
编译 | 任宣百 审稿 | 刘名权 本文介绍由瑞典分子人工智能研究所的Atanas Patronov团队发表在Nature Machine Intelligence的研究成果。作者将课程学习应用于药物发现中。在全新的设计平台中实现课程学习(CL),并将其应用于不同复杂性的分子设计问题中。结果表明,与标准的基于策略的强化学习相比,课程学习能够加速学习效率和优化模型输出的质量。

1 简介 分子设计需要在化学空间中进行多参数优化(MPO)搜索,估计在1023-1060个分子的范围内。之前的分子设计方法有虚拟筛选(VS)等,但随着深度学习的兴起,深度学习已逐渐替代VS方法。深度学习与依赖于枚举分子的方法相比,可以在更大的化学空间中进行采样。
使用基于策略的强化学习(RL)、基于价值的RL、学习分子潜在空间,以及其他方法(树搜索和遗传算法)的深度生成模型已经被提出来设计具有期望特性的分子。在基于策略的RL中,agent(生成模型)学习策略(在给定状态下采取的一系列行动)来产生最大化奖励的分子,这是根据预定义的奖励函数计算出来的。通常,基于物理的结合亲和力相似方法,例如分子docking,把它作为奖励函数的一个组成部分,来设计具有更强预测活性的分子。给定足够长的训练时间,这些模型可以学习生成满足所需的MPO目标的分子。然而,由于复杂的奖励函数难以找到最小值,在这种情况下,agent可能会从化学空间中远离预期目标的区域进行多次采样。因此,基于策略的RL对于复杂的MPO目标是不可行的,从而导致计算资源的次优分配,且最终合成结果为次优分子。
在这项工作中,作者在从头开始的分子设计平台REINVENT的基础上,引入了CL方法,用于解决基于策略的RL任务中存在的问题,使用CL扩展了REINVENT对复杂奖励函数的适用性。作者通过设计3-磷酸肌酸依赖性蛋白激酶-1(PDK1)的案例研究来证明CL在REINVENT中的有效性。作者表明,与基于策略的RL相比,CL可以规避高计算成本。此外,课程提供了一种自然的方法,例如,课程中的微小改变可以引导分子设计,以一种可预测的方式控制结果的质量和多样性。
2 结果 CL概述 在CL中,将一个复杂的任务分解为更简单的组成任务,以加速训练和收敛。其目标是在提供生成目标之前,指导agent去学习越来越复杂的任务。agent学习从课程阶段一直进行到生成阶段,并由课程进展标准进行控制,检查agent是否为每个目标达到了足够的分数阈值(图1)。在前者中,使用复杂性逐渐增加的顺序任务来训练agent。在后者中,agent在满足生成目标的有利化学空间区域取样化合物。在生成阶段维护agent策略更新,以确保来自不同最小值的agent样本。
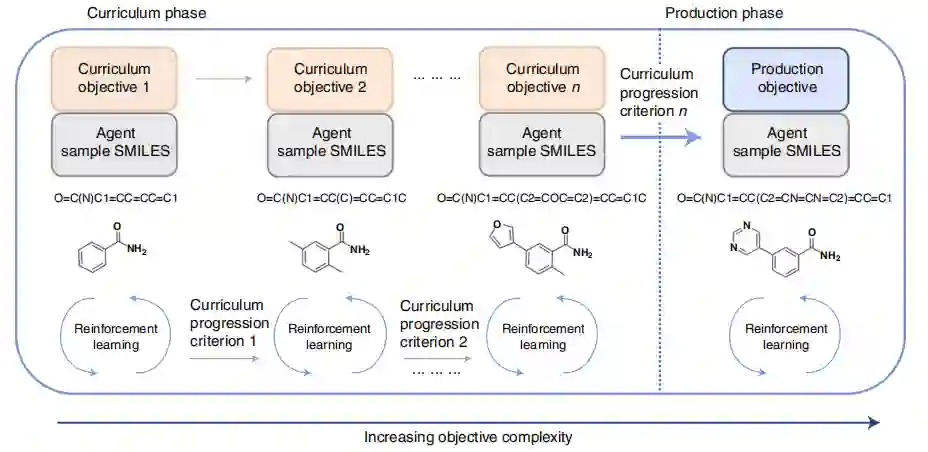
图1 CL概述
目标scaffold构建 作者表明CL可以引导agent生成具有相对复杂scaffold的化合物,该化合物不存在于训练集中(图2)。CL可以通过将目标scaffold分解为更简单的子结构,从而加速收敛(图2)。有五个课程目标,每个目标依次分配到更复杂的子结构,课程进展标准阈值为0.8。该agent的任务是生成具有子结构的化合物,直到平均分数为0.8。当满足一个课程发展标准时,就会激活一个连续的和更复杂的课程目标。每次课程目标的更新都会伴随着平均分数的急剧下降,例如,在大约在150 epoch左右(图2),当前不可能取样的化合物也会偶然地出现具有连续的子结构。在训练过程中,agent学会了生成具有越来越复杂的子结构的化合物,直到构建出目标scaffold。
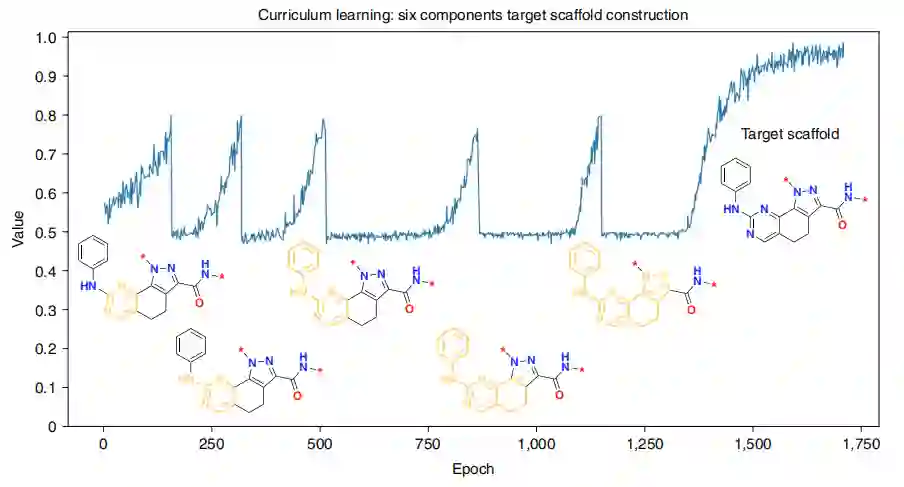
图2 CL目标scaffold构建
满足分子docking约束 作者利用单一的课程目标,可以加速agent的生成效率,并生成满足docking约束的化合物,即预测保留了实验验证的交互作用。首先,作者证明了基线RL的生成目标具有挑战性(图3b,c)。在前100个epoch,docking分数约为0,这表明基本上没有化合物满足docking约束。对于100-200的epoch,一些化合物满足docking约束,但分数仍然很低。只有从第200个epoch开始,docking分数才开始提高,并指示agent开始进入生成状态的点。很明显,基线RL是次优的,因为该agent花费了大量的时间来生成不满足生成目标的化合物。
为了解决模型受限于基线RL问题,作者设计了课程并引入了两个课程目标来指导分子生成:Tanimoto(2D)和ROCS(3D)。前者的基本原理是,通过教agent首先生成与参考配体具有二维相似性的化合物,随后生成的化合物将有更大的可能性满足docking约束。ROCS的基本原理是相同的,除了使用三维相似性来匹配参考配体的形状和静电场。使用Tanimoto和ROCS进行三次基线RL实验与CL进行比较。这些基线实验并没有提高agent的生成率,并且可以观察到与(图3b、c)中所示的基线相似的训练进度对于Tanimoto(2D)和ROCS(3D),该agent能够立即生成满足docking约束的化合物(图3b)。更具体地说,尽管在Tanimoto(2D)实验中,docking开始于一个相对较低的值(但高于基线RL),但该agent在前50个epoch迅速改善。在ROCS(3D)场景中,在300个epoch时CL超过基线RL方法获得的最高分数。结果是直观的,因为强制agent首先学习生成与参考配体具有更高的二维相似性的化合物,生成分子会更可能满足docking约束。当使用ROCS作为课程目标时,也进行了类似的观察(图3c)。为了可视化结果的质量,作者将选定生成的化合物的结合姿态与参考配体进行重叠(图3d)。
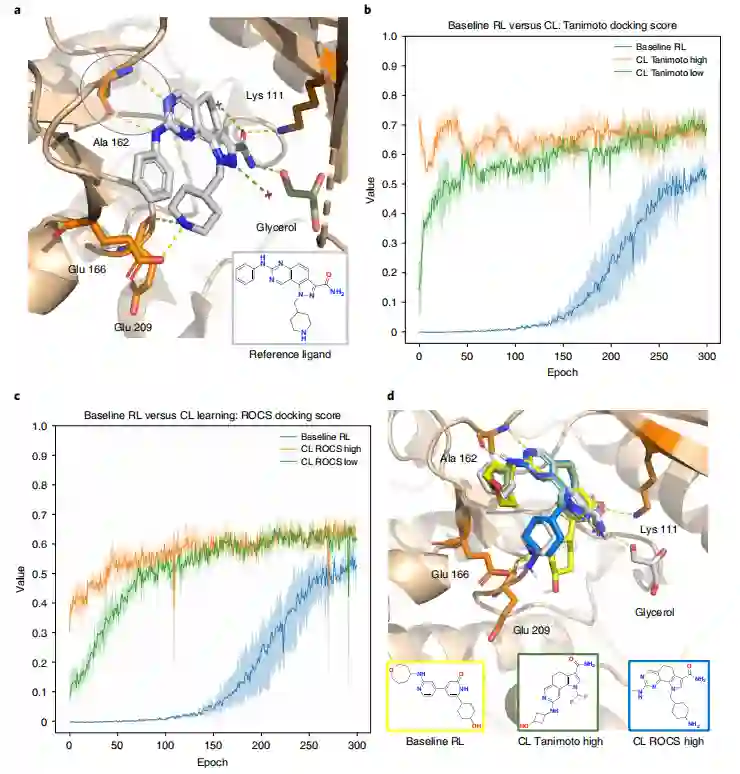
图3 设计PDK1抑制剂的基线RL与CL对比
通过课程模型增强目标的优化 为了进一步研究基线RL和CL实验的输出,作者将三次重复实验中收集到的化合物的所有docking分数汇总起来,结果分布如图4所示。首先,与基线RL相比,CL产生了明显更多的有利化合物,因为CL只存储了那些通过了基于docking和QED的最低分数的化合物。第二,CL生成的化合物比基线RL生成的拥有更高的平均docking分数。第三,对于这两个课程目标(Tanimoto和ROCS),high scenario比low scenario具有更大docking分数密度。
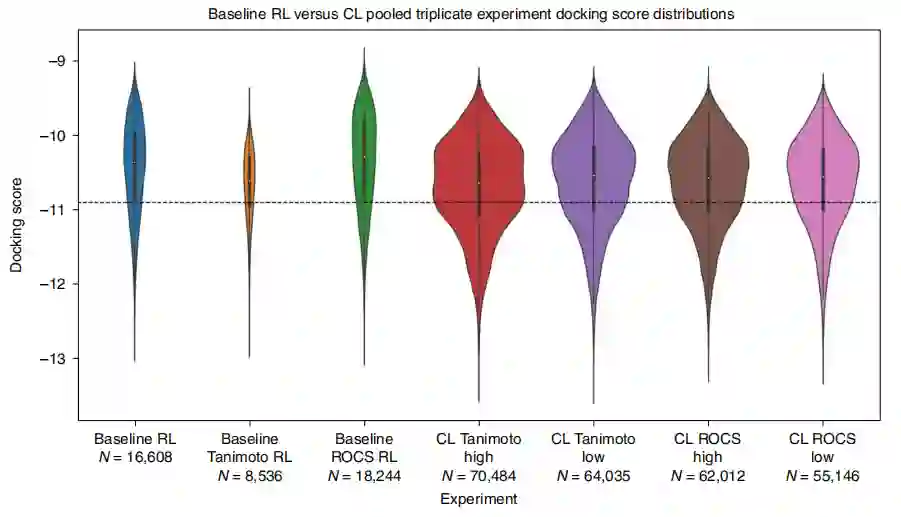
图4 基线RL与CL docking分数分布
课程目标保持探索分子scaffold 通过从三次重复实验中提取并平均独特的Bemis-Murcko scaffold的数量来研究scaffold的多样性,如图5所示。CL实验比基线RL产生了更多独特的scaffold。在课程目标中,Tanimoto比ROCS产生了更多独特的scaffold。类似地,对于Tanimoto和ROCS,high scenario比low scenario产生更多独特的scaffold。为了评估生成的scaffold的质量,如果相应的化合物比参考配体具有更有利的docking分数,作者将scaffold表示为“有利的”。从绝对计数和百分比来看,CL比基线RL产生更独特和有利的scaffold(图5)。这与图4中的对接分数分布一致,说明了CL实验的docking分数更富集。结果表明,使用课程目标增加了生成的有利scaffold的数量,并保持了由多样性过滤器强制执行的agent探索。
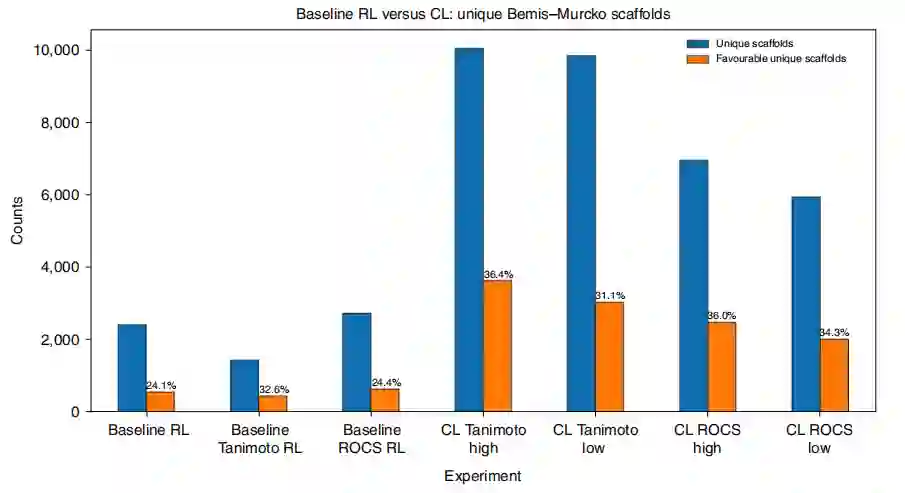
图5 基线RL与CL生成独特的Bemis-Murcko scaffold的比较
引导agent策略在生成目标优化和解决方案空间多样性之间进行权衡 为了进一步阐明课程目标的作用,以及agent在下游生成任务中保留获得知识的程度,从CL Tanimoto实验中收集到化合物,并计算每个epoch与参考配体的平均Tanimoto相似度(化合物和scaffold)(图6a)。左边的子图显示了Tanimoto相似度在low scenario和high scenario下的逐渐优化,代表了课程阶段。右边的子图显示了在生成阶段收集到的所有化合物的Tanimoto相似性。总的来说,高Tanimoto实验生成的化合物与低Tanimoto实验生成的化合物与参考配体具有更大的Tanimoto相似性,与预期一致。此外,在scaffold水平上,Tanimoto相似性的逐渐降低进一步支持了CL进行scaffold跳跃的能力(图6a)。相对于基线RL实验,CL实验中收集的化合物表现出更大的相似性,解释为从化学空间的“更近”区域取样化合物(图6b)。此外,high scenario比low scenario具有更高的交叉Tanimoto相似性密度。采用均匀流形近似和投影(UMAP)作为降维技术,以可视化CL Tanimoto实验的空间多样性。从low scenario和high scenario中采样的化合物之间有显著的相似性,没有scaffold重叠(图6c)。
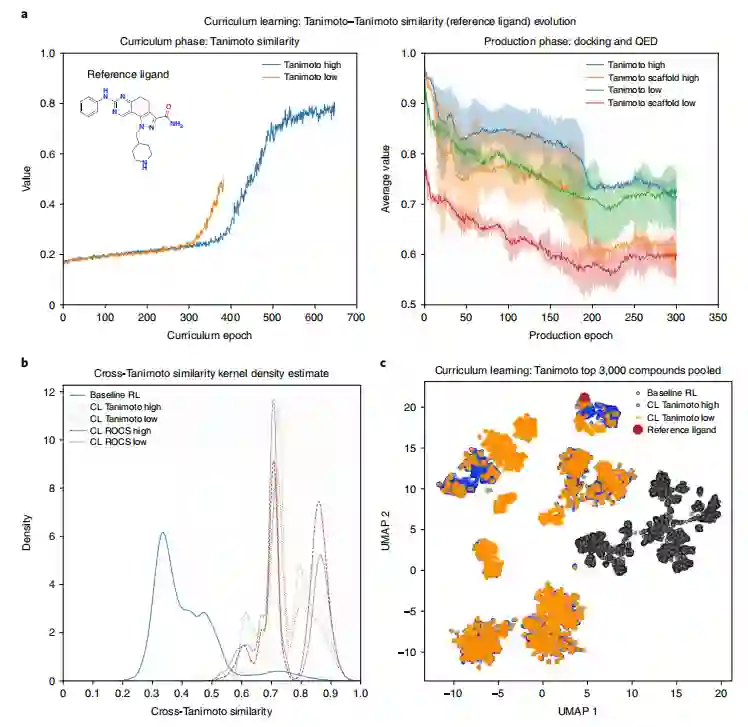
图6 agent知识保留与课程目标对解决方案空间多样性的影响
3 总结与讨论 在这项工作中,作者在分子从头设计平台REINVENT的基础上,通过调整CL来加速agent在复杂MPO目标上的收敛。相对于基线RL而言,即使是由一个课程目标组成的课程,也能成功地引导agent高效的完成任务。作者展示了CL在两个生成目标上的应用:构建一个相对复杂的scaffold和满足一个分子docking的约束。在前者中,在相同的epoch下,CL成功地从比较简单的成分中构建出复杂的scaffold,而基线RL则无法做到。在第二个应用例子中,使用Tanimoto(二维)或ROCS(三维)与参考配体的形状相似性作为课程目标,引导agent到满足docking约束的化学空间区域进行采样。相比之下,基线RL花了很多时间产生不利的化合物。CL通过提供教给agent特定知识的能力,促进了agent对生成目标的直接引导。结果表明,相对于基线RL,教agent在更大程度上优化课程目标可以提高满足复杂生成目标的能力。 参考资料 Jeff Guo , Vendy Fialková, Juan Diego Arango, Christian Margreitter. et al. Improving de novo molecular design with curriculum learning. Nature Machine Intelligence (2022). https://www.nature.com/articles/s42256-022-00494-4
数据 https://github.com/MolecularAI/ReinventCommunity/blob/master/notebooks/models/random.prior.new
