图像配准是图像引导手术、图像融合、器官图谱生成、肿瘤和骨骼生长监测等临床任务应用的关键技术,也是一个极具挑战性的问题。近年来,深度学习技术对医学图像处理方法的研究产生重要的影响,在医学图像配准领域发展迅速。来自美国辛辛那提儿童医院医疗中心等发布了**《深度学习医学图像配准》**综述,阐述了相关进展。

图像配准是各种医学图像分析应用中的一个重要组成部分。近年来,基于深度学习(DL)的医学图像配准模型发展迅速。本文对医学图像配准技术进行了综述。首先,讨论了监督配准的分类,如完全监督配准、双重监督配准和弱监督配准。接下来,基于相似度和基于生成对抗网络(GAN)的配准被提出作为无监督配准的一部分。然后描述了深度迭代配准,重点是基于深度相似度和基于强化学习的配准。此外,对医学图像配准的应用领域进行了综述。本文主要综述单模态和多模态配准及其相关成像,如X线、CT扫描、超声和MRI。本综述强调了现有的挑战,其中显示,一个主要挑战是缺乏具有已知转换的训练数据集。最后,讨论了基于深度学习的医学图像配准的未来研究方向。
https://www.zhuanzhi.ai/paper/1fb1db2059362b38007d8e59df7d6f61
引言
使用图像配准,可以将不同的图像集合合并到一个具有相同信息的单一坐标系中。当比较从不同角度多次拍摄的两幅图像或使用不同的模态/传感器时,可能需要配准[1,2]。直到最近,大多数图像配准都是由医生手工完成的。人工对齐在很大程度上依赖于用户的能力,这在临床上可能不利于某些配准程序的质量。自动配准的产生是为了克服一些可能的缺点手动图像配准。DL的复兴改变了图像配准研究的背景[3],尽管事实上各种自动图像配准方法已经被深入研究之前(和期间)。DL[4]使最近的工作在广泛的计算机视觉任务中得以表现,包括但不限于: 图像分类[4],分割[5],特征提取[6-8],以及目标识别[9]。作为一个起点,DL在增强基于强度的配准性能方面被证明是有用的。这只是时间问题,直到其他研究人员看到使用强化学习的配准过程的应用[10-12]。由于获取/创建地面真实数据的困难,人们对开发用于一步转换估计的无监督框架越来越感兴趣[13,14]。图像相似度量化是这一范式中的一个众所周知的障碍。应用基于信息理论的相似性度量[13]、生成对抗网络(GAN)框架[16]和解剖特征分割[17]来解决这一难题,取得了良好的效果。
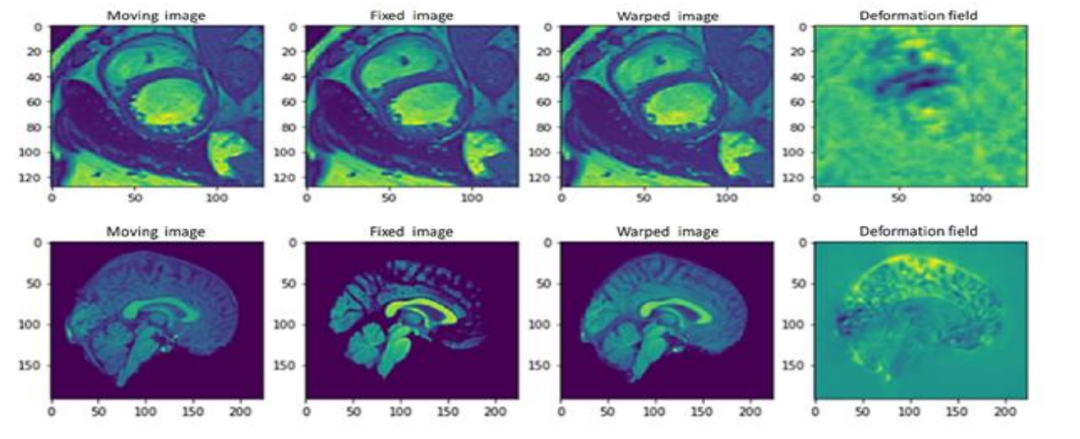
传统的图像配准是一个基于迭代的过程,包括收集必要的特征,确定相似度(以评估配准质量),选择变换模型,最后是搜索机制[18,149,153]。可以发送到系统的图片有两种: 移动和固定,如图1所示。通过在静止图像上反复滑动移动图像,可以获得最佳对齐。考虑的相似性度量最初决定了输入的照片之间的相似度。计算新转换的参数是通过使用更新机制的优化方法完成的。通过将这些因素作用于运动图像,就产生了具有改进对齐的图像。否则,将开始一个新的算法迭代。如果满足终止要求,则流程结束。直到不能再获得配准或满足一定的预定要求,运动图像才会在每一个循环中改善与静止图像的对应关系。该系统的输出既可以是变换参数,也可以是最终的插值融合图像。
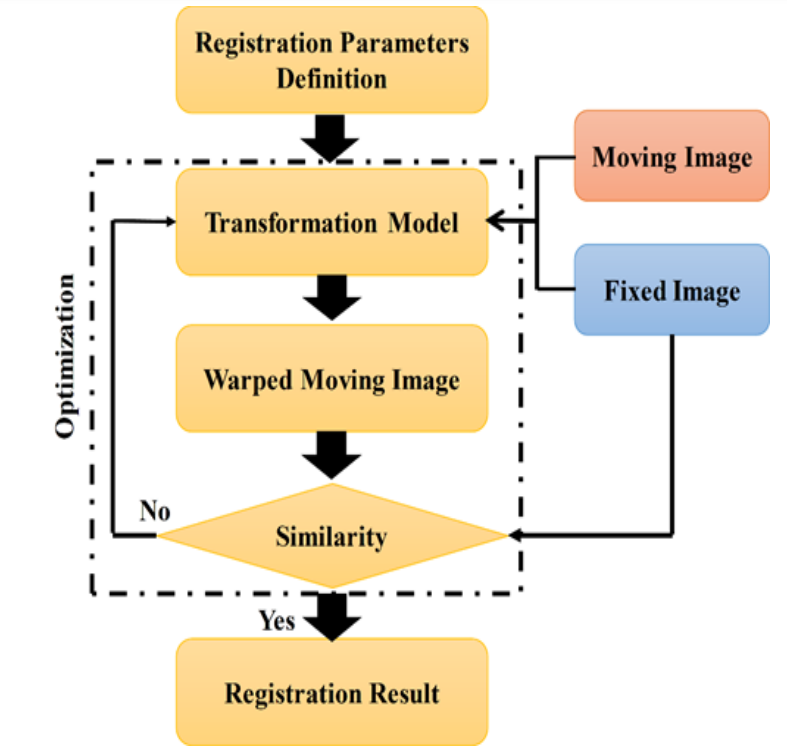
一个用于医学图像的图像配准框架流程图
有必要对使用DL的医学图像配准领域进行彻底的调研,突出专家面临的常见问题,并讨论可以解决这些挑战的即将到来的研究可能性。它是一种利用多层神经网络(NN)来学习数据描述的机器学习(ML)。许多不同种类的神经网络可以用于不同的目的,最近已经开发出一些重要的设计来解决工程挑战。在讨论神经网络时,也可以讨论许多神经网络的训练过程。关于神经网络类型、训练范式、网络结构以及方法的章节构成了DL的介绍。PyTorch[19]、Caffe[20]、Keras[21]、MXNet[22]和TensorFlow[23]都是可用于创建网络的公共访问库。现有的文献主要集中在医学图像分析中使用DL、reinforcement learning和GANs进行医学图像分析。
本文综合回顾了现有文献中基于离散域的图像配准的研究进展。本文着重从方法和功能的角度对其创新进行了综述。本文研究了不同形式的配准,包括无监督和监督变换估计,以及深度迭代配准。讨论了当前图像配准的趋势、挑战和局限性。最后,本文对未来的研究方向进行了展望。
监督配准模型
对于深度学习模型,监督训练是各种配准模型的共同基础。根据在训练阶段中使用的监督程度,有三个子类别的模型: 完全监督、双重监督和弱监督。完全监督配准利用传统配准算法中的真DVFs来监督学习过程。这些损失通常是由于地面真实值和预期SVF不匹配造成的,如图2所示。弱监督配准使用隐式参考标签,而不是使用广泛使用的解剖轮廓参考DVF,如图2所示。经常使用两种以上的参考数据来训练双监督配准模型。这包括解剖结构轮廓、参考SVF以及图像相似性。

弱监督和完全监督配准模型的示例工作图
尽管为了解决有监督图像配准的信息或数据稀缺问题,人们采取了许多策略(如弱监督和数据增强)[43-47],但训练样本的创建仍然是一个耗时的过程。由于移动和固定的图像配对是DL模型需要学习的所有变形,无监督配准是一种方法。表1提供了这个子类别的概述。在这一类别的训练中仍然需要一个可与传统迭代配准中使用的损失函数。一个DVF正则化项和一个图像相似项和通常包括在损失函数中。由于固有卷积的性质,一些相似性度量,即局部NCC (LNCC),被改变为专注于微小斑块。可以引入各种损失项,如防止过拟合的同一性损失和减少奇异性的循环一致性损失。
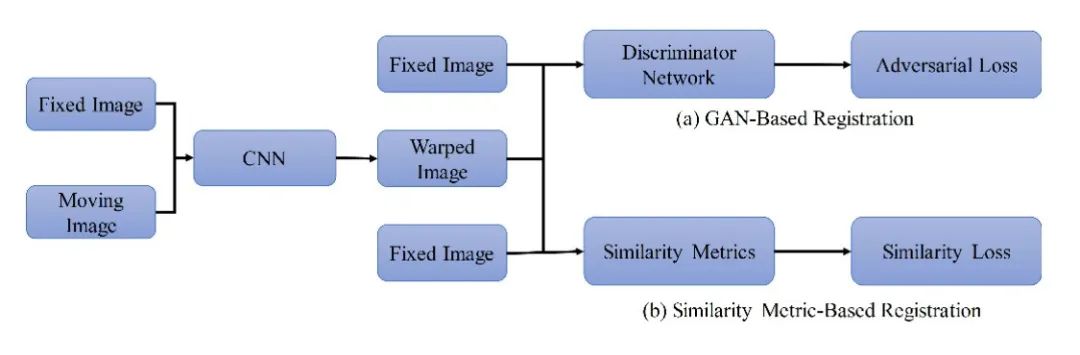
基于(a) GAN和(b)相似矩阵的医学图像配准通用框架
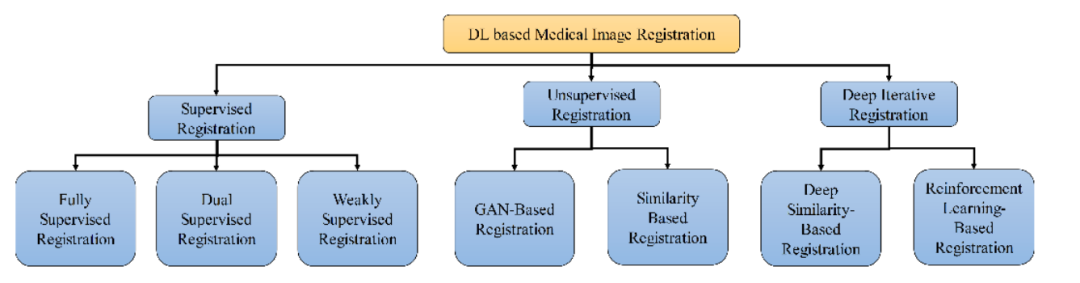
各种医学图像配准通用框架
本文综述了近年来在医学图像配准方面的研究进展。由于每个应用程序都有不同的问题,因此有必要谨慎地开发DL框架。多模态图像配准,比如涉及TRUS和MRI的配准,也面临着类似的挑战,比如无法在多模态应用中使用稳健的相似性度量,缺乏大型数据集,难以获得地面真实值配准和分割,以及量化模型的偏好。(36、37)。解决这些问题的常用方法包括补丁式框架、应用程序特定的相似性度量、注册框架和受变分自动编码器影响的无监督技术。插值和重采样,尽管在本文中描述的许多方法复杂,通常不是由神经网络学习。随着该领域的成熟,我们预计会有更多的学者将这些组件包含到他们基于深度学习的解决方案中。每种策略都有自己的优点和局限性,但比较这两种策略的研究人员总数大致相同。在这两个领域,我们预计会出现更多结合这两种策略的好处的研究和新方法。我们预测在这两类中还会有进一步的研究。