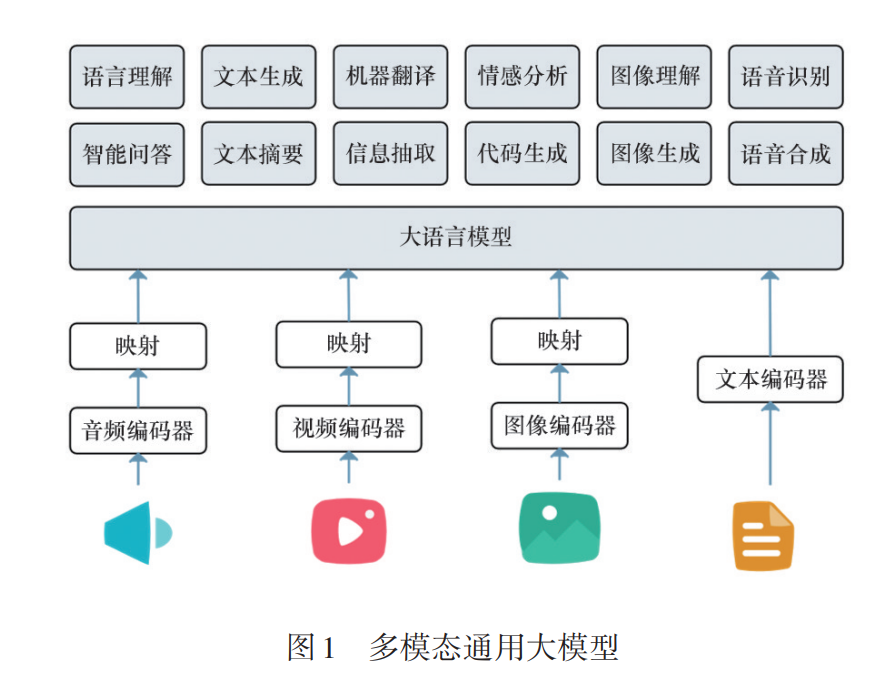
随着人工智能技术的飞速发展,通用大模型(GLMs)已经成为人工智能领域的重要研 究方向。通用大模型拥有超大规模参数,通过大规模数据进行训练,具备强大的学习和推理 能力。这些模型在自然语言处理、图像识别、代码生成等多种任务中展现出卓越的能力。回 顾了通用大模型的发展历程,梳理关键技术节点,从早期基于规则的系统和传统机器学习模 型,到深度学习的崛起,再到 Transformer 架构,以及 GPT 系列及国内外通用大模型的进展。 尽管GLMs在多个领域取得了显著进展,但其发展也面临诸多挑战,包括计算资源需求、数据 偏见与伦理问题及模型的解释性与透明性。分析了这些挑战,并探讨了GLMs未来发展的5 个关键方向:模型优化、多模态学习、具情感大模型、数据与知识双驱动以及伦理与社会影 响。通过这些策略,通用大模型有望在未来实现更广泛和深入的应用,推动人工智能技术的 持续进步。随着人工智能技术的飞速发展,通用大模型 (general large models,GLMs)已经成为人工智能领 域的重要研究方向,通常具备以下特点。 1)大规模。通用大模型通常拥有大量的参 数,从几十亿至上千亿参数不等,通过大规模数据 进行训练,从而具备强大的学习和推理能力。 2)预训练—微调。通用大模型通常采用预训 练和微调的策略。首先在大规模未标注数据上进 行无监督或自监督预训练,然后通过有监督的微调 适应特定任务。 3)通用性。通用大模型具备广泛的适用性, 可以处理不同类型的数据和任务,如文本、图像、音 频等。 4)多模态。一些通用大模型能够处理多种模 态的数据,如文本与图像结合,体现了广泛的应用 潜力(图1)。 5)高度复杂。由于拥有大量参数和复杂的架 构,通用大模型具备强大的表现力和学习能力,但 是,同时也面临着计算资源需求高、模型解释性差 等挑战。通用大模型为实现更高级的理解、交互和生成 任务提供了可能,被广泛认为是推动人工智能技术 向通用智能发展的关键因素[1] 。自生成式预训练变 换器(generative pre-trained transformer,GPT)系列 模型问世以来,这一领域取得了长足的进步。随着 以GPT为代表的大模型不断涌现,研究人员已深刻 认识到通用大模型不仅代表着当今人工智能技术 的前沿,更预示着未来智能系统的发展方向。 通用大模型的发展得益于深度学习的进步以 及计算能力的提升。Transformer架构的引入,打破 了传统循环神经网络在处理长序列任务时的瓶颈, 开启了大规模预训练模型的时代。GPT 系列模型 进一步展现了通过大规模预训练来学习通用知识 的潜力,为实现通用人工智能(artificial general in⁃ telligence,AGI)奠定了基础。 本文探讨通用大模型的演进路线,分析其发展 历程、面临的挑战及未来可能的方向。