
今天给大家介绍由河南农业大学陈震教授、中国农业科学院棉花所杨作仁研究员、美国弗吉尼亚联邦大学Lukasz Kurgan教授和澳大利亚蒙纳士大学宋江宁教授等团队合作于2022年7月份发表在生物学顶级期刊Nucleic Acids Research上的一个开源的生物分子序列和结构等特征提取工具,iFeatureOmega。该工具可对多种生物分子类型数据进行特征提取,分析并进行可视化展示。这些数据包括序列数据(DNA,RNA和蛋白质序列)、蛋白质结构数据和小分子结构数据。河南农业大学陈震教授、荷兰莱顿大学刘许晗博士、中国农业科学院棉花所赵佩副研究员和蒙纳士大学李晨博士为并列第一作者。该工具在目前所有主流系统包括Windows, MacOS和Linux系统下进行了软件测试运行。iFeatureOmega包含了服务器(Webserver)版本, 图形用户界面(GUI)版本,以及命令行(CLI)版本,来满足不同计算背景下的用户使用需求。文章通过使用iFeatureOmega对蛋白质锌离子结合位点的结构微环境特征作为运行实例充分展示和论证了该工具的强大功能。

介绍
在过去的几十年里,高通量测序技术的显著进步和广泛应用,产生了前所未有的海量分子数据。如何有效、快速地对这些数据进行注释、分析、挖掘和可视化已成为一项重要的研究课题。随着机器学习方法在解决生物学问题中的广泛应用,越来越多的团队选择使用基于机器学习的法方法对生物序列进行精准预测和分析。在这个过程中,对分子数据的特征提取、计算、分析以及可视化是非常重要的一环。根据研究任务的不同,特征提取方法多种多样。因此,为了方便研究人员对分子数据进行特征提取,我们开发了一个综合的能够对多种分子类型包括序列数据(DNA、RNA和蛋白质序列)、蛋白质结构数据和小分子结构数据等多种数据进行特征提取、分析和可视化的工具,并命名为iFeatureOmega。iFeatureOmega包含Webserver、GUI和CLI三个版本,以满足不同用户的分析需求。与其他相关工具比较iFeatureOmega具有以下几方面的有点:
现有大部分工具通常只能针对一种或少数几种分子数据类型进行特征提取。 与同类工具相比较,iFeatureOmega支持最多数量的分子数据类型和特征描述符提取方法; 1. 除了我们之前所开发的iFeature之外,大部分现有工具都不支持对特征提取结果的分析。 为了解决这个问题,iFeatureOmega支持15种聚类、降维和特征标准化算法; 1. iFeatureOmega提供了丰富的、可交互的数据和结果的图形展示方式; 1. iFeatureOmega同时提供三个版本,以满足不同用户的分析需求。
iFeatureOmega架构设计
iFeatureOmega集成了170多种特征提取方法,可以对DNA、RNA和Protein等序列数据,Protein structure数据和小分子(Ligand)结构数据进行特征提取,分析和可视化。特征分析算法包含10种聚类算法、3种降维算法和2种数据标准化方法。图形化展示方面支持9种可交互的数据展示方法,包括柱状图、概率密度图、热图、箱线图、散点图、圈图、蛋白质结构和小分析结构展示图。
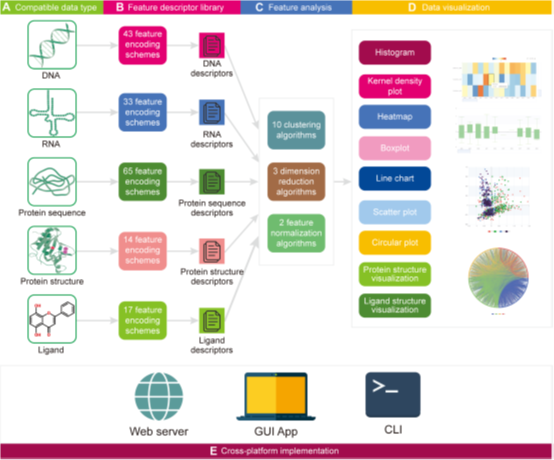
与其他工具的比较
下表展示了iFeatureOmega与现有工具在支持的分子数据类型、特征分析、数据可视化展示和工具的易用性等方面进行的比较:

GUI版本的图形化展示
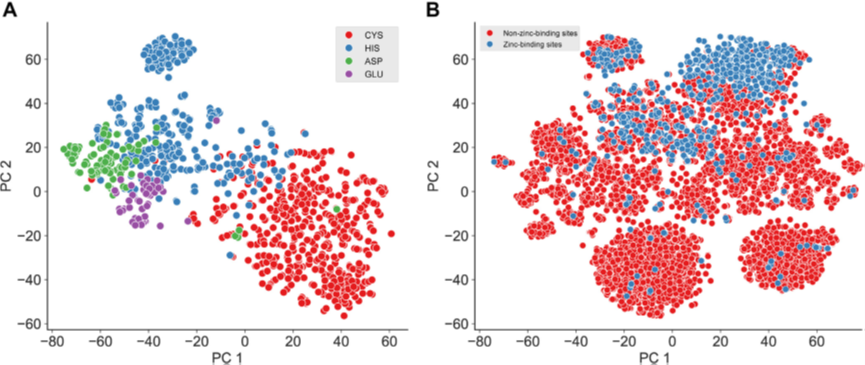
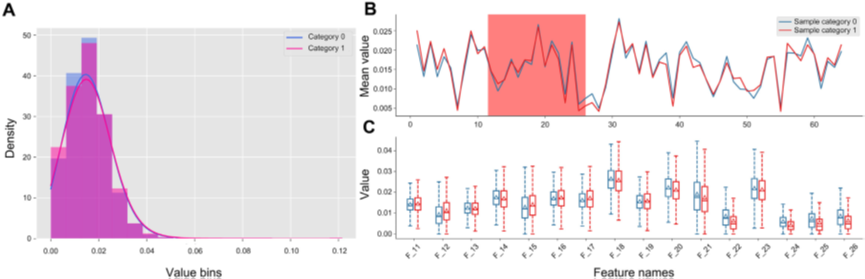
图1. iFeatureOmega-GUI的图形展示示例
Webserver的图形化展示
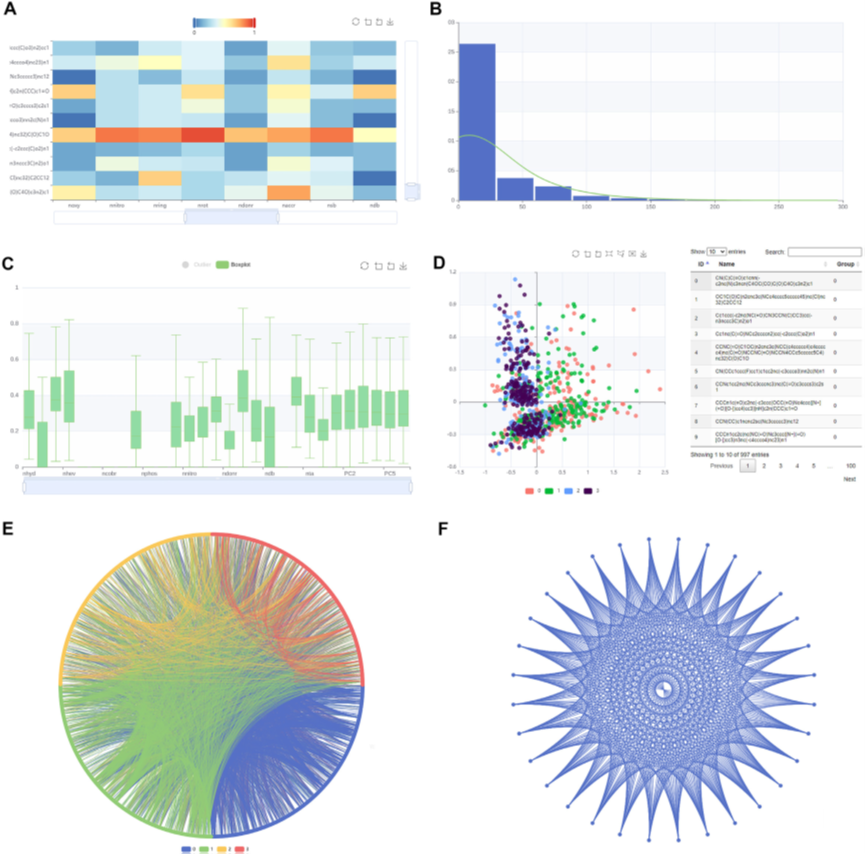
图2. iFeatureOmega-Web的图形展示示例 iFeatureOmega使用与安装
iFeatureOmega的服务器版本可通过https://ifeatureomega.erc.monash.edu/ 进行在线访问。本地版本的安装也十分方便。用户既可以通过pip命令方便的安装,其源码也可以通过https://github.com/Superzchen/iFeatureOmega-GUI (GUI版本),https://github.com/Superzchen/iFeatureOmega-CLI(CLI版本)链接进行下载。 参考资料 Zhen Chen et al., iFeatureOmega: an integrative platform for engineering, visualization and analysis of features from molecular sequences, structural and ligand data sets, Nucleic Acids Research, 2022,50(W1): W434–W447.
https://doi.org/10.1093/nar/gkac351
Zhen Chen et al., iLearnPlus: a comprehensive and automated machine-learning platform for nucleic acid and protein sequence analysis, prediction and visualization. Nucleic Acids Research , 2021,49(10): e60. https://doi.org/10.1093/nar/gkab122
Zhen Chen et al., iLearn: an integrated platform and meta-learner for feature engineering, machine-learning analysis and modeling of DNA, RNA and protein sequence data. Briefings in Bioinformatics, 2020, 21(3): 1047–1057. https://doi.org/10.1093/bib/bbz041
Zhen Chen et al., iFeature: a Python package and web server for features extraction and selection from protein and peptide sequences. Bioinformatics, 2018, 34(14): 2499–2502. https://doi.org/10.1093/bioinformatics/bty140
