近年来,检索增强生成(RAG)在应对大语言模型(LLMs)挑战方面取得了显著成功,而无需重新训练模型。通过引用外部知识库,RAG能够改进LLM的输出,有效缓解诸如“幻觉”、缺乏领域特定知识和信息过时等问题。然而,数据库中不同实体之间复杂的关系结构对RAG系统提出了挑战。对此,GraphRAG利用实体之间的结构信息,使得检索更加精确和全面,能够捕捉到关系性知识,并促进生成更准确且具有上下文意识的响应。鉴于GraphRAG的创新性和潜力,对当前技术的系统性回顾显得尤为重要。本文首次提供了对GraphRAG方法的全面综述。我们形式化了GraphRAG的工作流程,涵盖了基于图的索引、图引导的检索以及图增强生成。接着,我们概述了每个阶段的核心技术和训练方法。此外,我们还探讨了GraphRAG在下游任务、应用领域、评估方法和工业案例中的应用。最后,我们展望了未来的研究方向,以激发进一步的探索并推动该领域的进展。
引言
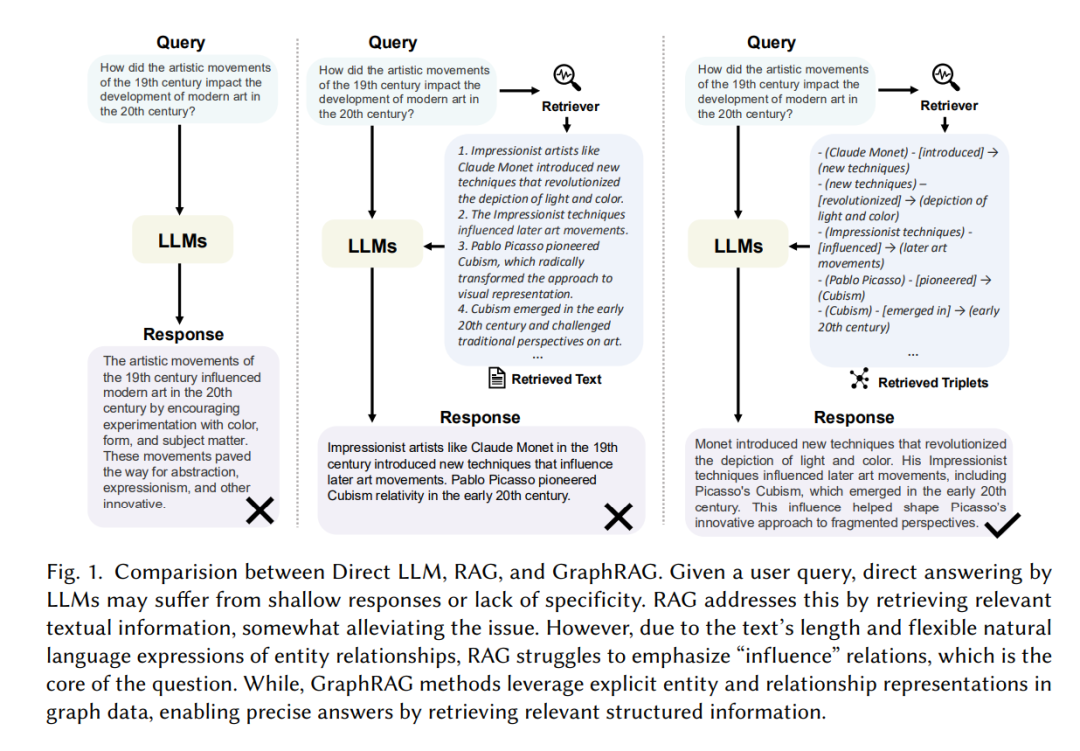
大型语言模型(LLM)如GPT-4 [116]、Qwen2 [170]和LLaMA [24]的开发引发了人工智能领域的革命,根本性地改变了自然语言处理的格局。这些模型基于Transformer [149]架构构建,并在多样且广泛的数据集上进行训练,展现了前所未有的理解、解释和生成人类语言的能力。这些进展的影响深远,覆盖了包括医疗 [93, 154, 188]、金融 [84, 114]和教育 [38, 157]等在内的多个领域,促进了人与机器之间更细致和高效的互动。尽管这些模型在语言理解和文本生成方面展现了卓越的能力,但由于缺乏领域特定知识、实时更新信息和专有知识(这些信息不在LLM的预训练语料中),LLM可能会表现出一定的局限性。这些缺口可能导致“幻觉”现象 [53],即模型生成不准确甚至虚构的信息。因此,补充LLM外部知识以缓解这一问题显得尤为重要。检索增强生成(RAG) [27, 37, 51, 54, 165, 180, 187]作为一项重要的进化,通过在生成过程中集成检索组件,旨在提升生成内容的质量和相关性。RAG的本质在于其动态查询大型文本语料库,以将相关的事实性知识整合到生成的语言模型响应中。这种整合不仅丰富了响应的上下文深度,还确保了更高程度的事实准确性和特异性。由于其出色的性能和广泛的应用,RAG已成为该领域的一个重要研究热点。 尽管RAG取得了令人印象深刻的成果,并在多个领域得到了广泛应用,但在实际场景中仍面临一些局限:(1) 忽略关系:在实践中,文本内容并非孤立存在,而是相互关联的。传统的RAG未能捕捉到无法通过语义相似性单独表示的重要结构化关系知识。例如,在一个通过引用关系链接的文献网络中,传统的RAG方法只关注基于查询找到相关文献,但忽略了文献之间的重要引用关系。(2) 冗余信息:RAG在作为提示时通常以文本片段的形式重新叙述内容。这使得上下文变得过于冗长,导致“中间迷失”困境 [94]。(3) 缺乏全局信息:RAG只能检索到文档的一个子集,难以全面掌握全局信息,因此在处理诸如查询聚焦摘要(QFS)之类的任务时表现不佳。
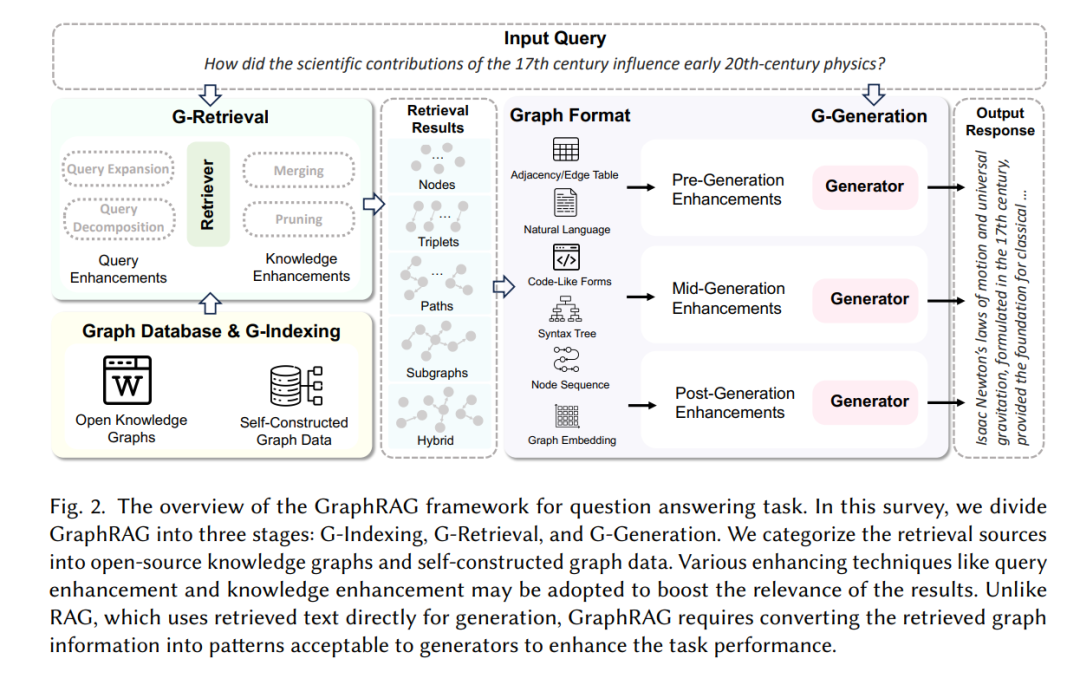
图检索增强生成(GraphRAG)[25, 50, 108]作为一种创新解决方案,旨在应对这些挑战。与传统的RAG不同,GraphRAG从预构建的图数据库中检索与给定查询相关的图元素,如图1所示。这些元素可能包括节点、三元组、路径或子图,并用于生成响应。GraphRAG考虑了文本之间的相互联系,使得关系信息的检索更加准确和全面。此外,图数据(如知识图谱)提供了对文本数据的抽象和总结,从而显著缩短了输入文本的长度,缓解了冗长问题。通过检索子图或图社区,我们可以获取全面的信息,利用图结构中的广泛上下文和相互联系来有效应对QFS挑战。
本文首次提供了对GraphRAG的系统综述。具体而言,我们首先介绍了GraphRAG的工作流程以及支撑该领域的基础背景知识。接着,我们根据GraphRAG流程的主要阶段分类文献:基于图的索引(G-Indexing)、图引导的检索(G-Retrieval)和图增强生成(G-Generation),分别在第5、6和7节详细介绍每个阶段的核心技术和训练方法。此外,我们还探讨了GraphRAG的下游任务、应用领域、评估方法和工业案例。本次探索阐明了GraphRAG在实际应用中的使用情况,并展示了其在各个领域的多样性和适应性。最后,我们认识到GraphRAG的研究仍处于早期阶段,探讨了未来的潜在研究方向。此预测性讨论旨在为未来的研究铺平道路,激发新的研究思路,并推动该领域的进展,最终推动GraphRAG走向更加成熟和创新的方向。
我们的贡献可总结如下:
我们提供了现有最新GraphRAG方法的全面系统回顾。我们提出了GraphRAG的正式定义,概述了其通用工作流程,包括G-Indexing、G-Retrieval和G-Generation。
我们讨论了现有GraphRAG系统的核心技术,包括G-Indexing、G-Retrieval和G-Generation。对于每个组件,我们分析了模型选择、方法设计和增强策略的广泛范围。此外,我们对这些模块中使用的不同训练方法进行了对比。
我们详细描述了GraphRAG的下游任务、基准、应用领域、评估指标、当前挑战和未来研究方向,讨论了该领域的进展和前景。此外,我们还汇编了现有工业GraphRAG系统的清单,提供了学术研究向现实世界工业解决方案转化的见解。
组织结构。本文的其余部分安排如下:第2节比较了相关技术,第3节概述了GraphRAG的一般流程。第5至7节对GraphRAG三个阶段(G-Indexing、G-Retrieval和G-Generation)相关的技术进行了分类。第8节介绍了检索器和生成器的训练策略。第9节总结了GraphRAG的下游任务、对应的基准、应用领域、评估指标和工业GraphRAG系统。第10节展望了未来的研究方向。最后,第11节总结了本次综述的内容。