
编译 | 蒋长志 今天给大家介绍来自苏黎世联邦理工学院和耶拿弗里德里希-席勒-耶拿大学团队发表在Nature Methods上的文章,文章提出了一种基于encoder-decoder神经网络的从质谱生成小分子结构的新方法:MSNovelist,它首先使用SIRIUS和CSI:FingerID来分别从质谱中预测出分子的指纹和表达式,然后将其输入到一个基于encoder-decoder的RNN模型来生成分子的SMILES。作者使用来自Global Natural Product Social Molecular Networking网站上的3863个质谱数据集进行评估,MSNovelist重现出了61%的分子结构,这些重现的分子结构都是未在训练集中见过的;并且使用CASMI2016数据集进行了评估,MSNovelist重现了64%的分子结构。最后,本文将MSNovelist应用在苔藓植物质谱数据集上进行验证,结果表明MSNovelist非常适合在分析物类别和新化合物表现不佳的情况下注释质谱对应的分子。

1 研究背景 小分子的识别是生命科学中的一项重要任务,而质谱可用于分析化合物成分,因此通过分析小分子的质谱数据来获得小分子结构具有重要意义。目前,已经出现了含有数万个小分子注释质谱的谱库,这为基于机器学习甚至是深度学习的方法从质谱数据中识别小分子结构铺平了道路。已有的方法大都是基于质谱数据库匹配和搜索的方法,这些方法都不能识别新的化合物,如未知的天然产物、药物代谢物或环境转化产物等。原则上,识别未知化合物的结构身份的最简单且完全独立于质谱数据库的方法是首先确定分子式,然后枚举所有可能的候选者,最后根据真实数据进行评分。但是这种方法存在结构数量的组合爆炸问题,然而用于靶向从头分子生成的深度学习模型不存在这样的问题,可以查询大量新化合物的化学空间。因此,基于生成的深度学习模型在从质谱中识别新的化合物的任务中具有很大潜力。
2 主要贡献 (1)本文提出了一个基于encoder-decoder的RNN模型来从质谱数据中生成对应分子的SMILES,即MSNovelist;MSNovelist先使用SIRIUS和CSI:FingerID来分别从质谱中预测出分子的指纹和表达式,然后将其输入到一个基于encoder-decoder的RNN模型来生成分子的SMILES; (2)本文将MSNovelist应用在苔藓植物质谱数据集上进行验证,实验结果表明MSNovelist非常适合在分析物类别和新化合物表现不佳的情况下注释质谱对应的分子。
3 模型 3.1数据预处理 本文使用的数据集由HMDB(4.0),COCONUT和DSSTox三种数据库的数据组成,训练集中的分子都经过过滤,过滤掉不能被RDKIT解析的分子、SMILES超过127个字符、包含分割点的SMILES、分子量大于1000Da,以及超过7个环(如SMILES中指定)或C、H、N、O、P、S、Br、Cl、I和F以外的元素;最后,训练集中含有1232184个分子,这些分子具有1048512个不同的结构(根据InChIKey2D规则分)。
3.2 方法 MSNovelist模型输入质谱数据,根据质谱信息来生成其分子结构,从而预测质谱对应的是什么分子化合物。首先,MSNovelist使用SIRIUS和CSI:FingerID来分别从质谱中预测出分子表达式和结构指纹,其中结构指纹是一个3609维的向量,以表示该质谱具有哪些可能的分子结构特征;然后,将分子表达式和结构指纹输入到一个encoder-decoder的RNN模型中,在分子表达式的约束下,RNN模型可以根据指纹特征向量从头生成分子的SMILES表达式;最后,使用修改的Platt分数计算生成的分子和真实质谱指纹之间的得分作为损失来优化模型参数。其中RNN模型的编码器由3个隐含层组成,解码器是一个含有3层的LSTM。MSNovelist模型的框架如图1所示。
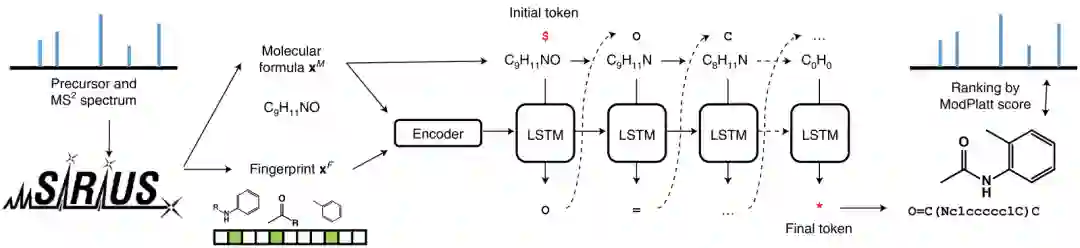
图1: MSNovelist框架图
4 实验 4.1 评价指标 本文实验部分采用的评价指标如下:
有效SMILES率: 生成的SMILES可以被RDKIT解析的样本比率;
正确匹配率: 生成的SMILES不但可以被RDKIT解析且可以和分子式匹配的样本比率;
已修改的Platt分数: 生成的SMILES与真实质谱指纹计算出的已修改的Platt分数,衡量生成的候选者与真实指纹的接近程度;
相似度: 预测出的排名最高的候选者SMILES与真实分子结构计算的Tanimoto相似性;
查准率: 预测结构中存在正确结构的比率;
Top-n: 正确结构在预测结果的top-n中的比率。
4.2 对比实验 本文为了验证MSNovelist模型的有效性,在3863个来自于GNPS数据库的质谱数据上和数据库搜索算法CSI:FingerID进行了比较,比较结果如图2(a)和(c);
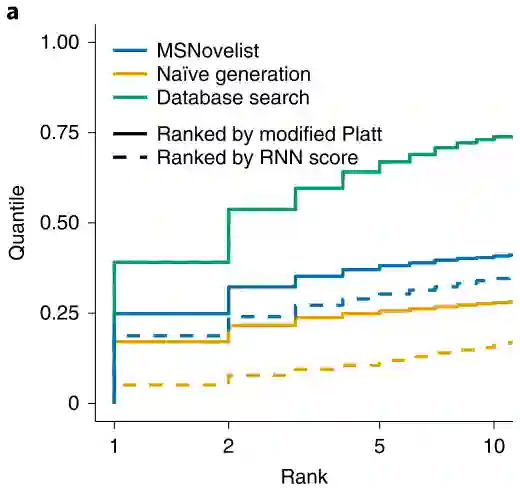
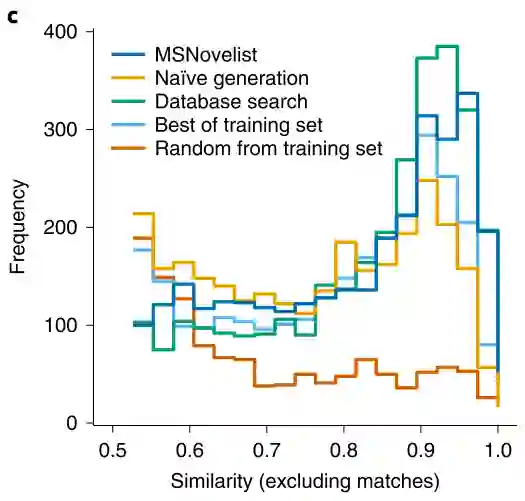
图2: MSNovelist模型与其他方法的对比结果
从对比结果可以看出,MSNovelist模型取得了比数据库搜索算法CSI:FingerID更好的预测性能。
4.3 案例分析 本文为了验证MSNovelist在预测新的分子化合物结构的的有效性,将其应用在9种苔藓植物的数据集中。已有研究表明苔藓植物会产生多种次生代谢物,但是尚未得到广泛的研究,这为发现天然产物提供了可能的机会。本文从MTBLS709数据库中提取了576个串联质谱,并使用SIRIUS工具来推断其分子式,然后使用MSNovelist模型来预测其分子结构,并和CSI:FingerID数据库搜索算法进行比较;MSNovelist模型在169个样本(75%的样本)中预测的结构得分都高于CSI:FingerID数据库搜索算法,对比结果如图3(a)。并且选取其中的一个多酚化合物(m/z为381.1020,分子式为C21H16O7)进行预测结果可视化分析,可视化结果如图4;从可视化结果可以看出,和CSI:FingerID相比,MSNovelist可以解释峰153和179,这说明MSNovelist可以更加有效的预测新的分子化合物。
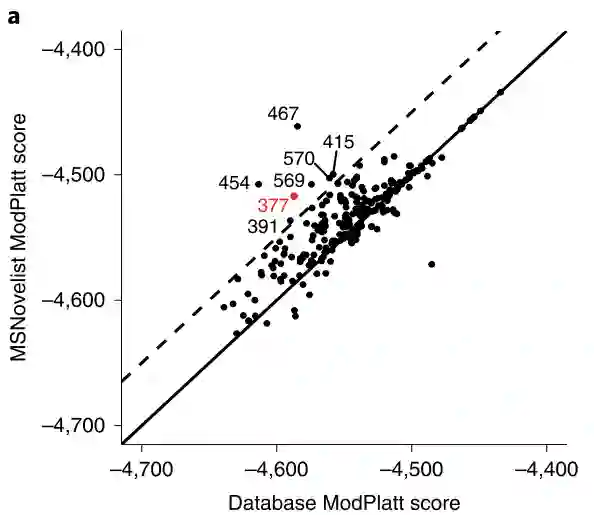
图3: 在苔藓植物数据集上的对比结果
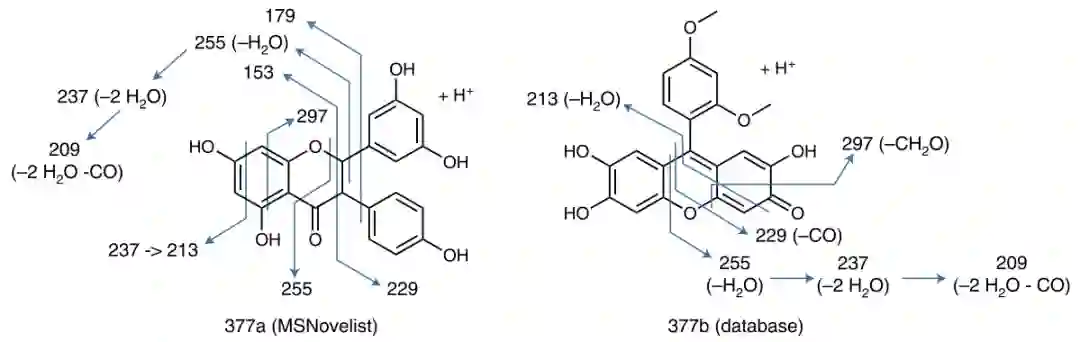
图4: 多酚化合物(m/z为381.1020,分子式为C21H16O7)预测结果可视化 5 总结和讨论 MSNovelist表明从质谱中从头生成分子结构而不依赖于结构数据库是可能的,虽然深度学习模型已经被用于从质谱数据中生成候选分子结构,但是MSNovelist能够整合编码的结构信息到指纹中,并且MSNovelist为超过一半的MS2质谱提出了合理的分子结构。由于MSNovelist依赖于现有的方法来确定分子式,即SIRIUS工具来预测出质谱的分子式,而对于m/z<300的小分子化合物,SIRIUS工具的分子式测定错误率小于10%,但对于m/z高达800的分子化合物,其测定错误率会增加到大于50%,从而会影响MSNovelist模型的预测效果。 参考资料
Stravs, M.A., Dührkop, K., Böcker, S. et al. MSNovelist: de novo structure generation from mass spectra. Nat Methods (2022). https://doi.org/10.1038/s41592-022-01486-3

