

推理是一种基础的认知过程,支持逻辑推导、问题求解和决策制定。随着大型语言模型(LLMs)的快速发展,推理已成为区别于传统模型(如简单聊天机器人)的关键能力,也是先进 AI 系统的重要标志之一。 在本综述中,我们从两个正交维度对现有方法进行了分类:
推理阶段(Regimes):定义推理是在何种阶段实现的——推理时刻(inference time)或通过专门训练获得;
系统架构(Architectures):定义参与推理过程的组成模块,区分独立式 LLM 与包含外部工具的自主型复合系统(agentic compound systems),以及多智能体协作系统(multi-agent collaborations)。
在每个维度下,我们又从两个关键视角进行分析:
输入层面(Input level):聚焦于构建高质量提示(prompts)的技术,用以引导模型进行有效推理;
输出层面(Output level):关注如何通过多样化候选输出的精炼过程提升推理质量。
这种分类方法为理解 LLM 推理不断演进的格局提供了系统化视角,重点突出了几大前沿趋势,例如:
从**推理扩展(Inference Scaling)向学习推理(Learning to Reason)**的转变(例如 DeepSeek-R1);
从传统模型向**自主智能工作流(Agentic Workflows)**的过渡(例如 OpenAI Deep Research、Manus Agent)。
此外,我们还涵盖了广泛的学习算法,包括从监督微调到强化学习(如 PPO、GRPO),以及“推理器(reasoners)”与“验证器(verifiers)”的联合训练机制。 我们进一步探讨了多种 agentic 工作流的关键设计,包括经典范式(如“生成器-评估器”框架、LLM 辩论机制)和最新技术创新。最后,我们指出了正在兴起的趋势(例如面向特定领域的推理系统)以及尚未解决的挑战(如推理评估方法和数据质量问题)。 本综述旨在为 AI 研究者与开发者提供一个关于 LLM 推理的全面基础,推动构建更具智能性、可靠性与推理能力的下一代人工智能系统。
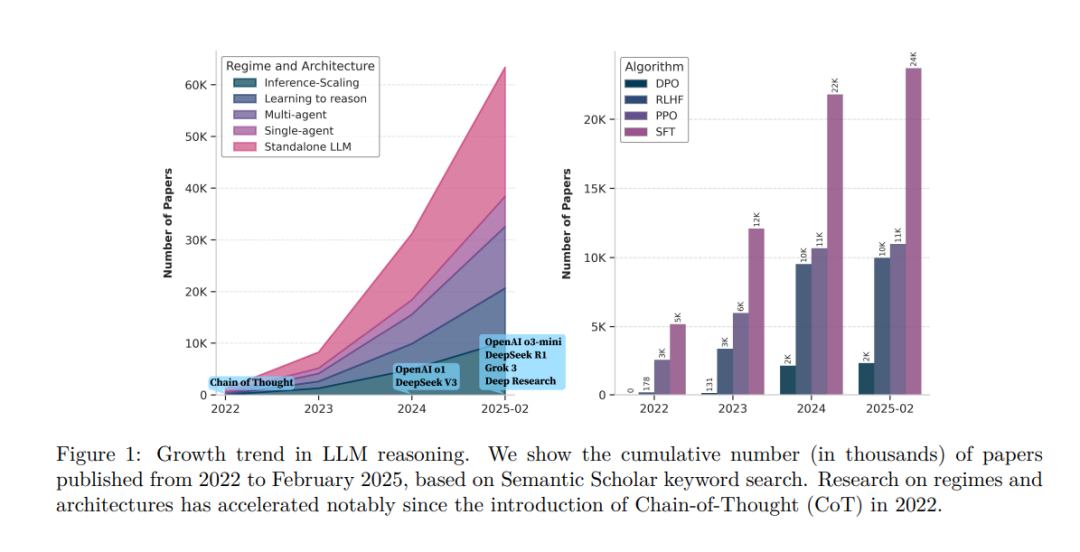
1 引言
推理是一种核心认知过程,涉及分析证据、构建论证并应用逻辑以形成结论或做出合理判断。它在众多智力活动中至关重要,例如决策制定、问题求解和批判性思维。对推理的研究跨越多个学科领域——哲学(Passmore, 1961)、心理学(Wason & Johnson-Laird, 1972)和计算机科学(Huth & Ryan, 2004),为我们理解人类如何解释信息、评估选项以及通过逻辑得出可靠结论提供了深刻见解。 近年来,大型语言模型(LLMs)在推理能力上展现出诸多新兴能力,如上下文学习(Dong 等,2024)与角色扮演(Shanahan 等,2023b),而推理已成为其最关键的能力之一。如图1所示,该研究领域迅速获得关注,通常被称为“LLM 推理”或“推理语言模型(Reasoning Language Models, RLM)”(Besta 等,2025)。这种关注的增加是可以理解的,因为推理能力:
具有挑战性:需要超越 LLMs 基于 token 的自回归生成方式,进行多步处理;
具有基础性:推理是智能的核心,尤其在规划和战略决策中; 极具前景:近期 LLMs 的进展为其发展指明了方向。
因此,推理被广泛视为迈向通用人工智能(AGI)的重要前提,远超当前以执行指令为核心的传统 AI 系统(Duenas & Ruiz, 2024)。 推理要求 LLMs 不仅仅是从问题直接生成答案,更需要产生思维过程(显性或隐性),形式为“问题 → 推理步骤 → 答案”。已有研究表明,仅仅通过扩展预训练规模并不能有效提升推理能力(Snell 等,2025;OpenAI,2025)。一种流行的替代方法是思维链(Chain-of-Thought, CoT)提示(Wei 等,2022b):通过修改提示词(如“让我们一步步思考”)或提供具体范例,使模型在无需额外训练的情况下,于测试时就能展现出分步推理过程。该方法已被证明显著提高了 LLMs 的推理准确性。 基于此,我们认为有效的 LLM 推理能力取决于两个关键因素: * 推理发生的方式与阶段
参与推理过程的系统架构
因此,我们将现有研究分为两个正交维度:
推理机制(Regime):推理是在推理时刻(inference-time scaling)实现,还是通过训练进行学习(learning to reason);
系统架构(Architecture):推理是在单一的 LLM 内部完成,还是在与外部工具互动的“自主智能系统”中完成。
这两个维度彼此独立:同一架构可适配不同机制,反之亦然。这种交叉视角能够系统地梳理当前 LLM 推理方法,概括研究趋势(如从“推理扩展”向“学习推理”的转变、从单体模型到自主系统的演进)。值得注意的是,已有的综述大多只关注了这两个维度中的某一个,如“推理扩展”与“单体 LLM”,而较少同时考虑二者(详见后文比较)。 通过引入这种分类框架,我们希望为读者提供一个清晰的结构化视角,从而全面理解 LLM 推理领域,并为后续研究打下坚实基础。
1.1 推理机制(Reasoning Regimes)
推理扩展(Inference Scaling): CoT 提示展示了在推理时刻(test-time)扩展推理能力的潜力。已有研究表明,在推理阶段优化计算资源(如设计提示和工作流)比扩大模型参数更有效(Snell 等,2024),因为它增强了模型的泛化能力。 由此衍生出一类新方法:推理时扩展技术。这些方法在生成答案前允许额外的推理步骤,而不是更新模型参数。其核心理念是:通过选择更优的推理路径来提升推理质量。 相关提示方法(Paranjape 等,2021;Sanh 等,2022;Mishra 等,2022)通过结构化提示增强推理能力。此外,推理扩展还依赖于搜索与规划策略(Dua 等,2022;Zhou 等,2023a;Khot 等,2023;Suzgun & Kalai,2024a)。但搜索策略的主要挑战之一在于候选解的评估困难——即使对人类而言也不易。现有评估方法可分为两类: * 结果奖励模型(Outcome Reward Models, ORMs):评估最终输出是否正确; * 过程奖励模型(Process Reward Models, PRMs):评估中间推理过程是否合理。
一个里程碑式成果是 OpenAI 的 o1(2024年9月发布)(OpenAI 等,2024),其在数学、编程和科学问题上展示了推理扩展的强大能力: “我们发现,随着强化学习训练量(训练计算)与推理时间(测试计算)的增加,o1 的表现持续提升。这种方法的扩展规律与传统的 LLM 预训练截然不同,我们正在持续探索其潜力。” ——OpenAI o1 发布博客 学习推理(Learning-to-Reason): 另一种策略是通过训练显式增强推理能力。这减少了对昂贵的测试时计算的依赖。然而,这一机制的主要挑战是:缺乏高质量的带注释推理轨迹数据,因为人工标注代价极高。 为此,研究者们探索了自动生成推理路径的方法,并发展了多种训练策略,如: * 长思维链的监督微调(Muennighoff 等,2025); * 偏好学习(如 DPO):通过人类偏好学习推理路径(Rafailov 等,2023); * 强化学习方法(如 GRPO):无需人工标注,自动习得复杂推理行为(Shao 等,2024)。
最具代表性的成果之一是 DeepSeek-R1(2025年1月发布),该模型在资源消耗显著低于 OpenAI o1 的情况下实现了可比性能。其“自我演化”现象尤为突出: “我们观察到,随着推理时间的增加,模型自然展现出一系列复杂行为,如‘反思’——即回顾并修正之前的推理步骤,以及探索替代性问题解决策略。这些行为并非显式编程实现,而是模型在强化学习环境中交互过程中自发涌现的。” ——DeepSeek-R1 “顿悟时刻”
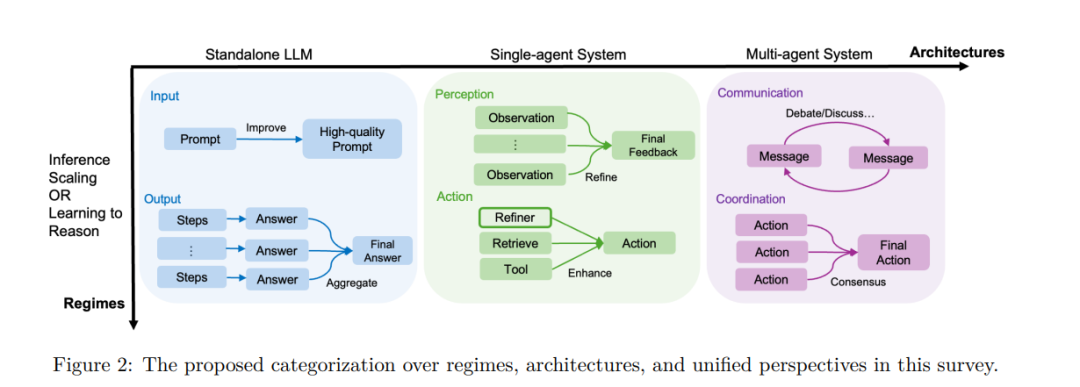
1.2 推理系统架构(Reasoning System Architecture)
独立 LLM 与自主系统(Standalone LLM and Agentic Systems)
在“机制”维度之外,研究者还从系统架构角度探讨了 LLM 推理的拓展路径:即从传统的“下一词预测”模型,发展为具备交互性与自主性的agentic 系统,以实现更复杂的推理与决策能力。这类系统不仅面临推理扩展与学习推理的挑战,还引入了系统层面的复杂性,如:设计工作流、协调潜在冲突的动作等。 单智能体与多智能体系统(Single-Agent and Multi-Agent Systems)
为了区分“agentic 系统”与“独立 LLM”,我们采用 Kapoor 等人(2024)提出的观点,将智能体行为视为一个连续体。我们将其进一步划分为两类: * 单智能体系统:单一 LLM 与其环境中的工具进行交互,以增强其推理、行为与感知能力。 这些工具包括: 一些具有代表性的系统包括: 它们展示了智能体如何与互联网交互以提升推理性能,执行信息检索、计算任务并整合多源数据: “Deep Research 可自主发现、推理并整合网络中的洞见。为实现这一目标,它在多个需要使用浏览器与 Python 工具的真实任务上进行了训练…… 虽然 o1 在编程、数学等技术领域展现了出色能力,但现实中的许多挑战更依赖广泛的上下文与多源信息获取。” ——OpenAI Deep Research 发布博客
Grok 3 Deep Search(2025年2月)
OpenAI Deep Research(2025年2月)
外部知识库(Hammane 等,2024;Sun 等,2023)、 * 验证器(Wan 等,2024c;Guan 等,2025) * 实用型应用,如代码解释器、日历、地图等(Yu 等,2023b;Lu 等,2024a)。 通过这些工具,LLM 可以迭代式地优化自身的决策与问题求解过程。 * 多智能体系统:不仅包括智能体与环境的交互,还允许多个智能体之间的通信与协作。 每个智能体承担特定角色,并通过消息交换完成任务。 关键挑战包括: 一个突出案例是多智能体系统产品 Manus,展示了此类架构在真实应用中的强大潜力。
设计高效的通信协议(如协同式 Chen 等,2023c;对抗式 Liang 等,2023b); * 协调动作,达成对最终输出结果的共识。

1.3 统一视角(Unified Perspectives)
尽管“推理扩展(inference scaling)”与“学习推理(learning to reason)”采用了不同方法,但它们本质上是互补且可统一的: * 推理扩展专注于选出最优推理路径; * 学习推理则利用“好路径”和“坏路径”作为训练数据,以强化推理能力。
我们从两个关键视角统一这两类方法: 1. 输入视角(Input Level): 修改或增强提示,以引导模型朝着期望的推理方向前进。 1. 输出视角(Output Level): 模型生成多个候选输出,再进行评估、排序或精炼。
这种框架揭示出:许多推理扩展技术(如提示修改或路径搜索)也可用于生成用于学习的推理轨迹。反过来,学习到的推理模型也可受益于测试时的推理扩展策略,这激发了“面向推理扩展的学习推理方法”的研究(见第5.4节)。 这一统一视角同样适用于不同架构: * 对于独立式 LLM,我们继续采用“输入/输出”的范式; * 对于单智能体系统:
输入被视为“感知”(perception); * 输出则为“行动”(action); * 对于多智能体系统:
输入是“通信”(communication); * 输出是“协调行动”(coordination)。
这种类比为不同机制与架构之间建立了统一认知框架,提供了可系统化与可泛化的 LLM 推理分析工具(详见图2)。
1.4 本综述的目标与结构(Goal and Structure of the Survey)
本综述旨在提供一个系统全面的视角,梳理自思维链(CoT)提出以来,LLM 推理研究中的关键算法细节与代表性成果,覆盖机制维度与架构维度。 随着 2022 年 CoT 的提出(见图1),相关研究显著加速,本文也正是基于这一趋势,对从机制、架构到学习算法等多个维度的最新进展进行总结。 图2 展示了本综述的总体分类框架,两大维度下分别包含两个关键视角: * 输入/感知/通信(input / perception / communication): 包括提示构造、环境感知信息的整合,以及智能体间的通信协议设计; * 输出/行动/协调(output / action / coordination): 涉及输出整合、行为优化,以及跨智能体协调动作生成。
图3 描绘了本综述的整体结构。我们将从第2节开始介绍背景内容,包括术语定义、组件、机制与架构。之后依次展开: * 第3节:推理扩展; * 第4节:推理器与验证器的学习算法; * 第5节:学习推理;
三类架构在其中均被覆盖:独立 LLM、单智能体、与多智能体系统; * 第6节:总结与未来挑战。
1.5 与已有综述的比较(Comparison to Related Surveys)
LLM 推理长期以来被视为 AI 研究中的基础性难题。已有综述的核心关注点包括: * 非形式逻辑推理:Huang & Chang(2023)系统梳理了 LLM 代理系统之前的推理演化; * 提示工程:Qiao 等(2023b)专注于提示技巧对推理性能的提升; * 自然语言推理的形式定义与分类:Yu 等(2024a)强调其哲学基础与现实应用之间的联系。
在技术路径上: * Dong 等(2024)对**上下文学习(ICL)**进行了全面回顾; * Zhou 等(2024b)从理论与实证角度剖析 ICL; * Welleck 等(2024)聚焦于三类生成算法:token 级、元生成与高效生成。
随着 RLMs(如 OpenAI 的 o1 与 DeepSeek 的 R1)的发布,“学习推理”逐渐成为主流方向: * Zeng 等(2024)、Xu 等(2025c)全面总结了此类方法; * Liu 等(2025a)专门探讨了形式逻辑推理; * Yang 等(2024d)强调数学推理的自动化、可验证性与挑战; * Pezeshkpour 等(2024a)探讨了多智能体系统中的推理定义与结构。
Besta 等(2025)提出了模块化的 RLM 框架,覆盖推理结构、策略、基准与学习算法,但未涉及 agentic 与多智能体系统。 此外,尽管已有众多关于 agent 系统的综述(Xi 等,2023;Kapoor 等,2024),但很少专注于这些系统中的推理机制。 因此,本综述将重点聚焦以下两大方向: 1. 推理机制演化:从“推理扩展”到“学习推理”; 1. 系统架构演进:从“独立 LLM”到“多智能体系统”。
在此框架下,我们统一讨论输入/输出视角下的核心技术,明确构建推理系统时应定制与设计的关键组件,并比较多种最新学习算法(如 RL),深入分析精炼器(refiners)与验证器(verifiers)的作用。 我们认为本综述恰逢其时,可为 AI 研究者提供最新的洞察,未来有望延伸至更广泛的研究维度,例如人机协作模式(Liang 等,2024)与自动化工作流设计(Hu 等,2025;Zhang 等,2024c;Zhou 等,2025)。
