

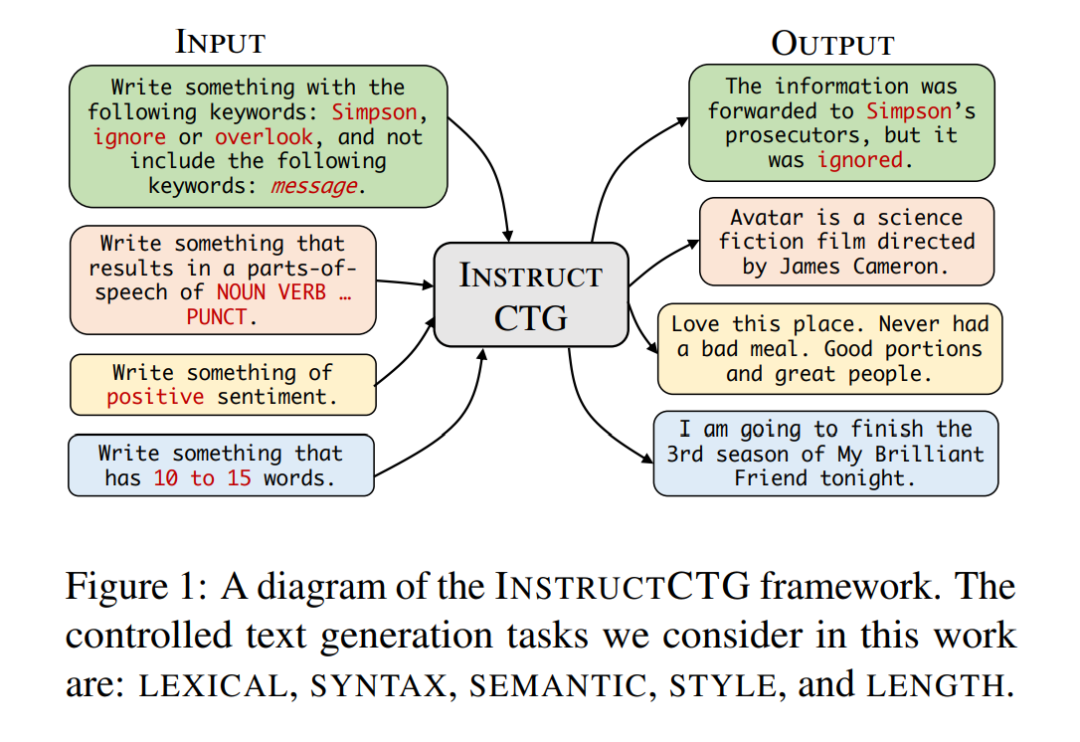
大型语言模型可以生成流畅的文本,并可以按照自然语言指令解决各种任务,而无需特定任务的训练。然而,要控制它们的生成以满足不同应用所需的各种约束条件是非常困难的。在这项工作中,我们提出了INSTRUCTCTG,这是一个受控文本生成框架,它通过依据约束条件的自然语言描述和演示来结合不同的约束条件。特别地,我们首先通过一组现成的自然语言处理工具和简单的启发式方法来提取自然文本中的潜在约束条件。然后,我们将这些约束条件转化为自然语言指令,以形成弱监督的训练数据。通过在输入之前添加约束条件的自然语言描述和一些演示,我们微调了一个预训练的语言模型,以包括各种类型的约束条件。与现有的基于搜索或基于评分的方法相比,INSTRUCTCTG 对不同类型的约束条件更加灵活,并且对生成质量和速度的影响要小得多,因为它不修改解码过程。此外,INSTRUCTCTG 还允许模型通过使用指令调整的语言模型的少量样本任务泛化和上下文学习能力来适应新的约束条件而无需重新训练。代码将在 https://github. com/MichaelZhouwang/InstructCTG 上提供。
成为VIP会员查看完整内容

相关内容


相关VIP内容
相关资讯