3D 生成 医学图像分析
尽管在感知方面取得了突破性进展,但如何赋予深度学习模型推理能力仍然是现代计算机视觉系统面临的一个艰巨挑战。在这方面,GNN和图transformer在处理"关系"任务方面表现出了极大的灵活性和优越性。本文首次从面向任务的角度全面综述了计算机视觉中的GNN和图transformer。具体来说,根据输入数据的形式,将各种经典和最新的算法分为5类,如图像、视频和点云。通过系统地梳理每个任务的方法,我们希望这项调查可以揭示未来更多的进展。通过对关键创新、局限性和潜在研究方向的讨论,我们希望读者能够获得新的见解,并向类似人类的视觉理解更进一步。


