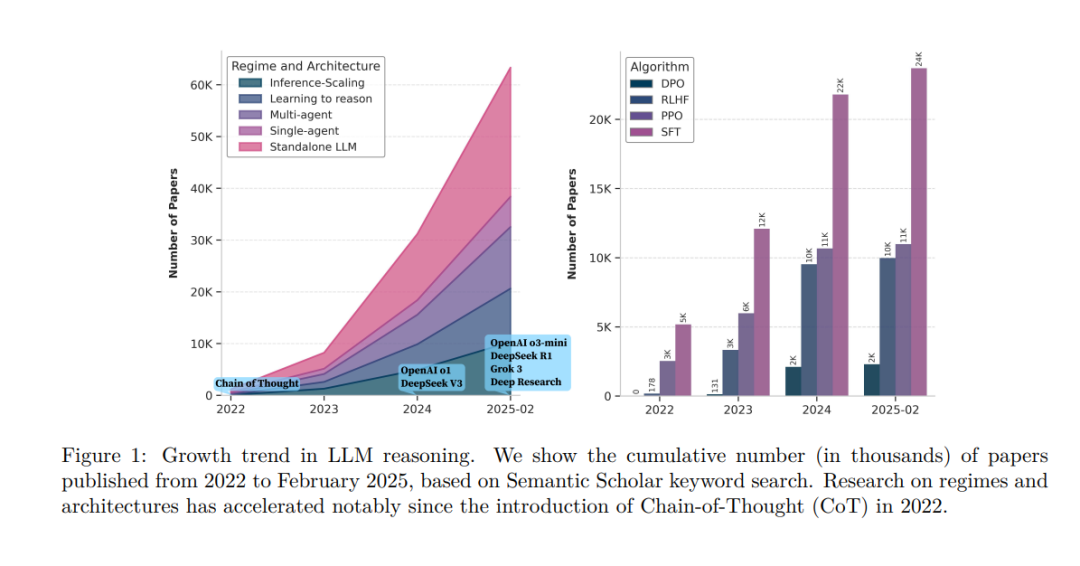
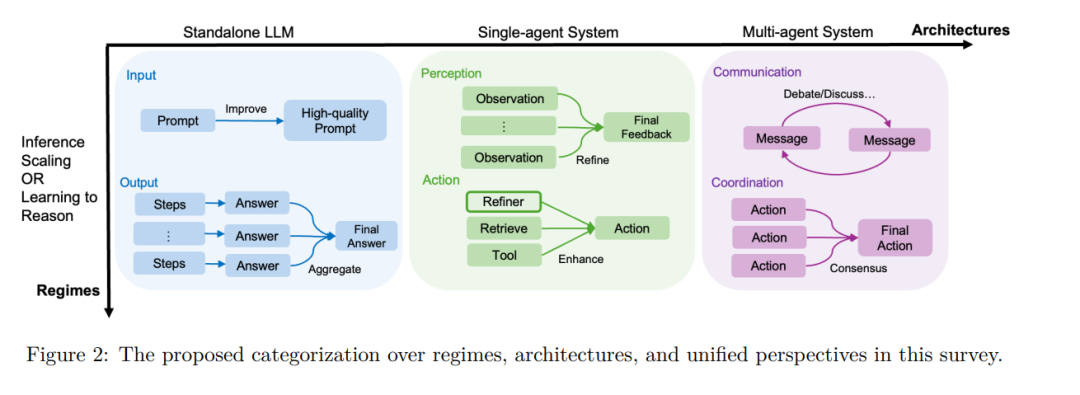
推理是一种基础的认知过程,使智能体具备逻辑推理、问题求解与决策制定的能力。随着大语言模型(Large Language Models,简称 LLM)的快速发展,推理能力已成为先进人工智能系统区别于传统聊天机器人模型的关键特征。 在本综述中,我们从两个正交维度对现有方法进行分类: 1. 推理范式(Regimes):指推理发生的阶段,分为推理时刻(inference-time)与专门训练(dedicated training); 1. 推理架构(Architectures):指参与推理过程的系统结构,涵盖独立的 LLM、引入外部工具的智能体系统(agentic systems),以及**多智能体协作(multi-agent collaboration)**等不同类型。
在每个维度下,我们进一步从两个关键视角展开分析: * 输入层面(Input level):研究如何构造高质量提示(prompts),使 LLM 基于良好的条件进行推理; * 输出层面(Output level):聚焦于如何优化多次采样的候选输出,以提升推理质量。
该分类框架系统性地梳理了 LLM 推理能力的发展图谱,揭示了几个关键演进趋势,例如: * 从“推理扩展(inference scaling)”向“学习推理能力(learning to reason)”的转变(如 DeepSeek-R1); * 向“智能体式工作流(agentic workflows)”的过渡(如 OpenAI Deep Research、Manus Agent)。
此外,本文还覆盖了广泛的学习算法,包括从监督微调(supervised fine-tuning)到强化学习(如 PPO 与 GRPO),以及用于训练推理器(reasoners)和验证器(verifiers)的多种机制。 我们还回顾了智能体式工作流的关键设计模式,从经典的生成-评估器结构(generator-evaluator)、LLM 辩论机制(LLM debate),到最新的创新框架。 最后,我们指出了当前研究中的新兴趋势,例如面向特定领域的推理系统,以及亟待解决的开放问题,如评估标准与数据质量控制。 本综述旨在为人工智能研究人员与实践者提供一个全面的理论与方法基础,以进一步推动大语言模型中的推理能力发展,为构建更加复杂、可靠的 AI 系统铺平道路。