大型语言模型(LLMs)展示了强大的能力,但在实际应用中仍面临挑战,如幻觉现象、知识更新缓慢,以及在回答中缺乏透明度。检索增强生成(RAG)指的是在使用LLMs回答问题之前,从外部知识库中检索相关信息。RAG****已被证明能显著提高答案的准确性,减少模型的幻觉现象,特别是对于知识密集型任务。通过引用来源,用户可以验证答案的准确性,并增加对模型输出的信任。它还促进了知识更新和特定领域知识的引入。RAG有效地结合了LLMs的参数化知识和非参数化的外部知识库,使其成为实施大型语言模型的最重要方法之一。本文概述了LLMs时代RAG的发展范式,总结了三种范式:Naive RAG、Advanced RAG和Modular RAG。然后,它提供了RAG的三个主要组成部分的总结和组织:检索器、生成器和增强方法,以及每个组件中的关键技术。此外,它讨论了如何评估RAG模型的有效性,介绍了RAG的两种评估方法,强调了评估的关键指标和能力,并提出了最新的自动评估框架。最后,从垂直优化、横向可扩展性以及RAG的技术栈和生态系统三个方面介绍了潜在的未来研究方向。
大型语言模型(LLMs)在自然语言处理(NLP)领域的表现超越了之前任何模型。GPT系列模型[Brown et al., 2020, OpenAI, 2023]、LLama系列模型[Touvron et al., 2023]、Gemini[Google, 2023]以及其他大型语言模型在多个评估基准上展现了卓越的语言和知识掌握能力,超越了人类水平[Wang et al., 2019, Hendrycks et al., 2020, Srivastava et al., 2022]。 然而,大型语言模型也显示出许多缺点。它们常常制造虚假事实[Zhang et al., 2023b],在处理特定领域或高度专业化的查询时缺乏知识[Kandpal et al., 2023]。例如,当所需信息超出模型训练数据的范围或需要最新数据时,LLM可能无法提供准确的答案。这一限制在将生成型人工智能部署到现实世界的生产环境中构成挑战,因为盲目使用黑盒LLM可能不够。
传统上,神经网络通过微调模型以参数化知识来适应特定领域或专有信息。虽然这种技术取得了显著成果,但它需要大量的计算资源,成本高昂,并需要专业的技术专长,使其适应性较差。参数化知识和非参数化知识发挥着不同的作用。参数化知识通过训练LLMs获得,并存储在神经网络权重中,代表了模型对训练数据的理解和概括,构成生成回应的基础。另一方面,非参数化知识存在于外部知识源中,如向量数据库,不直接编码到模型中,而是作为可更新的补充信息。非参数化知识使LLMs能够访问和利用最新或特定领域的信息,提高回应的准确性和相关性。
纯参数化的语言模型(LLMs)将从大量语料库中获得的世界知识存储在模型的参数中。然而,这类模型存在局限性。首先,难以保留训练语料中的所有知识,尤其是较不常见和更具体的知识。其次,由于模型参数无法动态更新,参数化知识随时间容易过时。最后,参数的扩展导致训练和推理的计算开销增加。为了解决纯参数化模型的限制,语言模型可以采用半参数化方法,通过将非参数化语料库数据库与参数化模型整合。这种方法被称为检索增强生成(RAG)。
检索增强生成(RAG)这一术语最初由[Lewis et al., 2020]引入。它结合了预训练的检索器和预训练的seq2seq模型(生成器),并进行端到端微调,以更可解释和模块化的方式捕获知识。在大型模型出现之前,RAG主要专注于端到端模型的直接优化。检索方面常见的做法是密集检索,如使用基于向量的密集通道检索(DPR)[Karpukhin et al., 2020],以及在生成方面训练较小的模型。由于整体参数规模较小,检索器和生成器通常会进行同步的端到端训练或微调[Izacard et al., 2022]。
自ChatGPT等LLM出现后,生成型语言模型成为主流,在各种语言任务中展现出令人印象深刻的性能[Bai et al., 2022, OpenAI, 2023, Touvron et al., 2023, Google, 2023]。然而,LLMs仍面临幻觉[Yao et al., 2023, Bang et al., 2023]、知识更新和数据相关问题。这影响了LLMs的可靠性,在某些严肃任务场景中,尤其是需要访问大量知识的知识密集型任务中,LLMs表现不佳,如开放领域问答[Chen and Yih, 2020, Reddy et al., 2019, Kwiatkowski et al., 2019]和常识推理[Clark et al., 2019, Bisk et al., 2020]。参数内的隐含知识可能不完整且不足。
后续研究发现,将RAG引入大型模型的上下文学习(ICL)中可以缓解上述问题,具有显著且易于实现的效果。在推理过程中,RAG动态地从外部知识源检索信息,使用检索到的数据作为参考来组织答案。这显著提高了回应的准确性和相关性,有效解决了LLMs中存在的幻觉问题。这种技术在LLM问世后迅速受到关注,已成为改善聊天机器人和使LLM更实用的最热门技术之一。通过将事实知识与LLMs的训练参数分离,RAG巧妙地结合了生成模型的强大能力和检索模块的灵活性,为纯参数化模型固有的知识不完整和不足问题提供了有效的解决方案。
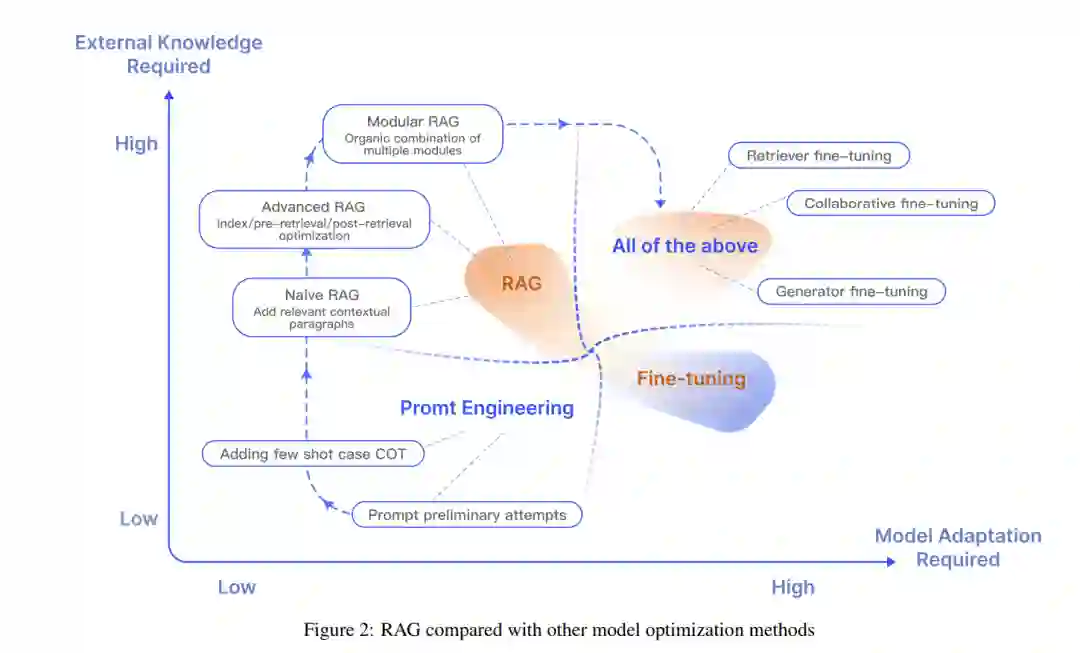
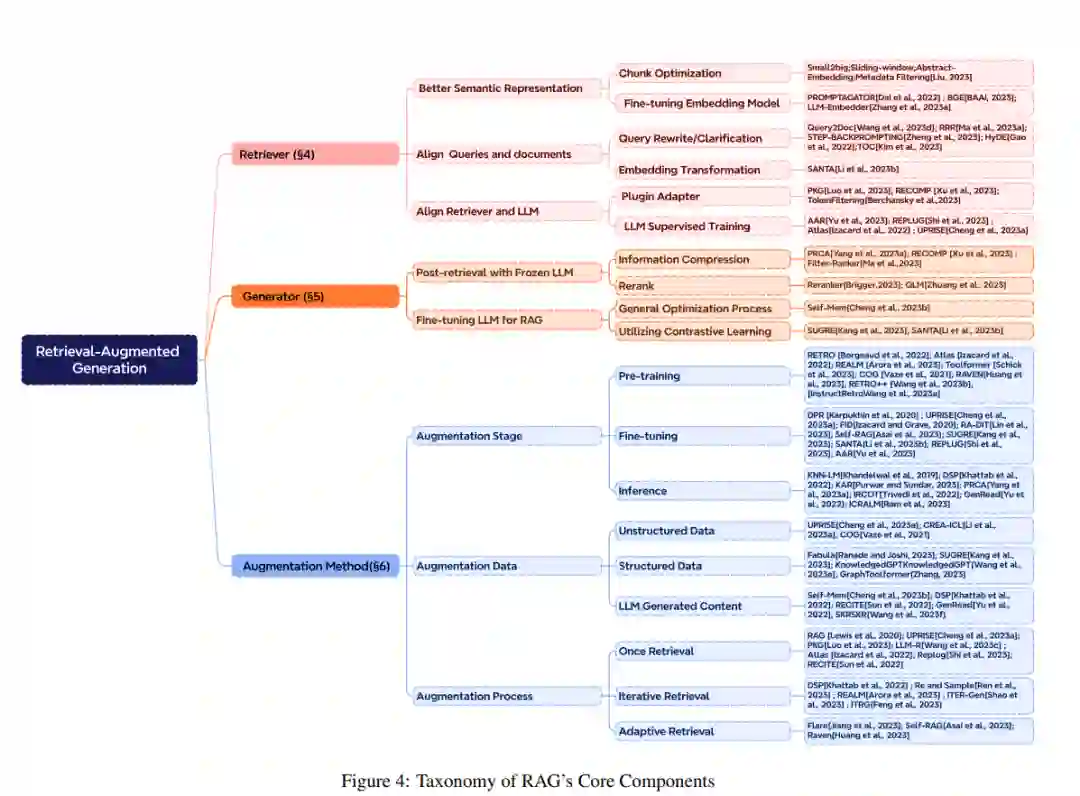
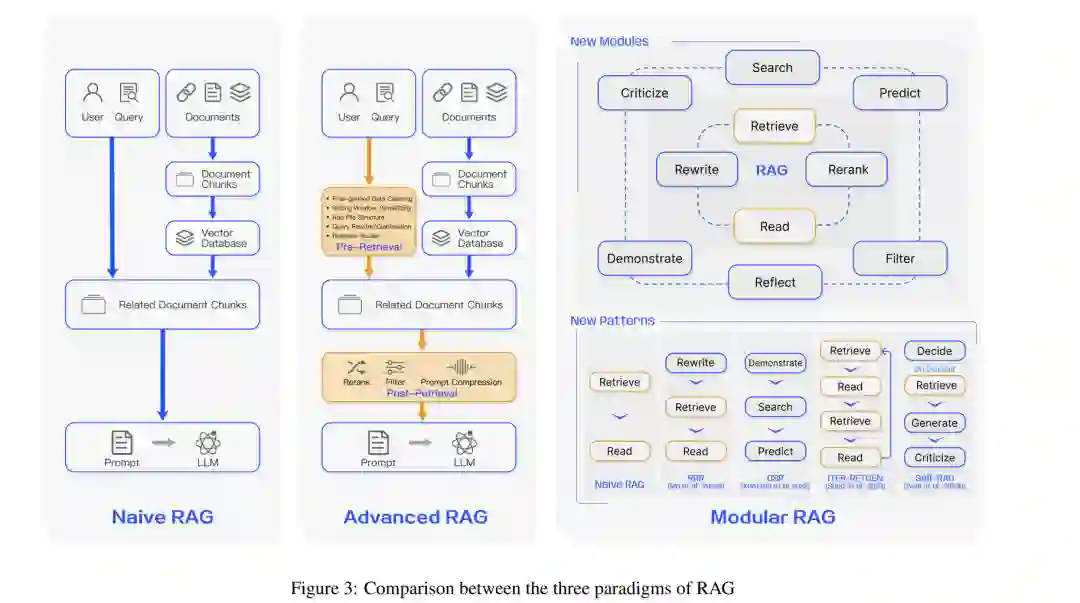
本文系统地回顾和分析了RAG的当前研究方法和未来发展路径,将其归纳为三个主要范式:Naive RAG、Advanced RAG和Modular RAG。随后,论文提供了三个核心组成部分的综合总结:检索、增强和生成,突出了RAG的改进方向和当前技术特点。在增强方法部分,当前的工作被组织为三个方面:RAG的增强阶段、增强数据源和增强过程。此外,论文总结了评估系统、适用场景和与RAG相关的其他内容。通过本文,读者将对大型模型和检索增强生成有更全面和系统的了解。他们将熟悉知识检索增强的演变路径和关键技术,能够辨别不同技术的优缺点,识别适用场景,并探索当前实际应用中的典型案例。值得注意的是,在以前的工作中,Feng et al.[2023b]系统回顾了将大型模型与知识结合的方法、应用和未来趋势,主要关注知识编辑和检索增强方法。Zhu et al.[2023]介绍了大型语言模型检索系统增强的最新进展,特别关注检索系统。同时,Asai et al.[2023a]专注于“什么”、“何时”、“如何”的问题,分析并阐释了基于检索的语言模型的关键过程。与之相比,本文旨在系统地概述检索增强生成(RAG)的整个过程,并特别关注通过知识检索增强大型语言模型生成的研究。
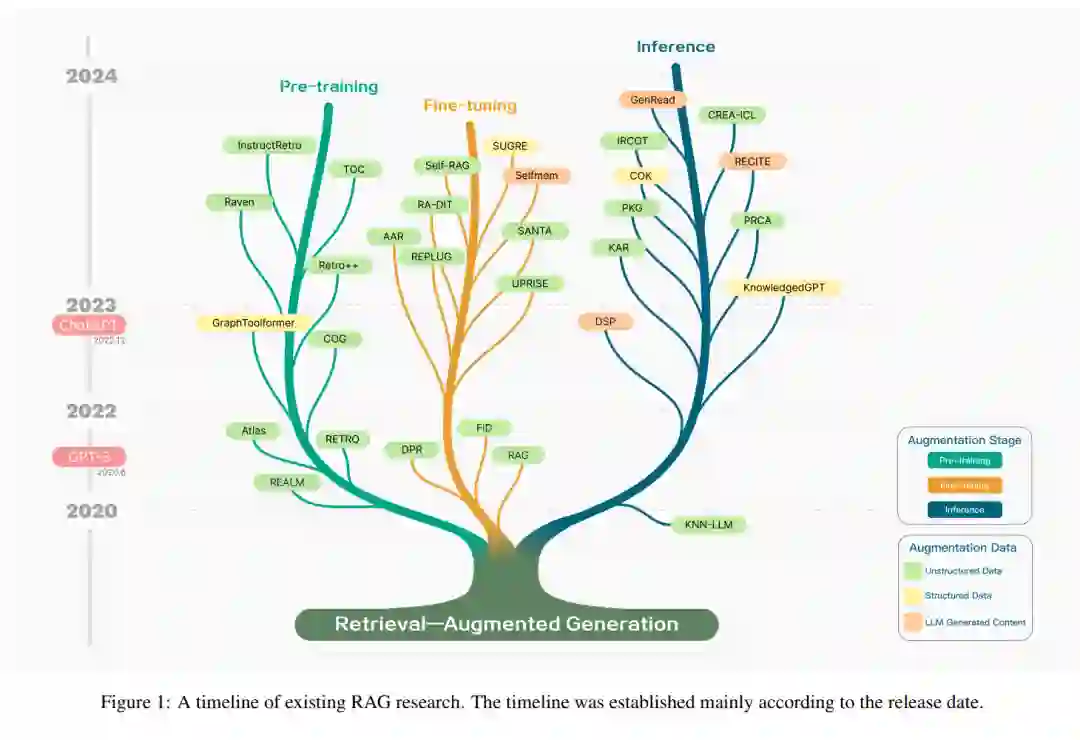
RAG算法和模型的发展在图1中进行了说明。在时间线上,大部分与RAG相关的研究都是在2020年之后出现的,2022年12月ChatGPT发布成为一个重要的转折点。自ChatGPT发布以来,自然语言处理领域的研究进入了大模型时代。Naive RAG技术迅速获得重视,导致相关研究数量的快速增加。在增强策略方面,自RAG概念提出以来,就一直在进行预训练和监督微调阶段的强化研究。然而,在推理阶段的强化研究大多出现在LLMs时代。这主要是由于高性能大模型的高训练成本。研究人员试图通过在推理阶段包含RAG模块,以成本有效的方式将外部知识融入模型生成中。关于增强数据的使用,早期的RAG主要关注于非结构化数据的应用,特别是在开放域问答的背景下。随后,检索的知识来源范围扩展,使用高质量数据作为知识来源有效地解决了大模型中错误知识内化和幻觉等问题。这包括结构化知识,知识图谱是一个代表性的例子。最近,自我检索引起了更多的关注,这涉及到挖掘LLMs本身的知识以增强它们的性能。
本论文的后续章节结构如下:第二章介绍RAG的背景。第三章介绍RAG的主流范式。第四章分析RAG中的检索器。第五章着重介绍RAG中的生成器。第六章强调介绍RAG中的增强方法。第七章介绍RAG的评估系统。第八章提供了对RAG未来发展趋势的展望。最后,在第九章中,我们总结了本综述的主要内容。