
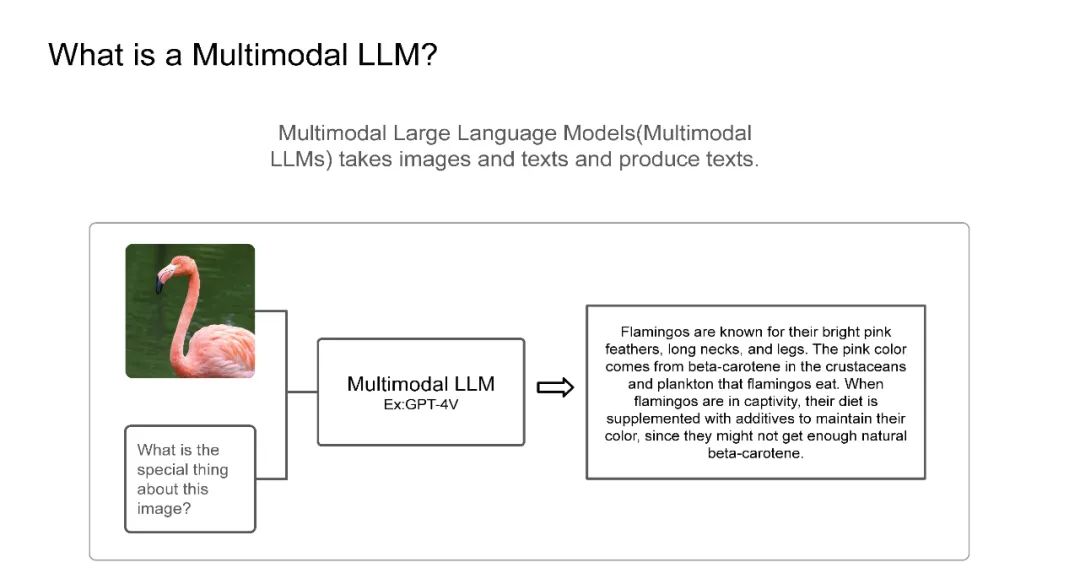
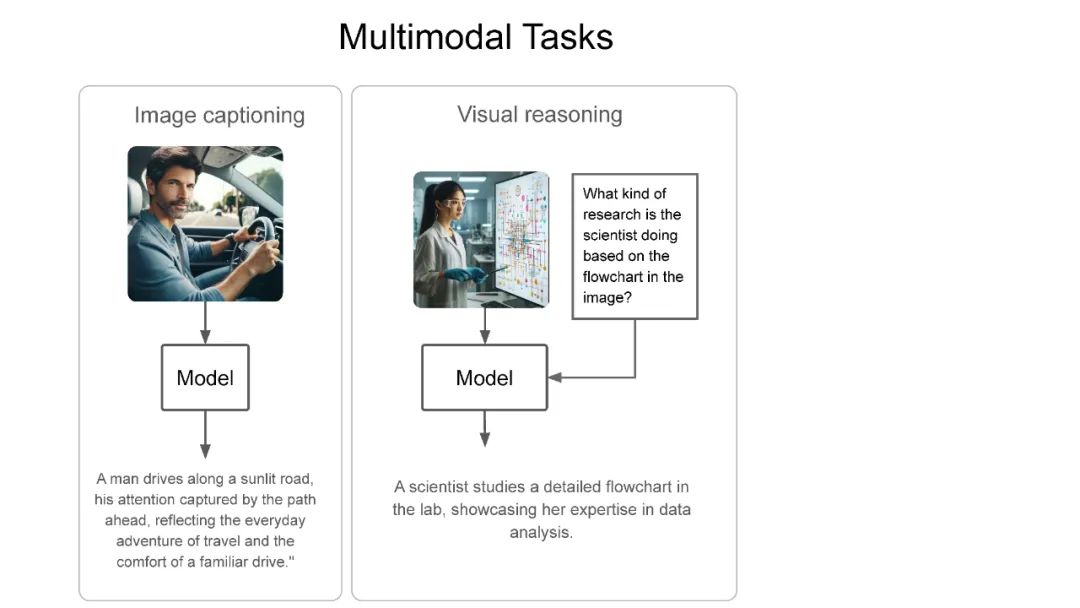
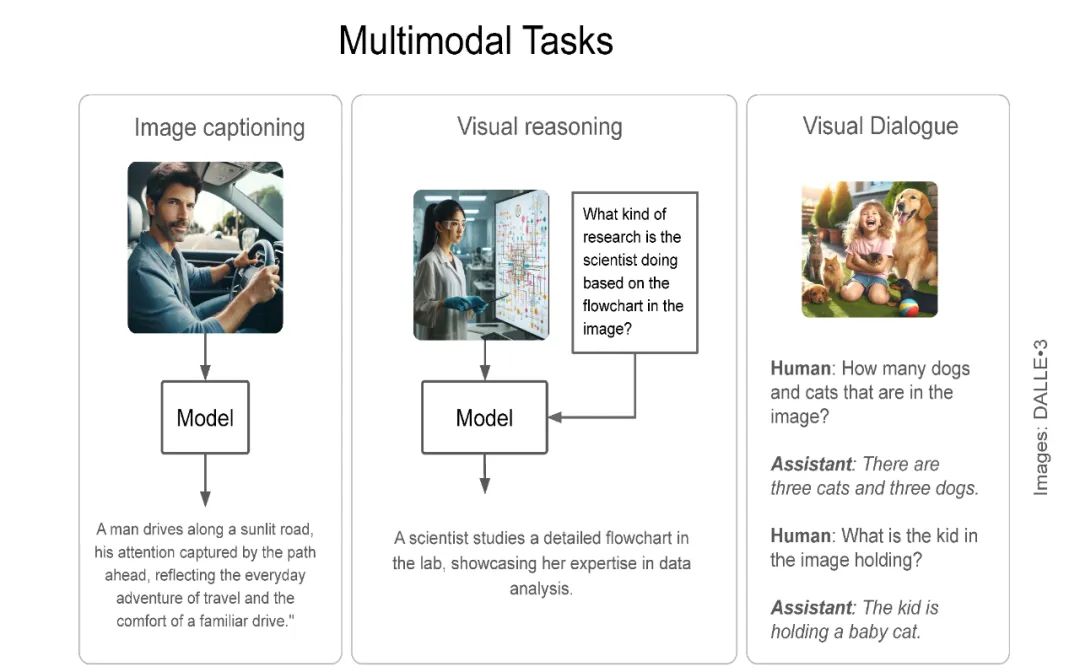
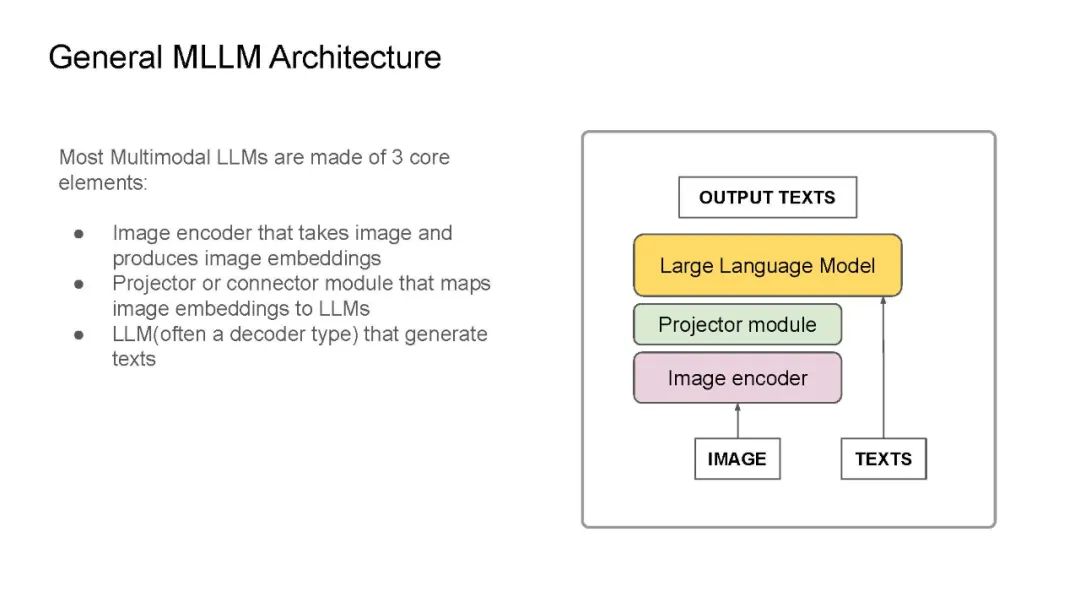
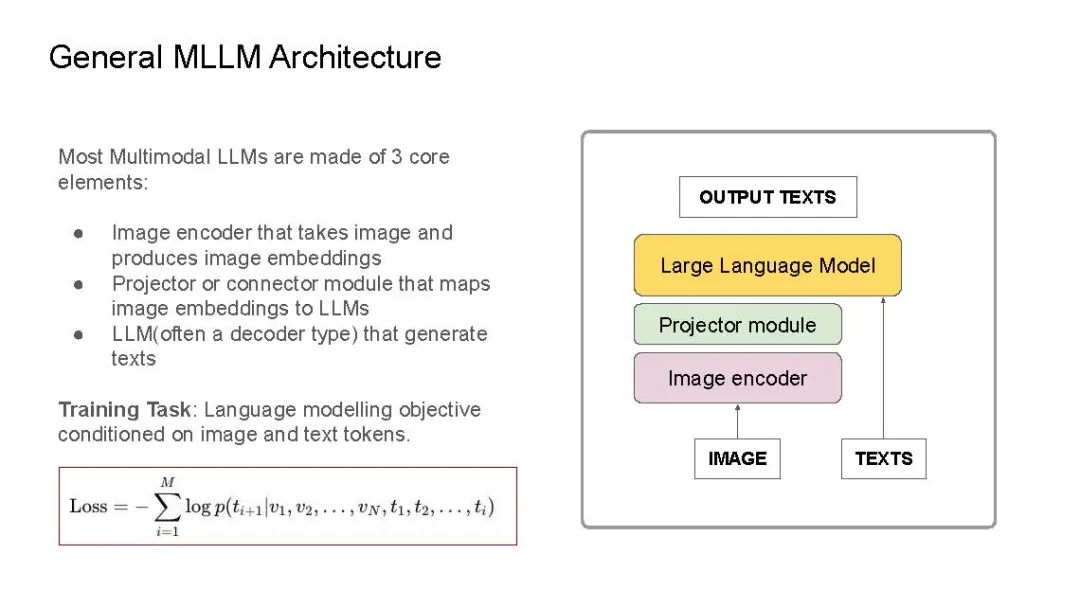
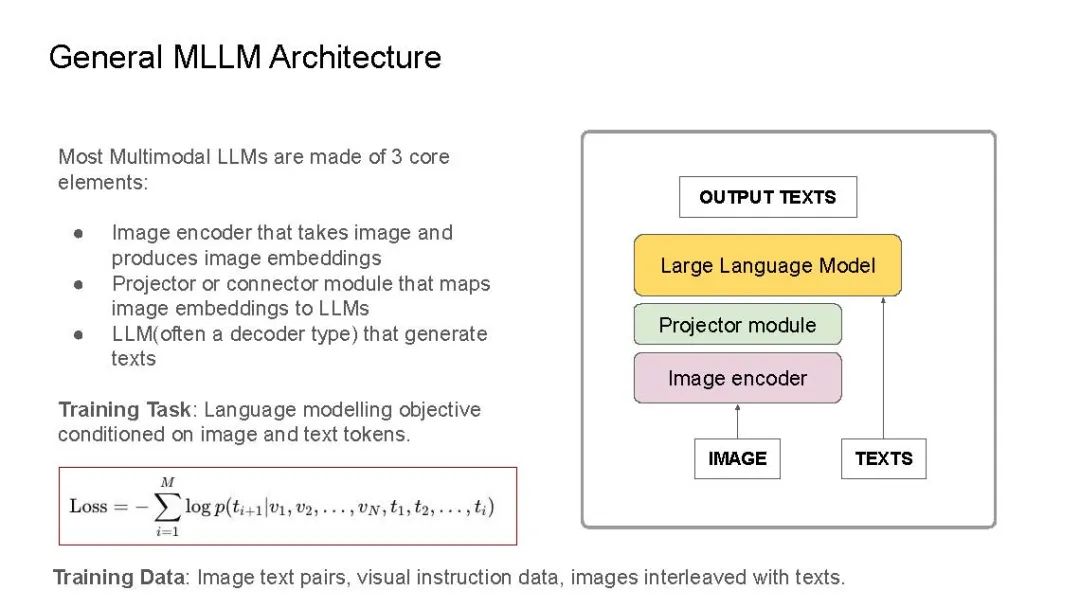
最近,我在IndabaX Rwanda和卡内基梅隆大学(学号为18-661)的“工程师机器学习导论”课程中的学生研究讲座上进行了关于多模态大语言模型(LLM)的演讲。在演讲中,我们详细剖析了多模态LLM、多模态任务以及一般的多模态LLM架构。大多数多模态LLM几乎都有非常相似的架构:视觉编码器用于获取图像嵌入(如CLIP-ViT或SigLIP),连接器/投影器用于将图像标记映射到LLM维度空间(例如:线性层/MLP/注意力层),以及用于生成的底层LLM(通常是解码器类型的语言模型)。我们还介绍了一些代表性模型:CLIP为基础奠定了基础,Flamingo启发了图像-文本交错和视觉语言模型中的上下文学习,LLaVA引入了视觉指令调优,在许多多模态基准测试中实现了最先进的性能。最后,我们讨论了基准测试、开源模型与闭源模型的对比、当前的挑战以及我对多模态LLM的期望清单。

成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日