深度学习(Deep learning, DL)在各个领域都表现出了蓬勃发展的势头。DL模型的开发是一个耗时且资源密集型的过程。因此,GPU专用加速器被集合构建为GPU数据中心。对于这种GPU数据中心,高效的调度设计对于降低运行成本、提高资源利用率至关重要。然而,针对大数据或高性能计算工作负载的传统方法无法支持DL工作负载,无法充分利用GPU资源。最近,针对GPU数据中心的DL工作负载,提出了大量的调度器。本文调研了训练和推理工作量的现有研究成果。我们主要介绍现有的调度器如何从调度目标和资源消耗特性促进各自的工作负载。最后,对未来的研究方向进行了展望。在我们的项目网站上可以找到更详细的综述论文总结和代码链接:https://github.com/S-Lab-SystemGroup/Awesome-DL-Scheduling-Papers。
近几十年来,深度学习(deep learning, DL)在许多领域的研究、开发和应用急剧增加,包括围棋[130]、医学分析[125]、机器人[48]等。标准的DL开发流程包括模型训练和模型推理。每个阶段都需要高级硬件资源(GPU和其他计算系统)来生产和服务生产级DL模型[62,71,106,149]。因此,it行业[62,149]和研究机构[18,19,71]普遍建立GPU数据中心,以满足日益增长的DL发展需求。GPU数据中心拥有大量的异构计算资源来承载大量的DL工作负载。迫切需要一个有效的调度器系统来协调这些资源和工作负载,以保证DL工作负载执行、硬件利用率和其他调度目标的效率。
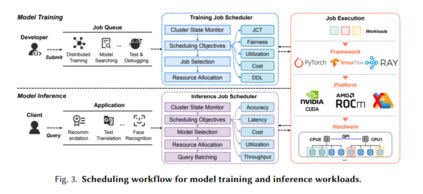
调度器负责确定整个数据中心的资源利用率和每个作业的性能,从而进一步影响操作成本和用户体验[42]。具体来说,(1)对于模型训练,调度器分配用户请求的资源,以支持长时间运行的离线训练工作负载。调度器需要为每个单独的工作负载实现高性能,为整个数据中心实现高资源利用率,并在不同用户之间实现高公平性。由于DL训练工作的特殊性和复杂性,传统的高性能计算(HPC)和大数据负载调度算法会导致资源利用率不均衡和基础设施费用过高[157],需要为GPU数据中心量身定制新的解决方案。(2)在模型推理中,DL应用通常作为在线服务来回答用户的请求。他们通常对响应延迟和推断精度有更高的期望[25,172]。未能在指定时间内完成(服务水平协议)或精度低于预期的应用程序可能很少或没有商业价值。因此,调度器在推断延迟、准确性和成本之间的平衡是至关重要的。
多年来,各种DL调度器被提出用于GPU数据中心[25,46,106,117,121,152,172]。然而,这些系统中的大多数都是针对某些特定目标而设计的。对于DL工作负载的高效调度,目前还缺乏全面的探索。我们对以下问题感兴趣:** (1)设计一个令人满意的调度器来管理DL工作负载和资源的主要挑战是什么? (2) 现有的解决方案是否有共同的策略来实现其调度目标? (3) 我们需要如何完善调度程序以适应DL技术的快速发展?这些问题对于系统研究人员和实践者理解DL工作负载调度和管理的基本原理,以及为更复杂的场景和目标设计创新的调度程序是很重要的。遗憾的是,目前还没有这样的工作来系统地总结和回答这些问题**。 据我们所知,本文首次介绍了在研究和生产中GPU数据中心调度DL训练和推理工作负载的调研。我们做出了以下贡献。首先,我们深入分析了DL工作负载的特征,并确定了在GPU数据中心管理各种DL工作负载的固有挑战。其次,对现有的DL调度工作进行了全面的回顾和总结。我们根据调度目标和资源消耗特征对这些解决方案进行分类。我们还分析了它们的机制,以解决日程安排方面的挑战。这样的总结可以揭示现有的DL调度器设计的常见和重要的考虑因素。第三,我们总结了现有设计的局限性和影响,为GPU数据中心的调度器设计提供了新的思路。我们希望这项调研可以帮助社区了解DL调度程序的发展,并促进未来的设计。
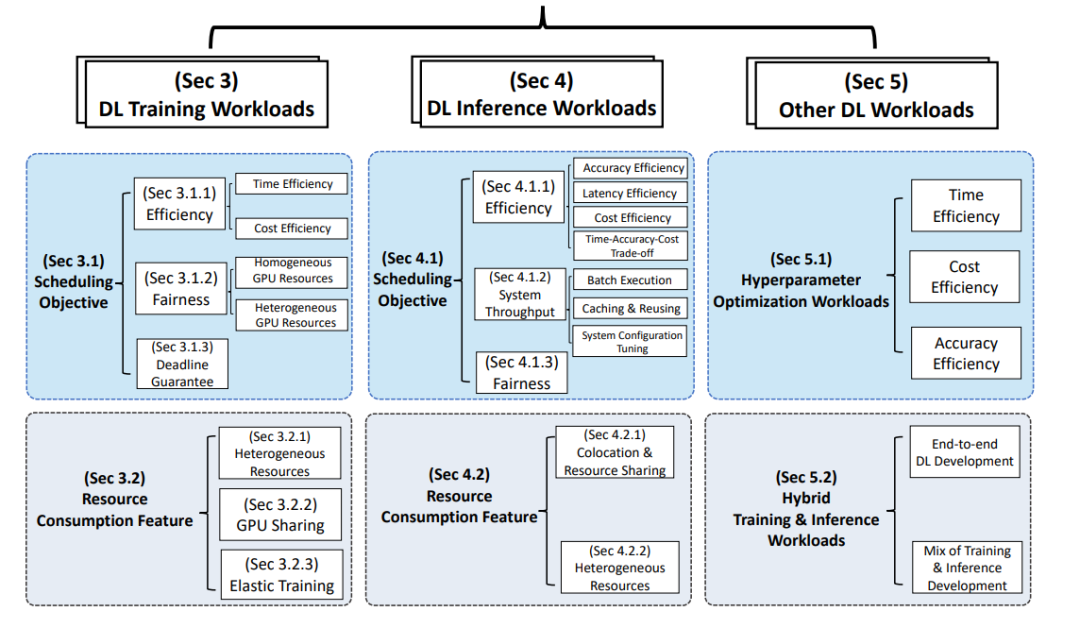
论文结构
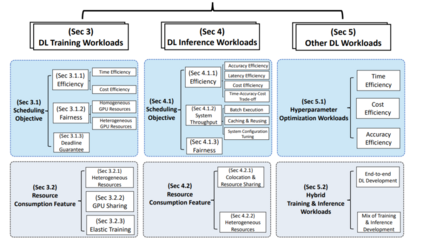
本文的结构如下: 第2节描述了DL工作负载的独特特征以及GPU数据中心调度的挑战。它也说明了这次调研的范围。本次调研的主体部分如图1所示。具体而言,第3节和第4节分别基于调度目标和资源消耗特征对训练和推理工作量进行了详细的分类。第5节讨论了其他工作负载,例如超参数优化、混合训练和推理工作负载。在每一节的末尾也给出了这些研究的启示。第6节总结了这篇调研论文,并确定了调度程序设计的未来方向。
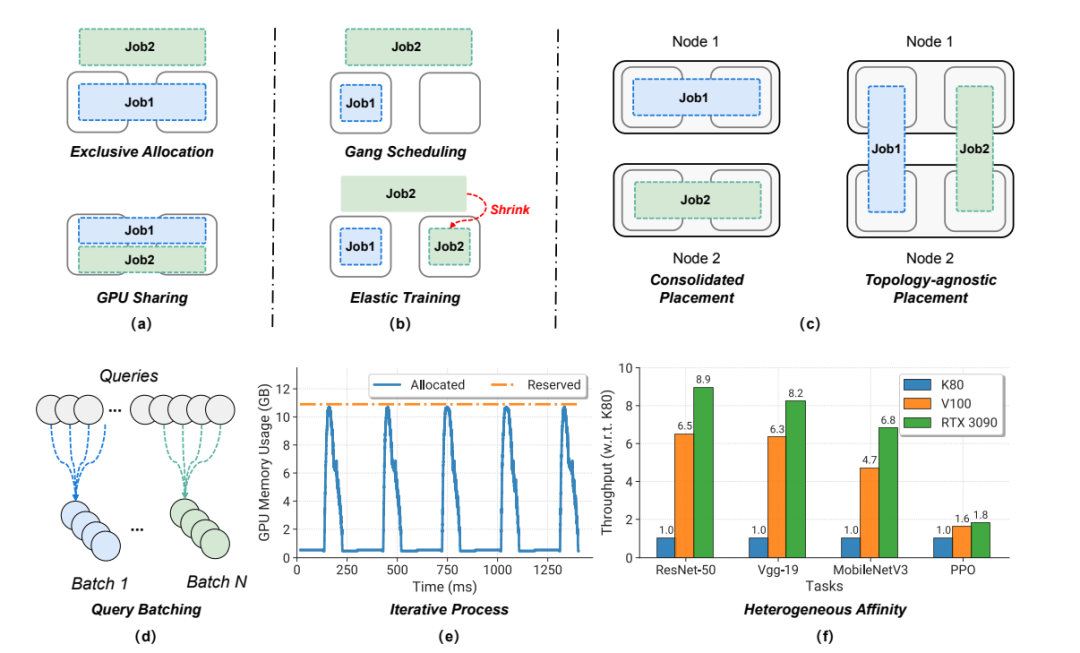
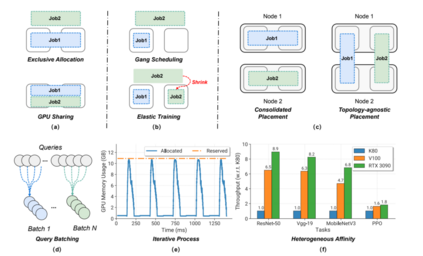
图2 训练和推断工作量的特征。(a)独占分配vs GPU共享。(b) Gang Scheduling vs弹性训练。(c)合并布局vs .拓扑不可知布局。(d)推理中的查询批处理机制。e)迭代过程:通过torch分配和保留GPU内存跟踪。profiler (ResNet-50 ImageNet分类任务)。(f)异构亲和(Heterogeneous Affinity): GPU各代之间的加速幅度在不同任务之间存在显著差异。