

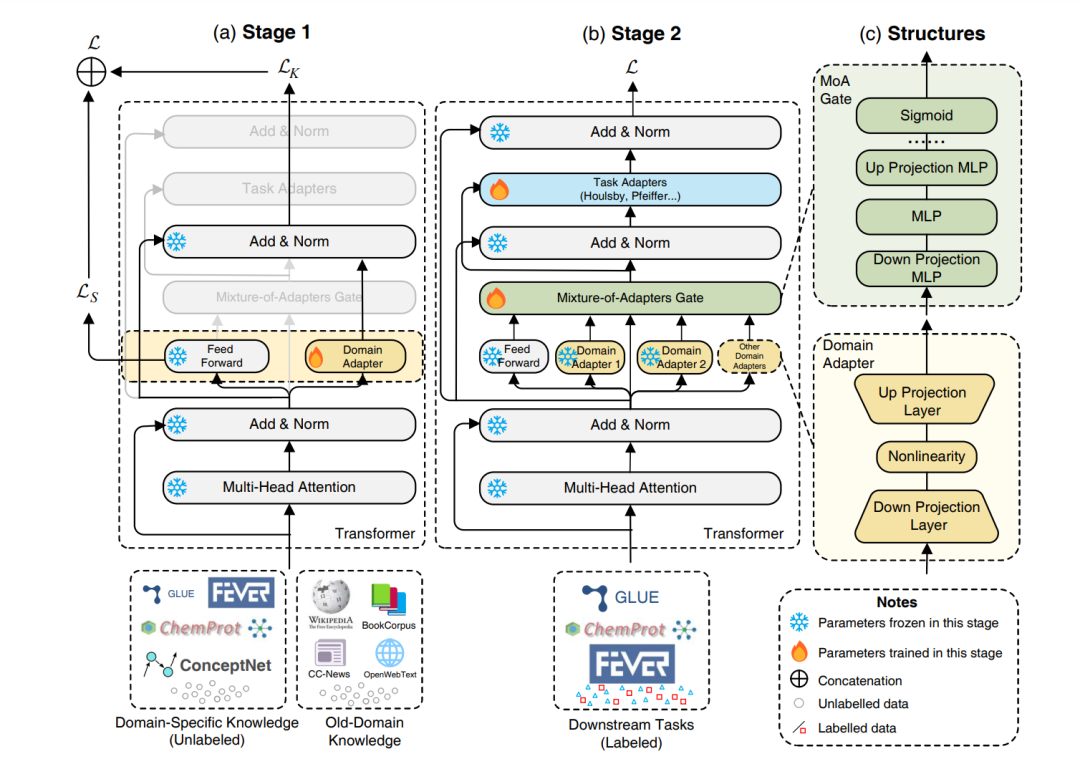
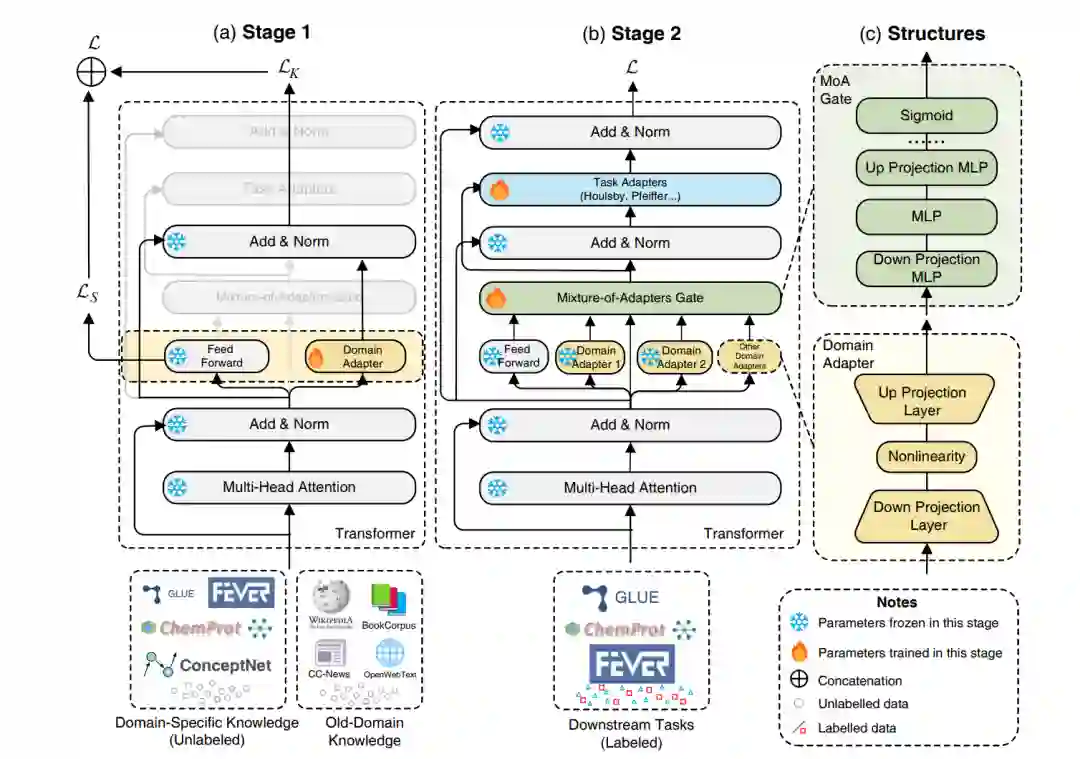
预训练语言模型(PLMs)在理解通用领域的文本方面表现出了卓越的能力,然而在特定领域的理解方面却面临挑战。尽管在大型特定领域语料库上进行连续预训练是有效的,但在该领域上调整所有参数的成本非常高。在本文中,我们研究了我们是否能够通过仅调整少数参数来有效且高效地适应 PLMs。具体而言,我们将 Transformer 架构的前馈网络(FFNs)解耦为两部分:原始预训练的 FFNs 用于保留旧领域知识,而我们创新的领域特定适配器则并行注入领域特定知识。然后,我们采用了一种混合适配器门来动态地融合来自不同领域适配器的知识。我们提出的领域适配器混合(MixDA)采用了两阶段适配器调优策略,利用无标签数据和有标签数据来帮助领域适应:i)在无标签数据上的领域特定适配器;接着是 ii)在有标签数据上的任务特定适配器。MixDA 可以无缝地插入预训练-微调范例,我们的实验表明,MixDA 在领域内任务(GLUE),领域外任务(ChemProt,RCT,IMDB,Amazon)以及知识密集型任务(KILT)上都实现了卓越的性能。进一步的分析证明了我们方法的可靠性,可扩展性和效率。
https://www.zhuanzhi.ai/paper/20a33c2a350833619d3fb41eef0ce624
成为VIP会员查看完整内容

相关内容
Arxiv
0+阅读 · 2023年7月31日


相关VIP内容
相关资讯