![]()
近年来,以ChatGPT为代表的能够适应复杂场景、并能满足人类的各种应用需求为目标的文本生成算 法模型成为学术界与产业界共同关注的焦点 . 然而,ChatGPT等大规模语言模型(Large Language Model,LLM)高度忠 实于用户意图的优势隐含了部分的事实性错误,而且也需要依靠提示内容来控制细致的生成质量和领域适应性,因 此,研究以内在质量约束为核心的文本生成方法仍具有重要意义. 本文在近年来关键的内容生成模型和技术对比研 究的基础上,定义了基于内在质量约束的文本生成的基本形式,以及基于“信、达、雅”的6种质量特征;针对这6种质量 特征,分析并总结了生成器模型的设计和相关算法;同时,围绕不同的内在质量特征总结了多种自动评价和人工评价 指标与方法. 最后,本文对文本内在质量约束技术的未来研究方向进行了展望.
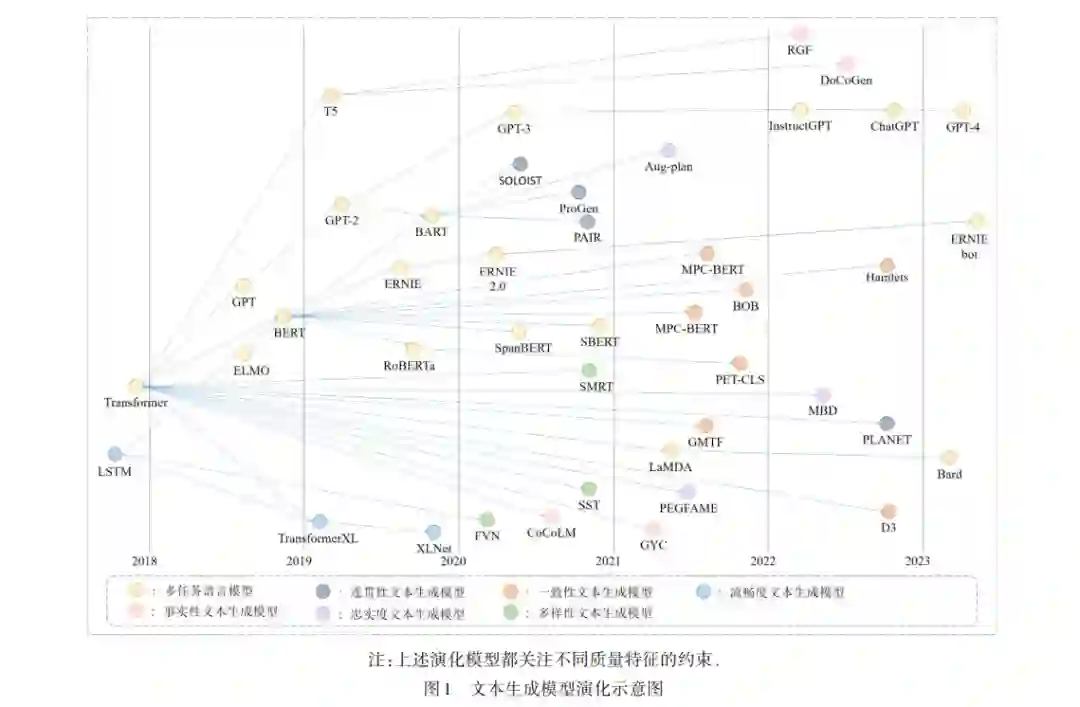
![]() 2022 年 11 月 30 日,由 OPENAI 实验室推出的一款 基于 GPT3.5的内容生成工具 ChatGPT[1,2] ,通过进一步 提升模型的记忆能力与文本理解能力,使其自动生成 的问题解答、软件代码、数学计算和信件内容等结果, 不仅具备优秀的内容完整性和逻辑性,而且能够符合 用户偏好并实现场景的自适应性,从而引起了学术界 和工业界的广泛关注,并使基于人工智能的内容生成 技术(AI Generate Content,AIGC)成为目前 AI 技术领 域中热议的焦点之一[3,4] . AIGC 技术的核心是通过 AI 算法自动化地生成满足特定目标和质量要求的文本 内容,生成文本不仅需要符合图灵假设[5] ,而且应当满 足人们在浏览信息时所需要的“信(Credible)、达(Ex⁃ pressiveness)、雅(Elegance)”的质量需求[6] . 目前,以 GPT-3 [3] ,T5 [7] 和 GPT-4 [8] 为核心的大规模预训练语言 模 型(Large Language Model,LLM)不 仅 具 有 的 层 数 多、参数量大的结构特点,而且通过海量语料的训 练,具有很强的理解能力和泛化能力,逐渐成为 AIGC 技术的主流 . 但是,相比 LLM 聚焦不同外在环境和任 务的普适性,如何提升语言模型所生成文本的内在 质量以符合特定领域的质量需求,迫切需要开展深入 的研究. 近年来语言生成模型的技术演化路线如图1所示. 其中,Google 和 OpenAI 的研究者在早期基于多头注意 力机制的Transformer[9] 模型基础上,通过增加预训练子 任务或改进解码器结构,分别提出了用于自然语言理 解任务的 BERT 模型[10] 和适应多种任务的自回归模型 GPT[11] . 此后预训练语言模型出现了两个重要分支: 一是以 GPT-2 [12] ,GPT-3 [3] ,T5 [7] 和 GPT-4 [8] 为代表的自 回归模型采用了更加丰富的训练语料和更加庞大的 参数,进一步增强了 LLM 在多种不同生成任务中的性 能 与 泛 化 性 ;二 是 以 RoBERTa[13],SpanBERT[14]和 SBERT[15]为代表的改进模型通过改进掩码机制和预 训练子任务,进一步提升了 BERT 模型的编码性能和 应用领域 . 同一时期,基于循环机制和双流自注意力 的 TransformerXL[16]和 XLNet[17]等预训练模型在生成 长文本的同时,通过生成质量控制保持了上下文语义 的流畅性;而融合了 BERT 编码能力和 GPT-2 生成优 势的 BART 模型[4] 能够通过输入不同的关键字来控制 生成文本的内容语义 . 为了生成更加连贯的长文本内 容,Tan 等人[18] 基于 BART 构建了多步骤生成模型 Pro⁃ Gen,通过在多步生成过程中采用不同的触发词,有效 控制了长文本生成中内容语义的连贯性,并在基于 CNN新闻数据集的实验结果表明,相对于BART模型的 BLEU 值 30.1%,ProGen模型提升到了 31.2%. 而 Hua等 人[19] 从语义连贯性与动态语义的演化特征出发,提出 了连贯性生成模型 PAIR,它将文本计划作为生成模型 的输入以控制输出文本的整体脉络,从而保证了输出 内容具有更加平滑的语义变化和连贯性,在针对 Red⁃ dit 数据集的测试中发现,相比 BART 模型的 BLEU 值 6.78%,PAIR 的 BLEU 值提升至 36.09%. Jang 等人[20] 为了增强对话任务中回复内容的角色一致性,提出 的模型将 BART 模型作为生成器的主体结构,采用 角色和知识的独立编码以增强回复文本中的属性表 达,该模型在 FoCus 数据集上测试结果为 46.31%,比 BART 模型的 BLEU 值 13.18% 大幅提升 . 上述工作 表明,从不同的质量特征上来优化内容生成模型的 结构,均可获得较 BART 模型更优的结果,因此,在 各种大语言模型不断推新的场景下,从质量特征的 视角来进行模型优化,仍然具有的重要的研究价值 和意义. 围绕着生成更准确[21,22] 、更真实[23,24] 、更细致[25~27] 、 更可靠[28,29] 的高质量文本内容,大量学者从不同的视 角对AIGC领域中的关键技术问题进行了综述研究. 其 中,Iqbal 等人[30]在 CNN,RNN,LSTM 等经典模型的基 础上,深入分析和对比了基于 VAE和 GAN等生成模型 的差异,发现传统语言模型无法控制不同文本质量中 的细微差别 . Li 等人[31] 则从预训练语言模型和微调机 制出发,从“相关性、忠实度、保序性”等质量维度来分 析不同类型的输入数据如何自适应地生成满足特定质 量要求的文本,但是这些工作缺少探索所选特性的可 泛化能力,导致一些质量特征仅限于特定的任务. 在生 成文本的可靠评价角度上,Celikyilmaz 等人[32] 从人工 评价方法、非训练的自动评价算法和机器学习的评价 模型等方向出发,系统讨论了生成文本的评价方法与 指标体系 . 而 Jin 等人[33] 关注文本风格迁移任务,特别 是围绕着风格迁移强度、语义保存性和流畅度等特征 深入研究了自动评价和人工评价方法. 然而,现有的评 价方法依然偏向于特定的生成任务,缺乏一个以质量 特征为核心主线的内容评价框架. 综上所述,在考虑到不同研究工作之间关注焦点 存在的差异性,本文在梳理和对比与已有研究综述 在 AIGC 核心问题与工作挑战的基础上(表 1),从质 量约束与控制的视角出发,对 AIGC 中高质量文本内 容生成进行形式化定义,进而围绕不同的质量特征 与任务分析相关技术、模型的研究进展,对未来的发 展趋势进行分析和总结,为未来的研究奠定基础和 指引.
2022 年 11 月 30 日,由 OPENAI 实验室推出的一款 基于 GPT3.5的内容生成工具 ChatGPT[1,2] ,通过进一步 提升模型的记忆能力与文本理解能力,使其自动生成 的问题解答、软件代码、数学计算和信件内容等结果, 不仅具备优秀的内容完整性和逻辑性,而且能够符合 用户偏好并实现场景的自适应性,从而引起了学术界 和工业界的广泛关注,并使基于人工智能的内容生成 技术(AI Generate Content,AIGC)成为目前 AI 技术领 域中热议的焦点之一[3,4] . AIGC 技术的核心是通过 AI 算法自动化地生成满足特定目标和质量要求的文本 内容,生成文本不仅需要符合图灵假设[5] ,而且应当满 足人们在浏览信息时所需要的“信(Credible)、达(Ex⁃ pressiveness)、雅(Elegance)”的质量需求[6] . 目前,以 GPT-3 [3] ,T5 [7] 和 GPT-4 [8] 为核心的大规模预训练语言 模 型(Large Language Model,LLM)不 仅 具 有 的 层 数 多、参数量大的结构特点,而且通过海量语料的训 练,具有很强的理解能力和泛化能力,逐渐成为 AIGC 技术的主流 . 但是,相比 LLM 聚焦不同外在环境和任 务的普适性,如何提升语言模型所生成文本的内在 质量以符合特定领域的质量需求,迫切需要开展深入 的研究. 近年来语言生成模型的技术演化路线如图1所示. 其中,Google 和 OpenAI 的研究者在早期基于多头注意 力机制的Transformer[9] 模型基础上,通过增加预训练子 任务或改进解码器结构,分别提出了用于自然语言理 解任务的 BERT 模型[10] 和适应多种任务的自回归模型 GPT[11] . 此后预训练语言模型出现了两个重要分支: 一是以 GPT-2 [12] ,GPT-3 [3] ,T5 [7] 和 GPT-4 [8] 为代表的自 回归模型采用了更加丰富的训练语料和更加庞大的 参数,进一步增强了 LLM 在多种不同生成任务中的性 能 与 泛 化 性 ;二 是 以 RoBERTa[13],SpanBERT[14]和 SBERT[15]为代表的改进模型通过改进掩码机制和预 训练子任务,进一步提升了 BERT 模型的编码性能和 应用领域 . 同一时期,基于循环机制和双流自注意力 的 TransformerXL[16]和 XLNet[17]等预训练模型在生成 长文本的同时,通过生成质量控制保持了上下文语义 的流畅性;而融合了 BERT 编码能力和 GPT-2 生成优 势的 BART 模型[4] 能够通过输入不同的关键字来控制 生成文本的内容语义 . 为了生成更加连贯的长文本内 容,Tan 等人[18] 基于 BART 构建了多步骤生成模型 Pro⁃ Gen,通过在多步生成过程中采用不同的触发词,有效 控制了长文本生成中内容语义的连贯性,并在基于 CNN新闻数据集的实验结果表明,相对于BART模型的 BLEU 值 30.1%,ProGen模型提升到了 31.2%. 而 Hua等 人[19] 从语义连贯性与动态语义的演化特征出发,提出 了连贯性生成模型 PAIR,它将文本计划作为生成模型 的输入以控制输出文本的整体脉络,从而保证了输出 内容具有更加平滑的语义变化和连贯性,在针对 Red⁃ dit 数据集的测试中发现,相比 BART 模型的 BLEU 值 6.78%,PAIR 的 BLEU 值提升至 36.09%. Jang 等人[20] 为了增强对话任务中回复内容的角色一致性,提出 的模型将 BART 模型作为生成器的主体结构,采用 角色和知识的独立编码以增强回复文本中的属性表 达,该模型在 FoCus 数据集上测试结果为 46.31%,比 BART 模型的 BLEU 值 13.18% 大幅提升 . 上述工作 表明,从不同的质量特征上来优化内容生成模型的 结构,均可获得较 BART 模型更优的结果,因此,在 各种大语言模型不断推新的场景下,从质量特征的 视角来进行模型优化,仍然具有的重要的研究价值 和意义. 围绕着生成更准确[21,22] 、更真实[23,24] 、更细致[25~27] 、 更可靠[28,29] 的高质量文本内容,大量学者从不同的视 角对AIGC领域中的关键技术问题进行了综述研究. 其 中,Iqbal 等人[30]在 CNN,RNN,LSTM 等经典模型的基 础上,深入分析和对比了基于 VAE和 GAN等生成模型 的差异,发现传统语言模型无法控制不同文本质量中 的细微差别 . Li 等人[31] 则从预训练语言模型和微调机 制出发,从“相关性、忠实度、保序性”等质量维度来分 析不同类型的输入数据如何自适应地生成满足特定质 量要求的文本,但是这些工作缺少探索所选特性的可 泛化能力,导致一些质量特征仅限于特定的任务. 在生 成文本的可靠评价角度上,Celikyilmaz 等人[32] 从人工 评价方法、非训练的自动评价算法和机器学习的评价 模型等方向出发,系统讨论了生成文本的评价方法与 指标体系 . 而 Jin 等人[33] 关注文本风格迁移任务,特别 是围绕着风格迁移强度、语义保存性和流畅度等特征 深入研究了自动评价和人工评价方法. 然而,现有的评 价方法依然偏向于特定的生成任务,缺乏一个以质量 特征为核心主线的内容评价框架. 综上所述,在考虑到不同研究工作之间关注焦点 存在的差异性,本文在梳理和对比与已有研究综述 在 AIGC 核心问题与工作挑战的基础上(表 1),从质 量约束与控制的视角出发,对 AIGC 中高质量文本内 容生成进行形式化定义,进而围绕不同的质量特征 与任务分析相关技术、模型的研究进展,对未来的发 展趋势进行分析和总结,为未来的研究奠定基础和 指引.