信息检索(IR)系统是用户获取信息的关键工具,在搜索引擎、问答系统和推荐系统等场景中广泛应用。传统的IR方法基于相似性匹配来返回文档的排序列表,多年来一直是信息获取的可靠手段,在IR领域占据主导地位。随着预训练语言模型的发展,生成式信息检索(GenIR)作为一种新兴范式出现,近年来受到越来越多的关注。目前,GenIR的研究可以分为两个方面:生成文档检索(GR)和可靠响应生成。GR利用生成模型的参数记忆文档,实现通过直接生成相关文档标识符的方式检索,无需显式索引。另一方面,可靠响应生成利用语言模型直接生成用户寻求的信息,打破了传统IR在文档粒度和相关性匹配方面的限制,提供了更多的灵活性、效率和创造性,从而更好地满足实际需求。本文旨在系统回顾GenIR的最新研究进展。我们将总结GR在模型训练、文档标识符、增量学习、下游任务适应、多模态GR和生成推荐方面的进展,以及在内部知识记忆、外部知识增强、生成带引用的响应和个人信息助理方面的可靠响应生成的进展。我们还将回顾GenIR系统在评估、挑战和未来展望方面的情况。这篇综述旨在为GenIR领域的研究人员提供一个全面的参考,鼓励在这一领域的进一步发展。
在当今的数字化环境中,信息检索(IR)系统对于浏览庞大的在线信息海洋至关重要。从使用谷歌[1]、必应[2]和百度[3]等搜索引擎,到与ChatGPT[3]和必应聊天[4]等问答或对话系统互动,再到通过亚马逊[5]和YouTube[6]等推荐平台发现内容,IR技术是我们日常在线体验的组成部分。这些系统不仅可靠,而且在全球传播知识和思想中发挥着关键作用。
传统的IR系统主要依赖于基于词级匹配的稀疏检索方法。这些方法包括布尔检索[7]、BM25[8]、SPLADE[9]和UniCOIL[10],它们建立了词汇与文档之间的联系,提供了高检索效率和强大的系统性能。随着深度学习的兴起,基于BERT模型[13]的双向编码表示的密集检索方法如DPR[11]和ANCE[12],捕获了文档的深层语义信息,显著提高了检索精度。尽管这些方法在准确性上取得了飞跃,但它们依赖于大规模文档索引[14, 15]并不能以端到端的方式优化。此外,当人们搜索信息时,他们真正需要的是一个精确可靠的答案。这种基于文档排名列表的IR方法仍然要求用户花时间总结他们所需的答案,对于信息检索来说并不理想[16]。
随着基于Transformer的预训练语言模型如T5[17]、BART[18]和GPT[19]的发展,它们已展示出强大的文本生成能力。近年来,大型语言模型(LLMs)在AI生成内容(AIGC)[20, 21]领域带来了革命性变革。基于大规模预训练语料库和高级训练技术如RLHF[22],LLMs[3, 23–25]在自然语言任务如对话[3, 26]和问答[27, 28]方面取得了重要进展。LLMs的迅速发展正在转变IR系统,催生了一种新的生成式信息检索(GenIR)范式,通过生成方法实现IR目标。
正如Metzler等人[16]所设想的,为了构建一个能像领域专家一样响应的IR系统,该系统不仅要提供准确的响应,还应包括源引用以提高结果的可信度和透明度。为实现这一目标,GenIR模型必须具备足够的记忆知识和回忆知识与相应文档之间关联的能力。当前GenIR的研究主要集中在两大模式上:(1)生成文档检索(GR),涉及通过生成其标识符来检索文档;(2)可靠响应生成,通过增强其可靠性的策略直接生成以用户为中心的响应。这两种模式是本调查的核心主题。
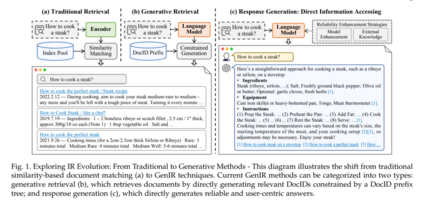
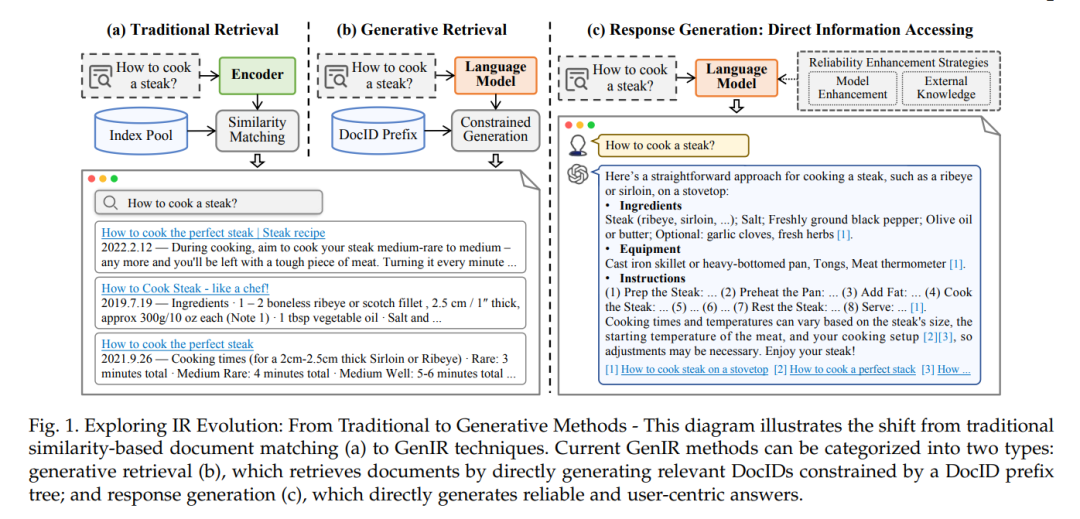
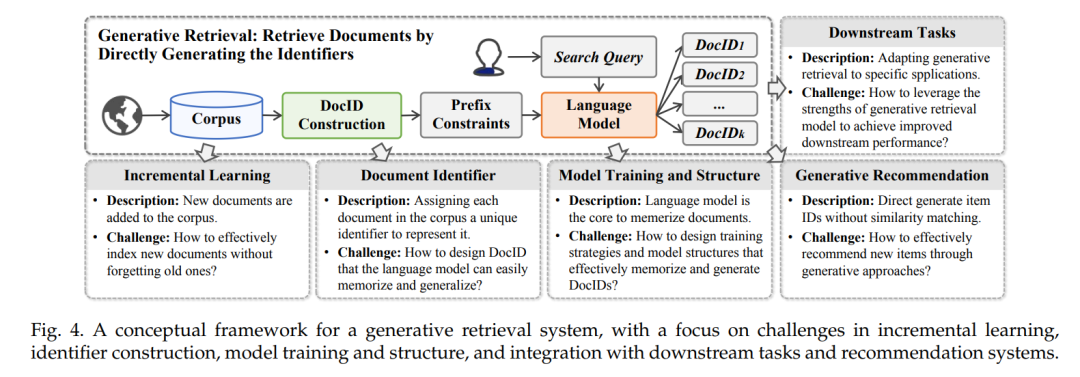
生成文档检索,基于生成模型的一种新检索范式,正在受到越来越多的关注。这种方法利用生成模型的参数记忆来直接生成与文档相关的文档标识符(DocIDs)[29–32]。图1展示了这一转变,其中传统IR系统基于索引数据库将查询与文档匹配(图1(a)),而生成方法使用语言模型通过直接生成相关文档标识符来检索(图1(b))。具体来说,GR为每个文档分配一个唯一标识符,可以是基于数字或文本的,然后训练生成检索模型学习从查询到相关文档DocIDs的映射。这使得模型可以使用其内部参数索引文档。在推理过程中,GR模型使用受限束搜索来限制生成的DocIDs在语料库中有效,根据生成概率对它们进行排名,以产生一个排序的DocIDs列表。这消除了传统检索方法中对大规模文档索引的需求,使检索模型的端到端训练成为可能。 近期关于生成检索的研究深入探讨了模型训练和结构[30, 31, 33, 34]、文档标识符设计[29, 30, 35, 36]、动态语料库上的持续学习[37-39]、下游任务适应[40-42]、多模态生成检索[43-45]以及生成推荐系统[46-48]。GR的进展正在将检索系统从匹配转向生成。这也导致了研讨会[49]、进展和挑战讨论[50]以及教程[51]的出现。然而,目前尚无全面的综述系统地组织这一新兴领域的研究、挑战和前景。
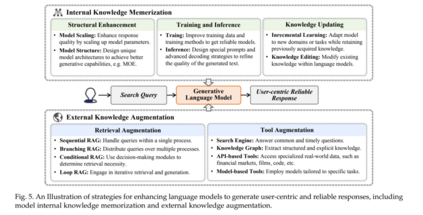
可靠响应生成也是IR领域中一个有前途的方向,提供直接满足用户需求的以用户为中心的准确答案。由于LLMs特别擅长遵循指令[20],能够生成定制化的响应,并且甚至可以引用知识来源[52, 53],使得直接响应生成成为获取信息的一种新而直观的方式[54-56]。如图1所示,生成方法标志着从传统IR系统(如图1(a,b)所示的返回文档排序列表)向直接生成详细的、以用户为中心的响应的更动态的信息获取形式的重大转变,从而为用户查询背后的信息需求提供了更丰富和更直接的理解。
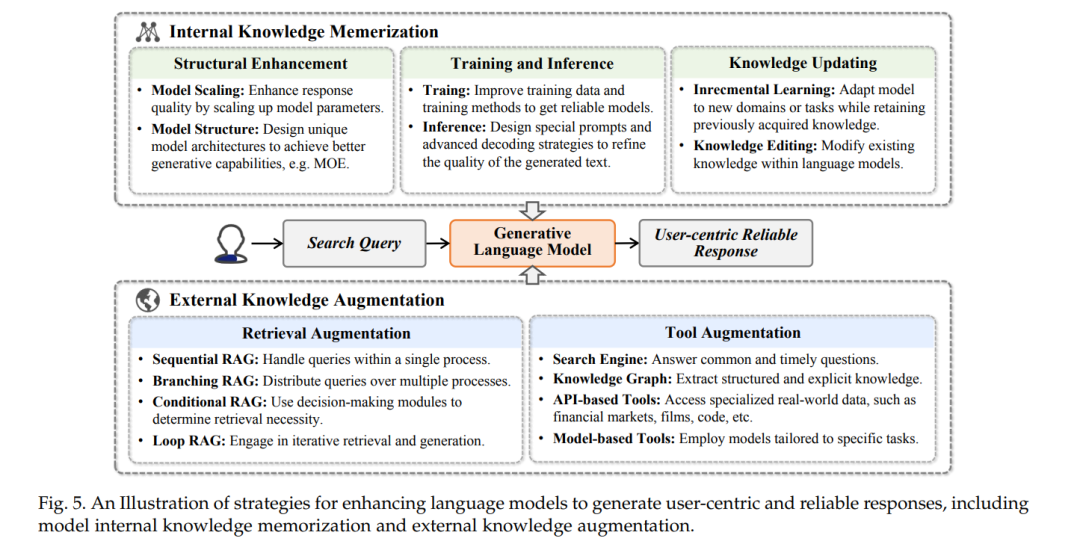
然而,由语言模型生成的响应可能并不总是可靠的。它们有可能生成不相关的回答[57],与事实信息相矛盾[58, 59],提供过时的数据[60],或生成有害内容[61, 62]。因此,这些限制使它们不适用于需要准确和最新信息的许多场景。为应对这些挑战,学术界在四个关键方面开发了策略:增强内部知识[63-71];增加外部知识[52, 72-78];生成带引用的回答[52, 79-82];以及改进个人信息助理[83-86]。尽管有这些努力,但仍缺乏一个系统的综述来组织这一新兴的生成信息获取范式下的现有研究。
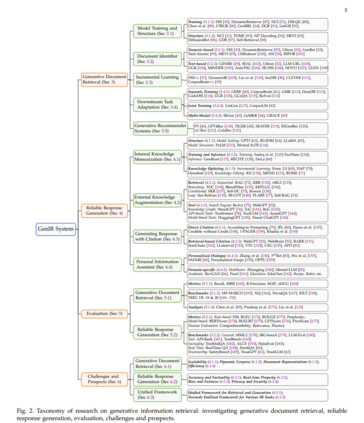
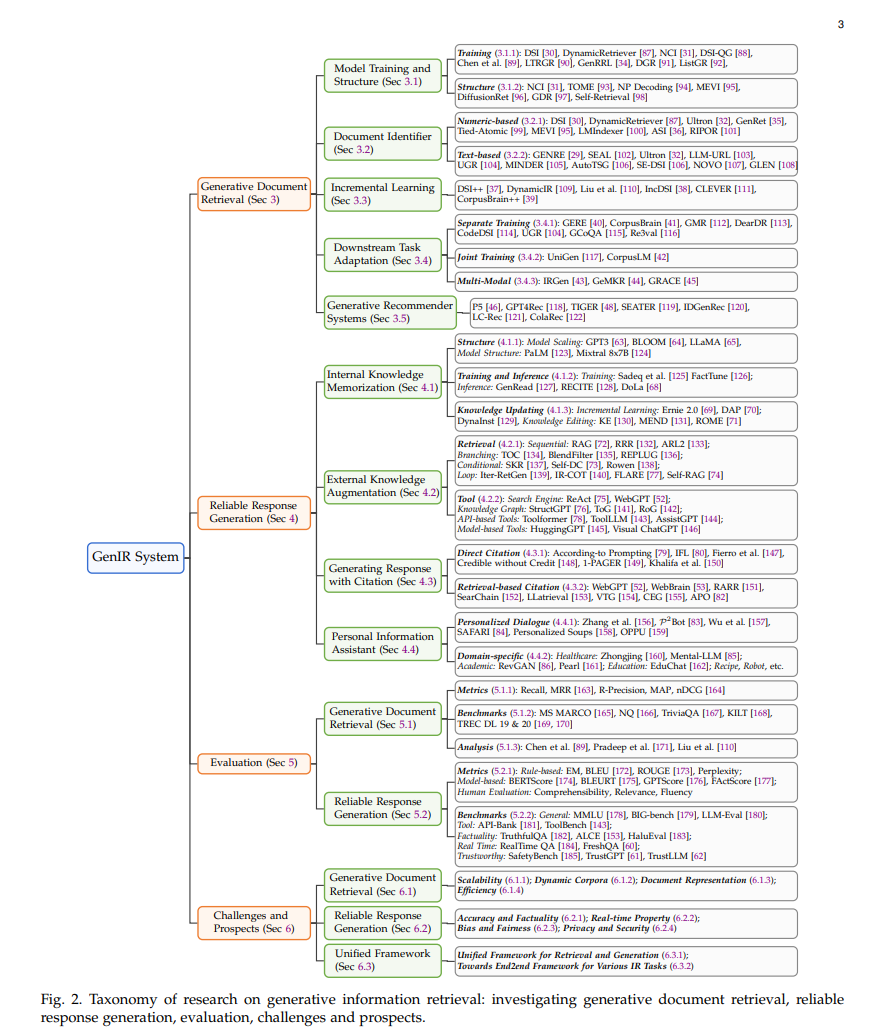
本综述将系统地回顾GenIR领域的最新研究进展和未来发展,如图2所示,展示了与GenIR系统相关研究的分类。我们将在第2节介绍背景知识,在第3节介绍生成文档检索技术,在第4节讨论使用生成语言模型直接访问信息,在第5节进行评估,在第6节分别探讨当前挑战和未来方向。第7节将总结本综述的内容。本文是第一个系统地组织生成IR的研究、评估、挑战和前景的文章,同时也期待GenIR未来发展的潜力和重要性。通过本综述,读者将深入了解发展GenIR系统的最新进展以及它如何塑造信息获取的未来。
生成文档检索:从基于相似性的匹配到生成文档标识符
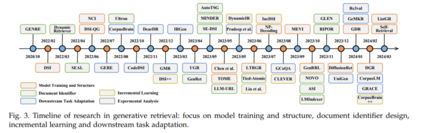
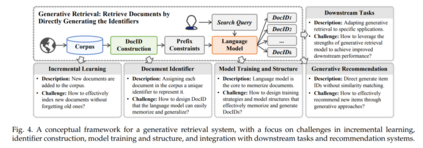
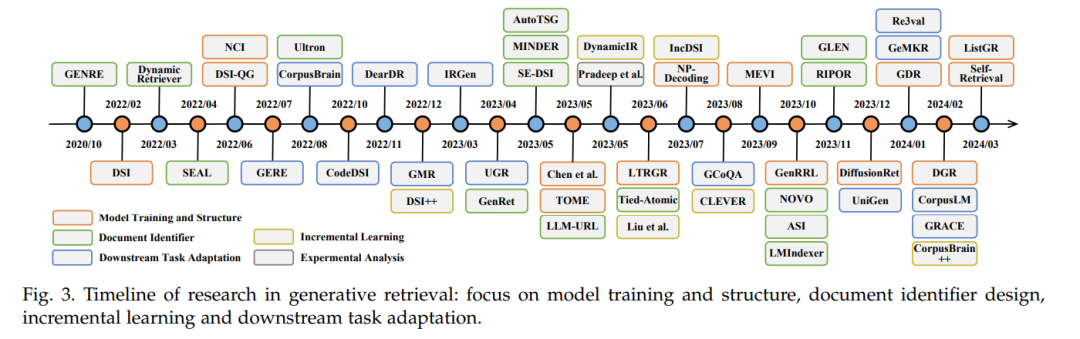
在AI生成内容(AIGC)的最新进展中,生成检索(GR)作为信息检索领域的一种有前景的方法出现,越来越受到学术界的关注。图3展示了GR方法的时间线。最初,GENRE [29] 提议通过预建的实体前缀树和受限束搜索生成它们的独特名称来检索实体,实现了先进的实体检索性能。随后,Metzler等人 [16] 设想了一个基于模型的信息检索框架,旨在结合传统文档检索系统和预训练语言模型的优势,创建能够在各个领域提供专家级质量答案的系统。 在他们的引领下,开发了包括DSI [30]、DynamicRetriever [87]、SEAL [102]、NCI [31] 等在内的多种方法,这些方法的研究工作不断增长。这些方法探索了模型训练和架构、文档标识符、增量学习、任务特定适应和生成推荐等各个方面。图4提供了GR系统的概览,我们将在后续章节中对每个相关挑战进行深入讨论。
**可靠响应生成:使用生成语言模型直接访问信息 **
大型语言模型的快速发展已将其定位为一种新型的信息检索(IR)系统,能够直接生成与用户信息需求紧密对齐的可靠响应。这不仅节省了用户在收集和整合信息时的时间,还提供了个性化的、以用户为中心的答案,专为个别用户量身定制。 然而,在创建一个提供忠实答案的扎实系统时,仍然存在挑战,例如幻觉、推理时间延长和高运营成本。本节将讨论构建一个忠实的生成式信息检索(GenIR)系统的策略,重点在于优化模型内部以及通过外部知识增强模型。
结论
在这项综述中,我们探讨了生成式信息检索(GenIR)的最新研究发展、评估、当前挑战和未来方向。我们讨论了GenIR领域的两个主要方向:生成文档检索(GR)和可靠响应生成。具体来说,我们系统地回顾了GR的进展,包括模型训练、文档标识符设计、增量学习、适应下游任务、多模态GR和生成推荐系统;以及在内部知识记忆、外部知识增强、生成带引用的响应和个人信息助理方面的可靠响应生成的进步。此外,我们整理了GR和响应生成的现有评估方法和基准。我们组织了GR系统的当前限制和未来方向,解决了可扩展性、处理动态语料库、文档表示和效率挑战。进一步地,我们识别了可靠响应生成中的挑战,如准确性、实时能力、偏见与公平、隐私和安全。我们提出了潜在的解决方案和未来研究方向来应对这些挑战。最后,我们还设想了一个统一框架,包括统一的检索和生成任务,甚至建立一个能够处理各种信息检索任务的端到端框架。通过这篇综述,我们希望为GenIR领域的研究者提供一个全面的参考,以进一步推动这一领域的发展。