
人脸欺诈检测是一个图像/视频二分类问题,旨在正确分类真实人脸和欺诈人脸。本文研究的跨领域人脸欺诈检测考虑领域泛化场景,在三个源域(源数据集)上训练,一个目标域上测试。由于源域和目标域人脸的种族,捕获设备,场景以及欺诈手段的不同,造成该任务富有挑战性。
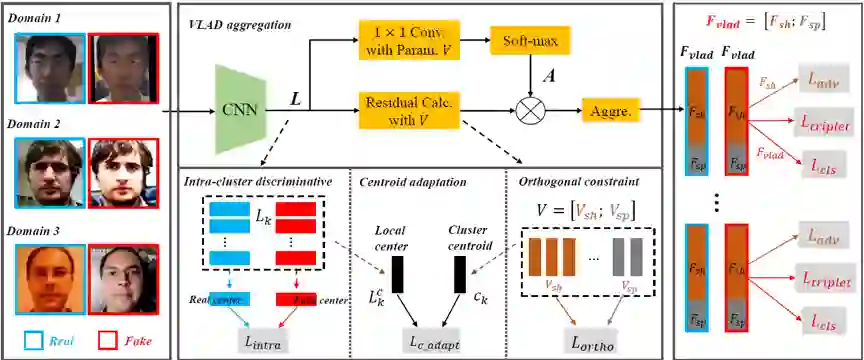
我们结合VLAD-VSA的流程图,来讲解模型流程并突出创新点:
1. 使用VLAD聚合方法代替传统的平均池化(GAP).
由于欺诈人脸的线索通常是细微、局部的,反映到feature map上则是占比较少。常用的GAP将欺诈线索特征和无线索特征求平均得到全局特征进行分类,导致欺诈特征的显著性被削弱。我们使用VLAD聚合方法,使用词表来量化局部特征,将欺诈特征和无线索局部特征分配到不同的视觉单词,再分别聚合,对应到VLAD特征的不同纬度,以保留局部特征的局部辨别能力。如图1所示,带有领域和真假标签的人脸被送入CNN网络中得到局部特征,在VLAD聚合模块中得到全局VLAD特征,然后被分类损失和三元组损失(Lcls, Ltriplet)优化。
2. 词表自适应(Vocabulary Adaptation),优化VLAD中词表的训练。
传统VLAD的词表是通过对局部特征进行聚类得到。K-Means的Expectation step将局部特征分配到视觉簇,maximization step平均簇内的特征求得视觉单词。而在VLAD层的训练过程中,词表作为卷积层的参数进行优化,只有E-step分配局部特征,却没有M-step重新求得词表。因此我们在训练中模拟M-step,约束词表中的视觉单词接近batch内所分配的局部特征的中心(Lc_adapt)。
3. 词表分离(Vocabulary Separation)。
由于领域之间的巨大差异,现有的一些领域泛化工作提出使用领域共享和领域特有的编码器或分类器。受此类方法启发,我们将词表划分为领域共享和领域特有单词,分别生成领域共享和特有特征。在训练中我们只对齐不同领域的领域共享特征的分布(Ladv),而不要求对齐领域特有特征。此外我们还对两种单词施加了正交约束(Lortho),使其可以学习到不同的信息表示。作为一个小的trick,我们还提出簇内区别损失(Lintra),拉大分配到簇内的真实图像的feature和欺诈图像的feature的距离。
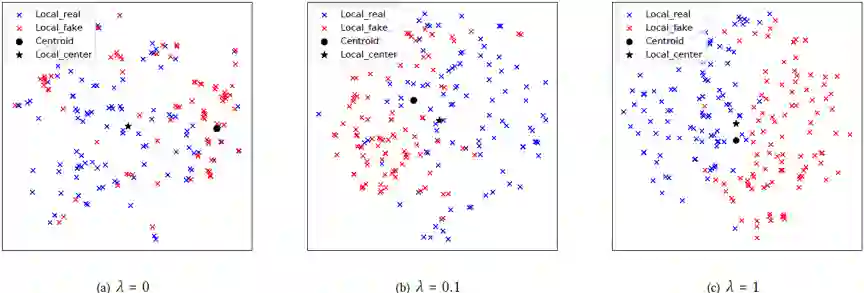
4. 实验结果
论文所提出的基于VLAD聚合方法的词表自适应,词表分离都可以有效提高欺诈检测效率,实验指标建议读者参阅论文。这里给出局部特征的T-SNE可视化结果如图2所示。可以看到不适用词表自适应的VLAD层中视觉单词远离簇中心,会导致特征不能被良好表示。随着损失权重增大,视觉单词接近簇中心,且簇内的真实特征和欺诈特征有较好的区分度。
作者:王炯1、赵洲1、金韦克1、段新宇2、雷震3、怀宝兴2、吴益灵2、何晓飞1
单位:1浙江大学、 2华为云、 3中国科学院自动化研究所
邮箱:
论文:
https://dl.acm.org/doi/10.1145/3474085.3475284
代码:
