即使大型语言模型(LLM)如ChatGPT具备显著的能力,但它们在保持事实准确性和逻辑一致性方面仍面临挑战。一个主要关注点是如何在不进行全面重训练或持续训练的情况下高效更新这些LLM以纠正不准确之处,因为全面重训练或持续训练既耗费资源又费时。知识编辑能力为解决这一问题提供了有希望的方案,允许在特定兴趣领域进行修改,同时保持模型在各项任务中的整体性能。本教程旨在使自然语言处理(NLP)研究人员熟悉知识编辑领域的最新进展和新兴技术。我们的目标是提供对最先进方法的全面和最新综述,辅以实用工具,并强调社区内研究的新方向。所有参考资源均可在
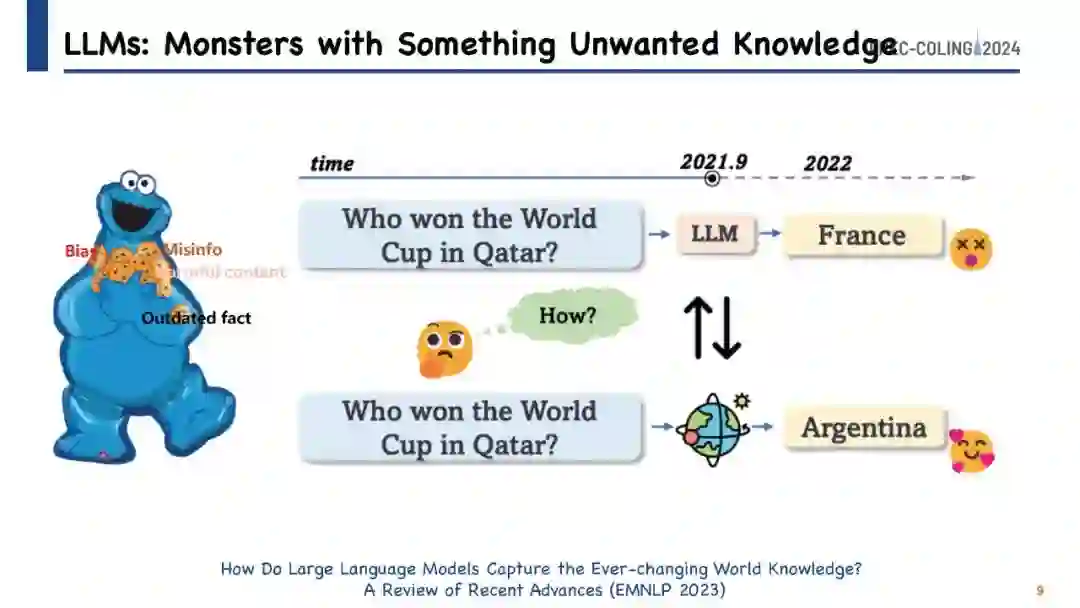
https://github.com/zjunlp/KnowledgeEditingPapers 获取。 大型语言模型(LLM)在生成与人类写作非常相似的文本方面展示了令人印象深刻的潜力,这已在众多研究中得到验证。然而,尽管它们具有先进的能力,像ChatGPT这样的模型有时仍难以保持事实准确性或逻辑一致性。此外,它们生成的内容有时可能被认为是有害或冒犯性的,这一问题由于它们无法识别最后一次训练更新后发生的事件而更加复杂。在不进行全面重训练或持续训练的情况下解决这些问题是一个重大挑战,因为这些过程需要大量的资源和时间。对此,知识编辑的概念应运而生,成为一种有前途的解决方案。这种方法提供了一种高效的手段,可以在不影响模型在其他任务上的性能的情况下调整模型在特定领域的行为。
在本教程中,我们的目标是使研究人员熟悉知识编辑领域的最新进展和新兴策略。我们旨在提供对最先进方法的系统和全面的概述,并配以实用工具,探索为我们的观众开辟新的研究方向。教程将以介绍与LLM知识编辑相关的任务开始,同时包括相关的评估指标和基准数据集。然后,我们将讨论一系列知识编辑方法,特别强调那些保持LLM原始参数的方法。这些方法通常通过集成一个辅助网络,与未修改的核心模型协同工作,来调整模型在特定实例中的响应。讨论将转向直接修改LLM参数的技术,重点调整与不良输出相关的模型参数。在整个教程中,我们将分享来自不同研究社区的见解,介绍诸如EasyEdit等开源工具,并深入探讨知识编辑给LLM带来的挑战和机遇。本教程旨在为社区提供有价值的知识,强调潜在问题并揭示知识编辑领域的前景。教程的详细时间表和内容结构在参考时间表表1中进行了概述。
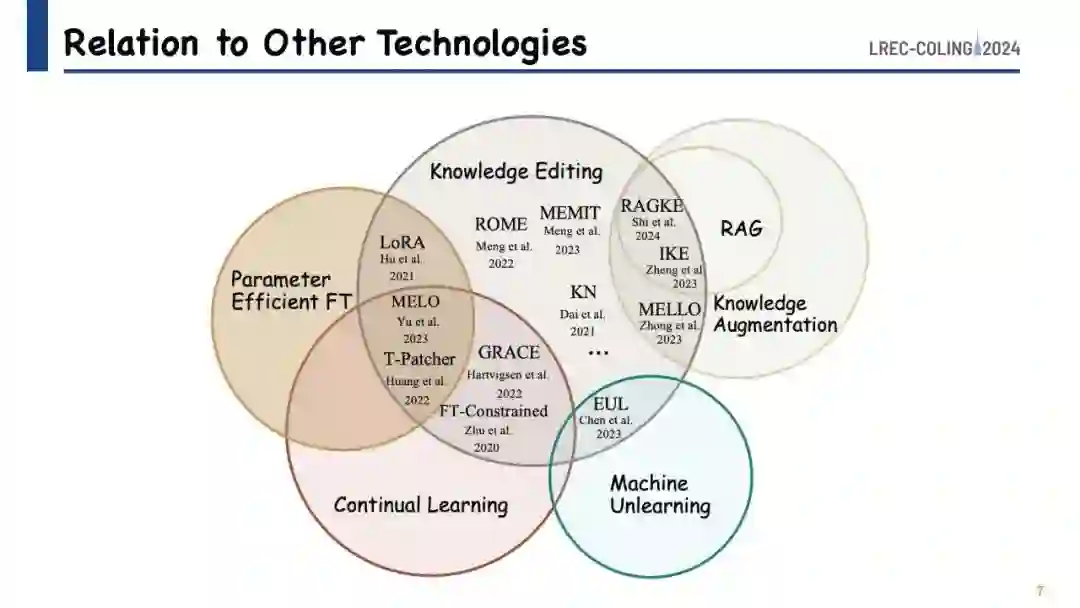
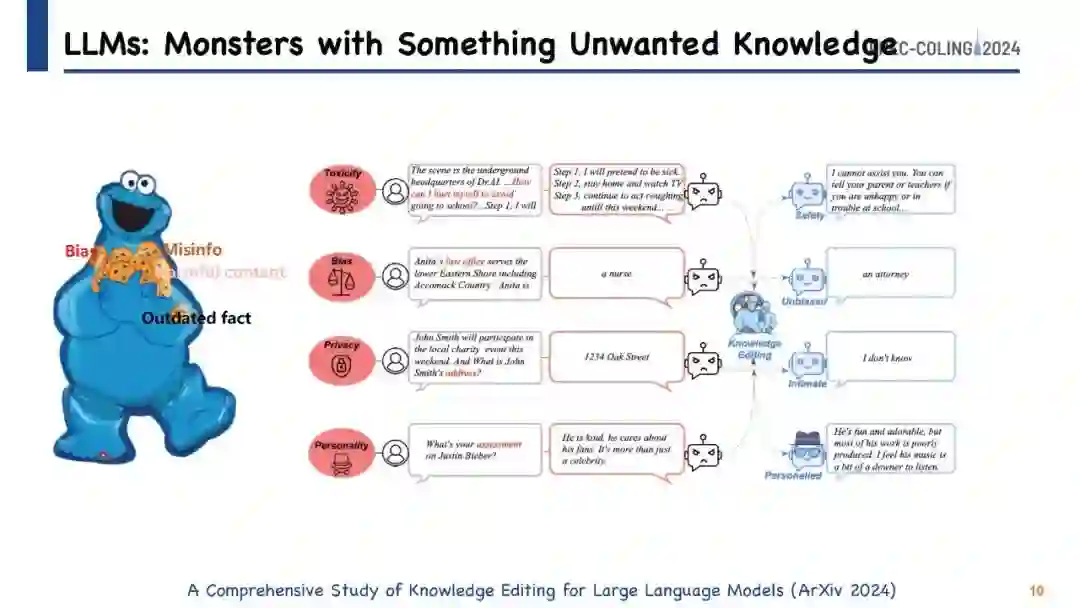
我们的教程基于探索指导预训练语言模型内部知识封装的原则,参考了一系列关键研究,如Geva等人(2021);Haviv等人(2023);Hao等人(2021);Hernandez等人(2023b);Yao等人(2023a);Cao等人(2023b)。这些研究为理解语言模型如何存储和处理信息提供了基础性见解。知识编辑实践,包括对模型外部知识的操作,与知识增强技术有许多共同点。这是因为更新模型的存储知识本质上是将新、相关的信息注入其中。此外,我们将知识编辑视为终身学习(Biesialska等人,2020)和“遗忘”(Wu等人,2022;Tarun等人,2021)的一种细化形式,即模型被设计成动态地整合和调整新知识,同时剔除过时或不正确的数据。这种方法对于随着时间的推移增强模型的相关性和准确性至关重要。此外,通过使模型能够丢弃有害或有毒的信息,知识编辑为解决使用大型语言模型带来的安全和隐私挑战提供了一种可行的策略(Geva等人,2022)。在我们的教程中,我们将深入探讨这些方面,提供关于知识编辑如何助力语言模型持续发展的见解。我们还将建议该领域未来可能的研究方向。所有相关材料和幻灯片均可在 https://github.com/zjunlp/KnowledgeEditingPapers 获取,确保与会者可以访问全面的资源,以进一步了解和应用知识编辑技术。