
近日,湖南大学DrugAI实验室在Nature子刊《Nature Machine Intelligence》上发表名为”Accurate prediction of molecular properties and drug targets using a self-supervised image representation learning framework”的研究论文,提出了一种全新的分子表征框架——基于分子图像的自监督深度学习框架ImageMol。它通过在1000万个未标记的类药生物活性分子上进行预训练,实现了对分子性质和药物靶标的准确预测,开创了分子表征学习的新范式。

简介
药物的临床疗效和安全性往往取决于药物分子的性质和人体内的靶点,但通过人工的方式对人类甚至动物模型中的所有化合物进行蛋白质组范围内的评估是具有挑战性的,而人工智能技术可以加速这一过程。
近些年,随着自然语言处理(NLP)中无监督学习的兴起,将无监督学习与基于序列和图(graph)的表征相结合的方法已被广泛用于各种计算药物发现任务。然而,它们在提取信息载体以描述分子特性方面都存在一定的局限性。
在计算机视觉中无监督的最新进展下,本文开发了一个具有化学意识的无监督分子图像预训练框架——ImageMol,用于从大规模分子图像中学习分子结构。ImageMol将图像处理框架与综合分子化学知识相结合,以可视化计算的方式提取精细像素级分子特征,在各种药物发现任务中演示了ImageMol的高准确性,为计算药物发现提供了一个强大的预训练深度学习框架。
与其他先进的方法相比,ImageMol有两个显著的改进:
它利用分子图像作为化合物的特征表示,具有高精度和低计算成本; * 它利用一个无监督的预训练学习框架,从1000万个具有人类蛋白质组不同生物活性的类药物化合物中捕获分子图像的结构信息。
方法
ImageMol的整体架构如下图所示,总共分为三部分,具体如下:
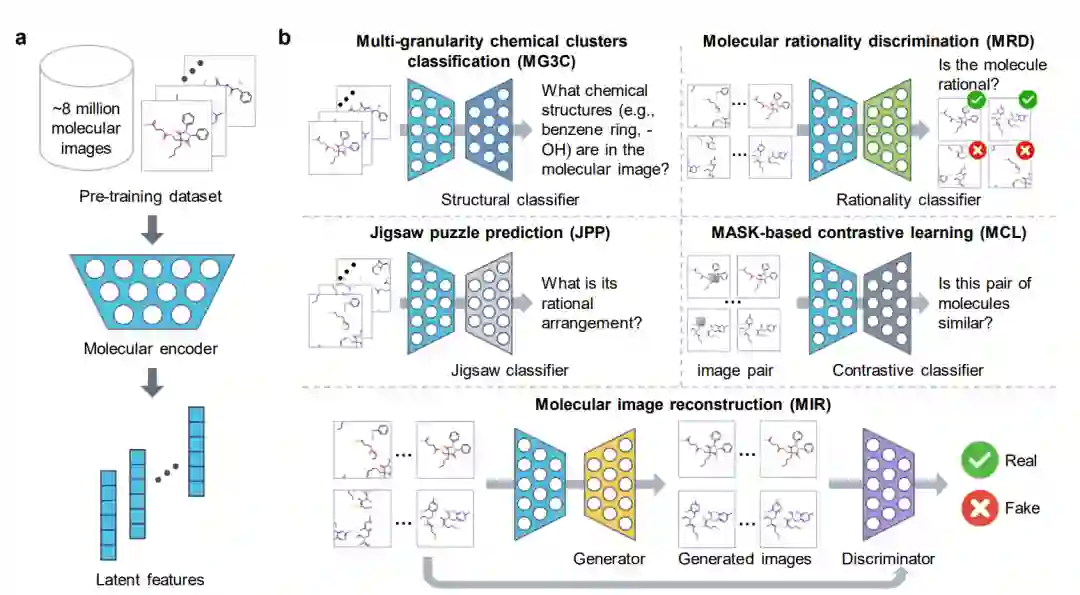
(1) 分子编码器molecular encoder**(浅蓝色)能够**从约1000万张分子图像中提取潜在特征 (a) 。 (2)五个预训练策略(MG3C、MRD、JPP、MCL、MIR)利用分子图像中的化学知识和结构信息来优化分子编码器的潜在表示 (b) 。五种预训练策略为: ① MG3C(Muti-granularity chemical clusters classification 多粒度化学簇分类):其中的结构分类器Structure classifier(深蓝色)用于预测分子图像中的化学结构信息; ② MRD(Molecular rationality discrimination 分子合理性鉴别器):其中的合理性分类器Rationality classifier(绿色)用于区分合理和不合理分子; ③ JPP(Jigsaw puzzle predicition 拼图预测):其中的拼图分类器Jigsaw classifier(浅灰色)用于预测分子的合理排列; ④ MCL(MASK-based contrastive learning 基于MASK的对比学习):其中的对比分类器Contrastive classifier(深灰色)用于最大化原始图像和mask图像之间的相似性; ⑤ MIR(Molecular image reconstruction 分子图像重建):其中的生成器Generator(黄色):用于将潜在特征恢复为分子图像,鉴别器Discriminator(紫色)用于区分真实图像和生成器生成的假的分子图像。 (3)对预训练的分子编码器在下游任务中微调,以进一步提高模型性能 (c) 。
实验
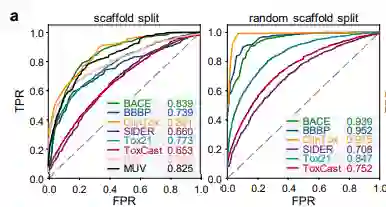
基准评估 作者首先使用8种药物发现的基准数据集来评估ImageMol的性能,并且使用两种最流行的拆分策略(scaffold split与random scaffold split)来评估 ImageMol 在所有基准数据集上的性能。在分类任务中,利用受试者工作特征(receiver operating characteristic, ROC)曲线下面积AUC值来评估,从实验结果可以看出,ImageMol均能得到较高的AUC值 (图a) 。
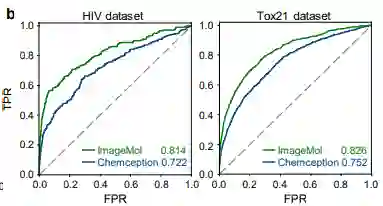
ImageMol与最先进的卷积神经网络(CNN)框架Chemception在HIV和Tox21的检测结果对比 (图b) ,ImageMol的AUC值更高。并且在进行ImageMol模型与Chemception、ADMET-CNN和QSAR-CNN三种先进模型在CYP1A2, CYP2C9 , CYP2C19, CYP2D6 和 CYP3A4 的对比中 (图c) ,ImageMol的AUC值均处于最高值。

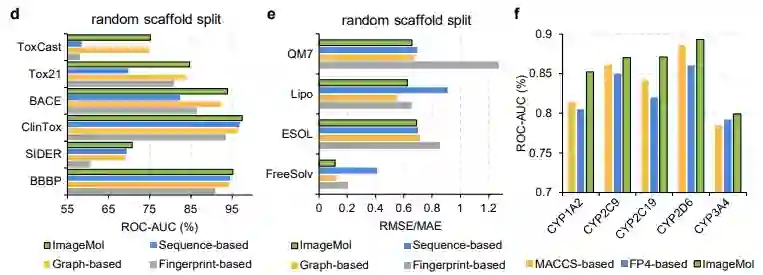
ImageMol与使用随机支架分割的基于指纹的模型(如AttentiveFP)、基于序列的模型(如TF_Robust)和基于图的模型(如N-GRAM、GROVER和MPG)相比具有更好的性能,如图 d和e所示 。此外,与传统的基于MACCS的方法和基于FP4的方法相比,ImageMol在CYP1A2,CYP2C9,CYP2C19,CYP2D6和CYP3A4上实现了更高的AUC值(图f)。
ImageMol与基于序列的模型(包括RNN_LR、TRFM_LR、RNN_MLP、TRFM_MLP、RNN_RF、TRFM_RF和CHEM-BERT)和基于图的模型(包括MolCLRGIN、MolCLRGCN和GROVER)相比,如图(g),ImageMol在CYP1A2、CYP2C9、CYP2C19、CYP2D6、CYP3A4上实现了更好的 AUC 性能。
在以上ImageMol与其他先进的模型对比中,可以看出ImageMol的优越性。
自新冠疫情爆发以来,我们迫切需要为新冠疫情制定有效的抗病毒治疗策略。因此,作者在该方面对ImageMol做了相应的评估。
对13个SARS-CoV-2靶点的抗病毒活性进行预测 ImageMol对现如今关注的热点病毒SARS-CoV-2进行了预测实验,在13个SARS-CoV-2生物测定数据集中,ImageMol实现了72.6%至83.7%的高AUC值。图(a)揭示了通过ImageMol鉴定的潜在特征,它在13个靶点(target)或终点(endpoints)活性和无活性的抗SARS-CoV-2上很好的聚集,且AUC值均比另一种模型Jure’s GNN要高12%以上 ,体现出该模型的高精度和很强的泛化性。
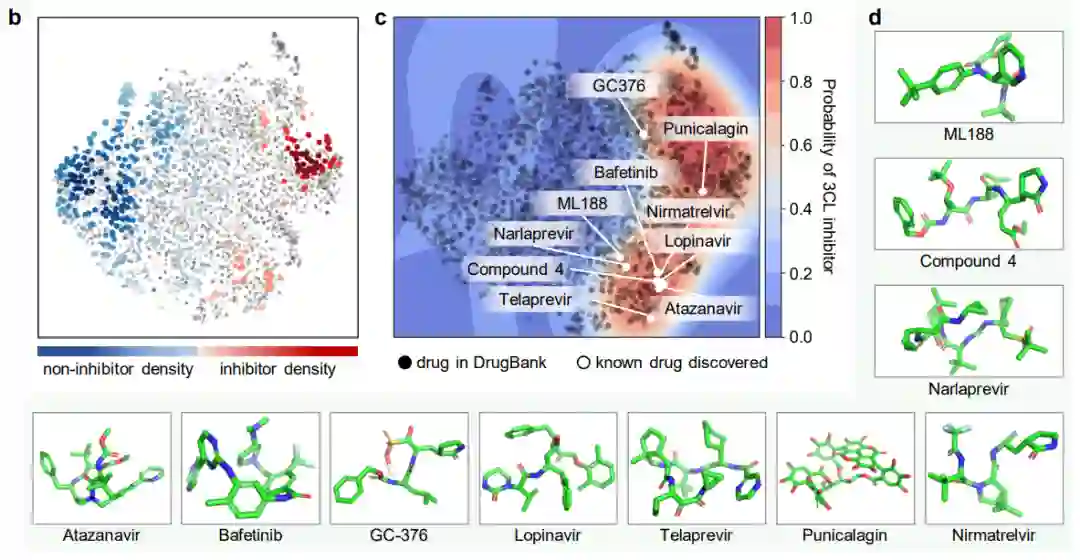
识别抗SARS-CoV-2抑制剂 对药物分子研究关乎最直接的实验来了,利用ImageMol直接识别病毒抑制剂分子!通过ImageMol框架下3CL蛋白酶(已被证实是治疗COVID-19的有希望的治疗发展靶点)抑制剂与非抑制剂数据集的分子图像表示,我们发现3CL抑制剂和非抑制剂在t-SNE图中很好地分离,如下图 (b) 。
另外,ImageMol鉴定出16种已知3CL蛋白酶抑制剂中的10种,并将这10种药物可视化到图中的t-SNE空间(成功率62.5%),表明在抗SARS-CoV-2药物发现中具有较高的泛化能力。使用HEY293测定来预测抗SARS-CoV-2可再利用药物时,ImageMol成功预测了70种药物中的42种(成功率为60%),这表明ImageMol在推断HEY293测定中的潜在候选药物方面也具有很高的推广性 (如图c和d) 。
注意力可视化 ImageMol可以从分子图像表示中获取化学信息的先验知识,包括=O键、-OH键、-NH3键和苯环 (a) 。图b和c为ImageMol的Grad-CAM可视化的12个示例分子。这表示ImageMol同时准确地对全局 (b) 和局部 (c) 结构信息进行注意力捕获,这些结果使研究人员能够在视觉上直观地理解分子结构是如何影响性质和靶点。
消融分析 模型的鲁棒性对超参数很重要,因为不同的超参数会影响模型的性能。作者探讨了使用不同数据规模进行预训练的影响,发现随着预训练数据大小的增加,ROC-AUC的平均性能从 1.2%增加到10.2%。由于可以预先训练更多的类似药物的分子,因此可以通过将来从更大的类似药物的化学数据集进行预训练来进一步改进模型。 总结
作者提出了一个基于无监督分子图像预训练框架ImageMol,该框架将图像处理框架与全面的分子知识相结合,以可视化计算的方式提取精细像素级的分子特征。证明了ImageMol在具有各种药物发现任务的多个基准生物医学数据集中的高精度。
最重要的是,ImageMol不仅在美国国家转化科学推动中心(NCATS)发布的13个实验数据集中准确识别了抗SARS-CoV-2分子,还在美国FDA批准的2501种药物中成功预测了潜在治疗新冠肺炎的3CL蛋白酶抑制剂。这表明该预训练分子图像学习框架必将成为快速药物发现的强大工具之一。 参考资料 Zeng, X., Xiang, H., Yu, L. et al. Accurate prediction of molecular properties and drug targets using a self-supervised image representation learning framework. Nat Mach Intell (2022). https://doi.org/10.1038/s42256-022-00557-6

