

微型机器学习(TinyML)是机器学习的新前沿。通过将深度学习模型压缩到数十亿个物联网设备和微控制器(MCU)中,我们扩大了AI应用的范围,并实现了无所不在的智能。然而,由于硬件的限制,TinyML面临挑战:微小的内存资源使得难以容纳为云和移动平台设计的深度学习模型。对于裸机设备,编译器和推理引擎的支持也有限。因此,我们需要共同设计算法和系统堆栈以启用TinyML。在这篇综述中,我们将首先讨论TinyML的定义、挑战和应用。然后,我们调查TinyML和MCU上深度学习的最近进展。接下来,我们将介绍MCUNet,展示我们如何通过系统-算法共同设计在物联网设备上实现ImageNet规模的AI应用。我们将进一步将解决方案从推理扩展到训练,并介绍微型现场训练技术。最后,我们提出了这一领域的未来发展方向。今天的“大”模型可能是明天的“微小”模型。TinyML的范围应该随着时间的推移而发展和适应。
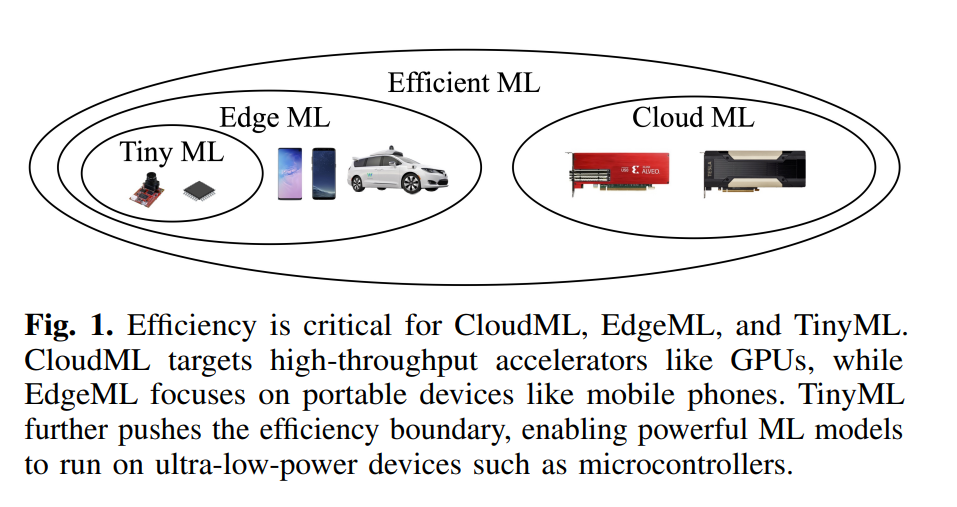
机器学习(ML)对各个领域,包括视觉、语言和音频,产生了重大影响。然而,最先进的模型通常以高计算和内存消耗为代价,使得它们的部署成本高昂。为了解决这个问题,研究人员一直在研究高效的算法、系统和硬件,以降低各种部署场景中机器学习模型的成本。高效ML有两个主要子领域:EdgeML和CloudML(图1)。CloudML专注于改善云服务器的延迟和吞吐量,而EdgeML则专注于提高边缘设备的能效、延迟和隐私。这两个领域在诸如混合推理[1, 2]、空中(OTA)更新以及边缘与云之间的联邦学习[3]等领域也有交集。近年来,EdgeML的应用范围已经扩展到超低功耗设备,如物联网设备和微控制器,被称为TinyML。
TinyML具有几个关键优势。它使得机器学习仅使用几百KB的内存成为可能,大大降低了成本。随着数十亿物联网设备在我们的日常生活中产生越来越多的数据,对低功耗、始终在线、设备上的AI的需求日益增长。通过在传感器附近执行设备上的推理,TinyML能够在降低与无线通信相关的能源成本的同时,提高响应能力和隐私性。对于实时决策至关重要的应用,如自动驾驶车辆,数据的设备上处理可带来好处。除了推理外,我们还将TinyML的前沿推向了在物联网设备上实现设备上训练,通过持续和终身学习革命化了EdgeAI。边缘设备可以在自身上微调模型,而不是将数据传输到云服务器,这保护了隐私。设备上学习具有许多好处和各种应用。例如,家用摄像头可以持续识别新面孔,电子邮件客户端可以通过更新定制化的语言模型逐渐改善其预测。它还使得那些没有物理连接到互联网的物联网应用能够适应环境,如精确农业和海洋感测。
在这篇综述中,我们首先将讨论TinyML的定义和挑战,分析为什么我们不能直接将移动ML或云ML模型缩放到tinyML。然后我们深入探讨TinyML中系统-算法共同设计的重要性。接下来,我们将调研最近的文献和该领域的进展,以表格II和III呈现全面的综述和比较。接下来,我们将介绍我们的TinyML项目MCUNet,它结合了高效的系统和算法设计,以实现从推理到训练的TinyML。最后,我们将讨论该领域未来研究方向的几个新兴话题。
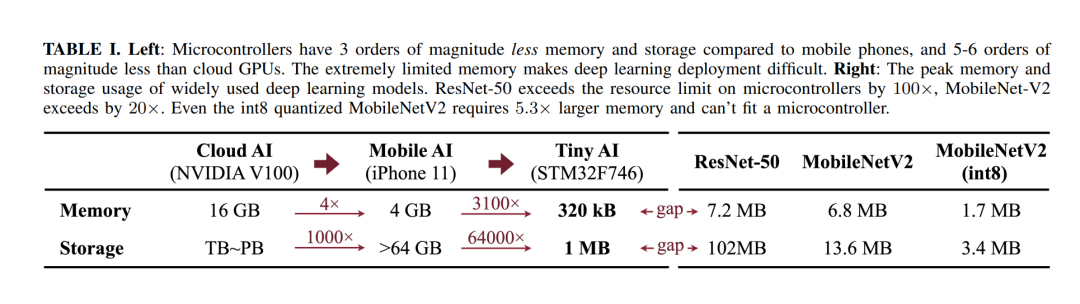
A. TinyML的挑战 深度学习模型的成功往往以高计算为代价,这对于因严格的资源限制而无法在TinyML应用中使用的设备(如微控制器)来说是不可行的。在MCU上部署和训练AI模型极其困难:没有DRAM,没有操作系统(OS),并且严格的内存限制(SRAM小于256kB,FLASH为只读)。这些设备上可用的资源比移动平台上可用的资源小几个数量级(见表I)。该领域的先前工作要么(I)专注于减少模型参数而没有解决激活的真正瓶颈,要么(II)仅优化操作符内核而没有考虑改进网络架构设计。这两种方法都没有从共同设计的角度考虑问题,这导致了TinyML应用的解决方案不够理想。我们观察到TinyML的几个独特挑战,并推测它们如何可能被克服: 1)为移动平台设计的模型不适合TinyML 2)直接适应模型用于推理对于微小训练不起作用。 3)TinyML需要共同设计。

B. TinyML的应用 通过将昂贵的深度学习模型普及到物联网设备,TinyML有许多实际应用。一些示例应用包括:
个性化医疗:TinyML可以让可穿戴设备,如智能手表,持续跟踪用户的活动和氧饱和度状态,以提供健康建议[11, 12, 13, 14]。身体姿态估计对老年人医疗也是至关重要的应用[15]。
可穿戴应用:TinyML可以协助人们使用可穿戴或物联网设备进行语音应用,例如关键词识别、自动语音识别和说话人验证[16, 17, 18]。
智能家居:TinyML可以在物联网设备上启用对象检测、图像识别和面部检测,以构建智能环境,如智能家居和医院[19, 20, 21, 22, 23]。
人机界面:TinyML可以启用人机界面应用,如手势识别[24, 25, 26, 27]。TinyML还能够预测和识别手语[28]。
智能车辆和交通:TinyML可以执行对象检测、车道检测和决策制定,而无需云连接,为自动驾驶场景实现高准确度和低延迟结果[29, 30, 31]。
异常检测:TinyML可以使机器人和传感器具备执行异常检测的能力,以减少人力[32, 33, 34]。
生态和农业:TinyML还可以帮助生态、农业、环境和表型学应用,以保护濒危物种或预测天气活动[35, 36, 37, 38, 39, 40]。 总的来说,TinyML的潜在应用是多样化和众多的,并且随着该领域的不断进步,这些应用将会扩展。
TinyML进展
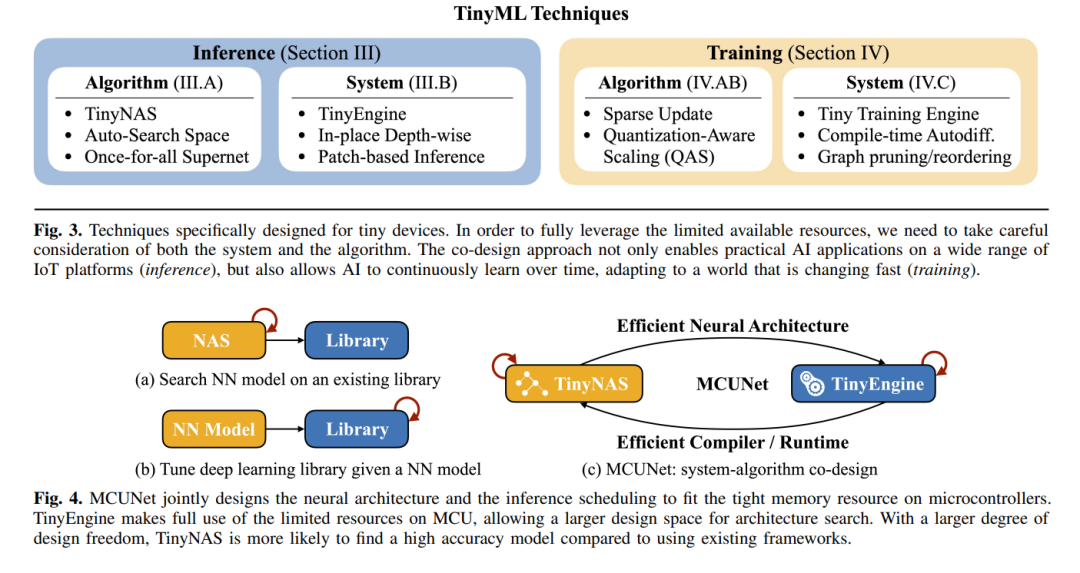
A. TinyML推理的最新进展
近年来,TinyML及其在微控制器(MCU)上的深度学习在工业界和学术界迅速增长。在MCU上部署深度学习模型进行推理的主要挑战是这些设备上可用的内存和计算能力有限。例如,一款流行的ARM Cortex-M7 MCU,STM32F746,仅有320KB的SRAM和1MB的闪存。在深度学习场景中,SRAM限制了激活(读写)的大小,而闪存限制了模型(只读)的大小。此外,STM32F746的处理器时钟速度为216 MHz,比笔记本电脑低10到20倍。为了在MCU上启用深度学习推理,研究人员提出了各种设计和解决方案来解决这些问题。表II总结了针对MCU的最新相关研究,包括算法解决方案和系统解决方案。在表III中,我们在同一MCU(STM32H743)和相同数据集(VWW和Imagenet)上测量了四项代表性相关研究(即CMSIS-NN [41]、X-Cube-AI [42]、TinyEngine [8]和TFLite Micro [47])的三个不同指标(即延迟、峰值内存和闪存使用),以提供更准确和透明的比较。
a) 算法解决方案
神经网络效率对深度学习系统的整体性能至关重要。通过去除冗余和通过剪枝[57, 58, 59, 60, 61, 62]和量化[63, 64, 65, 66, 67, 68, 69, 70]来降低复杂性是提高网络效率的两种流行方法。张量分解[71, 72, 73]也是一种有效的压缩技术。为了提高网络效率,知识蒸馏也是一种从一个教师模型向另一个学生模型转移所学知识的方法[74, 75, 76, 77, 78, 79, 80, 81]。另一种方法是直接设计微小且高效的网络结构[5, 4, 6, 7]。最近,神经架构搜索(NAS)在设计高效网络方面占据了主导地位[82, 83, 84, 85, 86, 87]。
为了使深度学习在MCU上可行,研究人员提出了各种算法解决方案。Rusci等人提出了一种基于规则的量化策略,该策略通过最小化激活和权重的位精度来减少内存使用[45]。根据各种设备的内存限制,该方法可以将激活和权重量化为8位、4位或2位的混合精度。另一方面,尽管神经架构搜索(NAS)在找到高效网络架构方面取得了成功,但其有效性高度依赖于搜索空间的质量[88]。对于内存有限的MCU,标准模型设计和适当的搜索空间尤其缺乏。为了解决这个问题,作为MCUNet一部分提出的TinyNAS采用了一种两步NAS策略,根据可用资源优化搜索空间[8]。然后,TinyNAS在优化的搜索空间内专门化网络架构,允许它以低搜索成本自动处理各种约束(例如,设备、延迟、能量、内存)。MicroNets观察到,NAS搜索空间中的网络在MCU上的推理延迟与模型中的FLOPs数量成线性变化[48]。因此,它提出了差异化NAS,将FLOPs作为延迟的代理,以实现低内存消耗和高速度。MCUNetV2识别出,在大多数卷积神经网络设计中,不平衡的内存分布是主要的内存瓶颈,其中前几个块的内存使用量比网络的其余部分大一个数量级[9]。因此,该研究提出了感受野重新分布,将感受野和FLOPs转移到后期,减少光环的计算开销。为了最小化手动重新分布感受野的难度,该研究还自动化了神经架构搜索过程,以同时优化神经架构和推理调度。UDC探索了更广泛的设计搜索空间,以生成可压缩的高精度神经网络,这些网络适用于神经处理单元(NPU),可以通过利用更广泛的权重量化和稀疏度范围来解决内存问题[51]。
b) 系统解决方案 近年来,诸如PyTorch [89]、TensorFlow [90]、MXNet [91]和JAX [92]等流行的训练框架对深度学习的成功做出了贡献。然而,这些框架通常依赖于宿主语言(例如,Python)和各种运行时系统,这增加了显著的开销,并使它们与微小的边缘设备不兼容。诸如TVM [93]、TF-Lite [94]、MNN [95]、NCNN [96]、TensorRT [97]和OpenVino [98]等新兴框架为边缘设备(如移动电话)提供了轻量级运行时系统,但它们对MCU来说还不够小。这些框架无法容纳内存有限的物联网设备和MCU。
CMSIS-NN实现了优化的内核,以提高ARM Cortex-M处理器上深度学习模型的推理速度、最小化内存占用和提高能效[41]。由STMicroelectronics设计的X-Cube-AI支持将预训练的深度学习模型自动转换为在STM MCU上运行,并提供了优化的内核库[42]。TVM[93]和AutoTVM[99]也支持微控制器(称为µTVM/microTVM [43])。编译技术也可以用来减少内存要求。例如,Stoutchinin等人提出通过优化卷积循环嵌套来提高MCU上深度学习的性能[100]。Liberis等人和Ahn等人提出重新排序操作执行以最小化峰值内存[44, 101],而Miao等人通过临时从SRAM中交换数据来寻求更好的内存利用率[102]。为了减少峰值内存,其他研究人员进一步提出在多个层次上计算部分空间区域[103, 104, 105]。此外,CMix-NN支持MCU上量化激活和权重的混合精度内核库,以减少内存占用[46]。TinyEngine作为MCUNet的一部分,被提出为一种内存高效的推理引擎,用于扩展搜索空间并适应更大的模型[8]。TinyEngine将大部分操作从运行时转移到编译时间之前,仅生成将由TinyNAS模型执行的代码。此外,TinyEngine适应了整个网络拓扑的内存调度,而不是逐层优化。TensorFlow-Lite Micro(TF-Lite Micro)是最早支持裸机微控制器的深度学习框架之一,以在内存紧张的MCU上启用深度学习推理[47]。然而,上述框架仅支持逐层推理,这限制了只能使用少量内存执行的模型容量,并使得高分辨率输入变得不可能。因此,MCUNetV2提出了一种通用的逐块推理调度,它在特征图的小空间区域上操作,并大大减少了峰值内存使用,从而使得在MCU上进行高分辨率输入的推理成为可能[9]。TinyOps通过直接存储器访问(DMA)外设将快速内部存储器与额外的慢速外部存储器结合起来,以增大内存大小并加速推理[49]。TinyMaix与CMSIS-NN类似,是一个优化的推理内核库,但它避免了新但罕见的特性,并寻求保持代码库的可读性和简单性[50]。
B. TinyML训练的最新进展
在小型设备上进行设备上训练越来越受欢迎,因为它使得机器学习模型能够直接在小型和低功耗设备上进行训练和精炼。设备上训练提供了几个好处,包括提供个性化服务和保护用户隐私,因为用户数据永远不会传输到云端。然而,与设备上推理相比,设备上训练呈现了额外的挑战,因为需要存储中间激活和梯度,从而需要更大的内存占用和增加的计算操作。
研究人员一直在探索减少训练深度学习模型内存占用的方法。一种方法是手动设计轻量级网络结构或利用NAS[85, 106, 107]。另一种常见方法是通过计算来换取内存效率,如在推理期间释放激活并在反向传播期间重新计算丢弃的激活[108, 109]。然而,这种方法以增加计算时间为代价,这对于计算资源有限的小型设备来说是不可承受的。分层训练是另一种方法,与端到端训练相比,它也可以减少内存占用。然而,它在实现高水平准确性方面不那么有效[110]。另一种方法通过激活剪枝构建动态和稀疏的计算图来减少训练的内存占用[111]。一些研究人员提出了不同的优化器[112]。量化也是一种常见的方法,通过减少训练激活的位宽来减少训练期间激活的大小[113, 114]。
由于数据和计算资源有限,设备上训练通常侧重于迁移学习。在迁移学习中,神经网络首先在大规模数据集(如ImageNet[115])上预训练,并用作特征提取器[116, 117, 118]。然后,只需要在较小的、特定任务的数据集上微调最后一层[119, 120, 121, 122]。这种方法通过消除在训练期间存储中间激活的需要来减少内存占用,但由于容量有限,当领域偏移较大时,准确性可能较差[52]。微调所有层可以实现更好的准确性,但需要大量内存来存储激活,这对于小型设备来说是不可承受的[117, 116]。最近,提出了几种内存友好的设备上训练框架[123, 124, 125],但这些框架针对的是较大的边缘设备(即移动设备),不能在MCU上采用。另一种方法是仅更新批量归一化层的参数[126, 127]。这减少了可训练参数的数量,但这并不转化为内存效率[52],因为批量归一化层的中间激活仍然需要存储在内存中。
已经证明,神经网络的激活是限制在小型设备上训练能力的主要因素。Tiny-Transfer-Learning (TinyTL)通过冻结网络的权重并仅微调偏置来解决这个问题,这允许在反向传播期间丢弃中间激活,从而减少峰值内存使用[52]。TinyOL仅训练最后一层的权重,允许在保持激活足够小以适应小型设备的同时进行权重训练[53]。这使得增量式的设备上数据流训练成为可能。然而,仅微调偏置或最后一层可能无法提供足够的精度。为了在有限内存的设备上训练更多层,POET(Private Optimal Energy Training)[54]引入了两种技术:重物化,它在重新计算的代价下尽早释放激活,和分页,它允许激活被转移到二级存储。POET使用整数线性程序来找到设备上训练的能量最优调度。为了进一步减少存储训练权重所需的内存,MiniLearn应用了量化和反量化技术,在整数精度下存储权重和中间输出,并在训练期间将它们反量化为浮点精度[55]。当在小型设备上部署时,深度学习模型通常被量化以减少参数和激活的内存使用。然而,即使在量化之后,参数仍然可能太大,无法适应有限的硬件资源,阻止了完整的反向传播。为了解决这些挑战,MCUNetV3提出了一种算法-系统共同设计方法[56]。算法部分包括量化感知缩放(QAS)和稀疏更新。QAS校准梯度尺度并稳定8位量化训练,而稀疏更新跳过不太重要的层和子张量的梯度计算。系统部分包括Tiny Training Engine(TTE),它已经开发出来支持QAS和稀疏更新,使得在内存有限的微控制器上实现设备上学习成为可能,例如那些具有256KB甚至更少的内存。
