

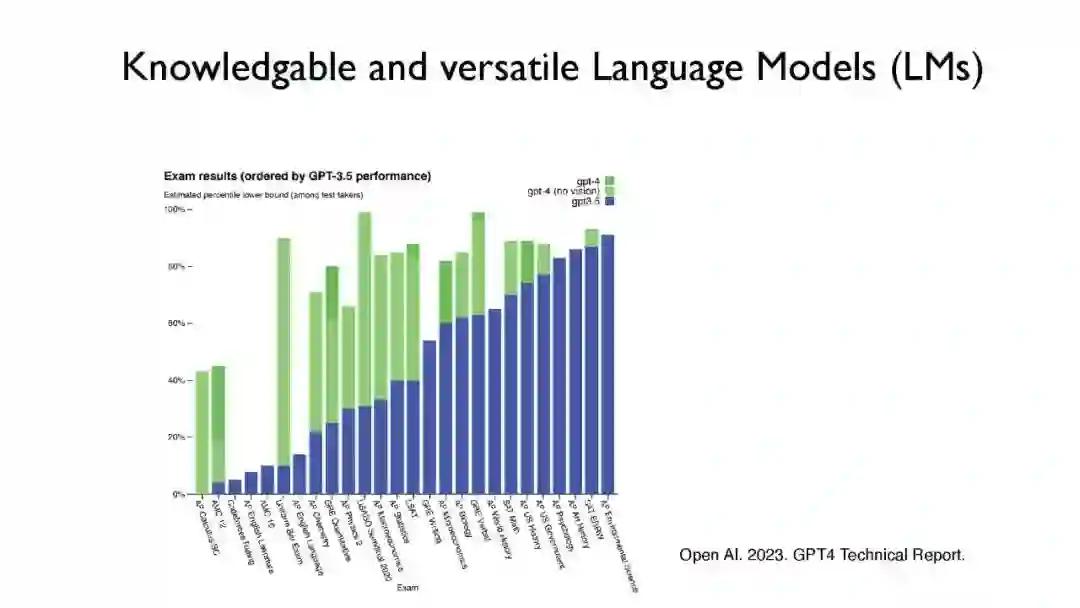
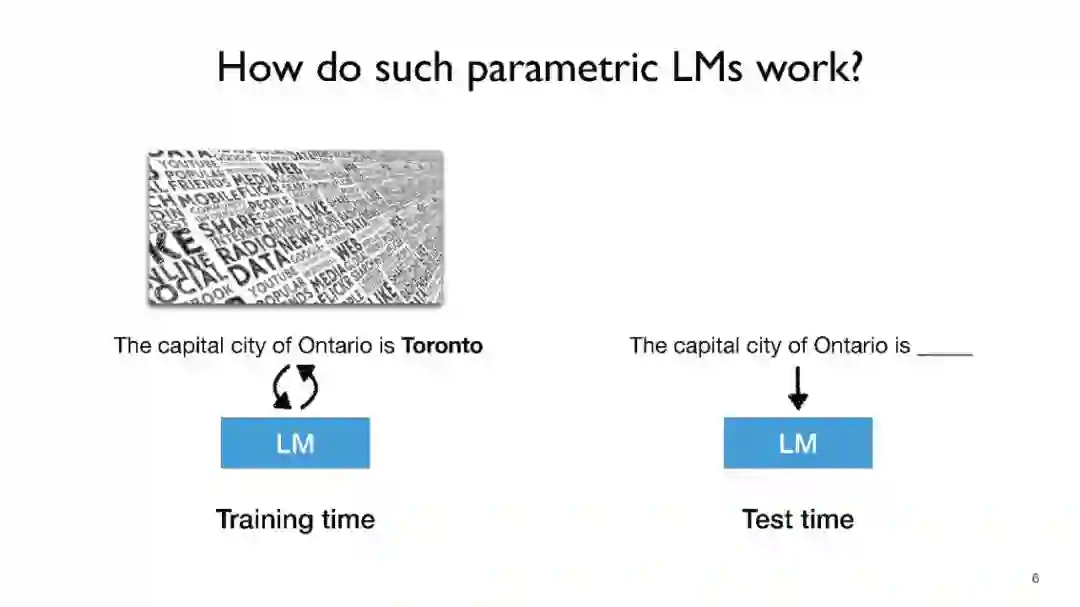
语言模型(LMs),如GPT-3和PaLM,在自然语言处理(NLP)任务中展现了令人印象深刻的能力。然而,仅依赖它们的参数来编码大量世界知识需要非常多的参数,因此需要大量计算,而且它们通常难以学习长尾知识。此外,这些参数化的LMs从根本上无法随时间适应,经常产生幻觉,并可能从训练语料库中泄露私人数据。为了克服这些限制,对基于检索的LMs有着越来越多的兴趣,这类LMs结合了非参数化数据存储(例如,来自外部语料库的文本块)和它们的参数化对应物。基于检索的LMs可以以远少于无检索LMs的参数数量大幅度超越它们的性能,可以通过替换其检索语料库来更新它们的知识,并为用户提供引用,以便于轻松验证和评估预测。 在这个教程中,我们旨在提供一个关于基于检索的LMs最近进展的全面而连贯的概览。我们将首先提供涵盖LMs和检索系统基础的初步内容。然后,我们将专注于基于检索的LMs的最新架构、学习方法和应用进展。




成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日