

近年来,生成性语言模型(如ChatGPT,由OpenAI于2022年发布)的能力和普遍可用性有了显著进步,通过生成流畅、近似人类的文本带来了各种各样的好处。然而,区分人类和大型语言模型(LLM)生成的文本成为了一个至关重要的问题。这些模型有可能通过生成看似由人生成的人工文本来进行欺骗。在法律、教育和科学等领域,确保文本的完整性至关重要。本综述提供了目前用于区分人类和ChatGPT生成文本的各种方法的概览。我们介绍了为检测ChatGPT生成的文本构建的不同数据集,使用的各种方法,已经进行的有关人类与ChatGPT生成文本特性的定性分析,最后,我们将我们的发现总结为一般性的见解。

大型语言模型(LLM)在生成流畅、语法准确和令人信服的文本方面表现出了显著的能力。ChatGPT(由OpenAI于2022年发布)的引入被广泛认为是LLM领域里一个重要而又具有争议的里程碑。像GPT-3(Brown等人,2020年)和PaLM(Chowdhery等人,2022年)这样的模型已经在许多自然语言处理(NLP)任务中展示了LLM的强大能力。ChatGPT是第一个在NLP研究之外获得广泛应用的模型。
LLM(大型语言模型)性能的提升引发了关于其潜在社会影响的重要问题。LLM的风险多种多样,从自信地呈现错误信息到大规模生成假新闻(Sheng等人,2021年;Weidinger等人,2022年)。在这方面,ChatGPT也不例外(Zhuo等人,2023年)。 ChatGPT在多个领域内滥用的案例已经得到了记录,包括教育(Cotton等人,2023年)、科学写作(Gao等人,2022年)以及医疗领域(Anderson等人,2023年)。鉴于这一背景,机器生成文本的检测正引发越来越多的关注。这种检测是推动生成性语言模型负责任和适当使用的更大努力的一部分(Kumar等人,2023年)。 除了学术兴趣外,越来越多的商业方也在尝试解决这个任务。Pegoraro等人(2023年)最近的研究提供了商业和免费在线工具的概览。他们的工作与当前工作非常接近。然而,我们限制我们的范围仅为学术工作,并提供有关方法、数据集和定性洞见的额外背景信息。
近期已有多种方法、数据集和共享任务1被提出,用以解决检测机器生成文本的一般性(即,非特定于ChatGPT)任务(Jawahar等人,2020年)。鉴于ChatGPT的巨大应用和文化影响,我们将评述范围限制在直接为ChatGPT开发的数据集和方法。我们在ChatGPT所处的具有争议地位的背景下讨论这些方法,即在写作时,关于其训练设置或模型架构几乎没有可用信息。我们概述了此任务存在的一般方法,并审查了直接关注ChatGPT的数据集和方法的最新工作。 鉴于ChatGPT所处的特殊地位,我们还整合了从我们讨论的作品中获得的可能有助于人类检测ChatGPT生成文本的定性见解和发现。这些包括需要留意的语言特点或写作风格。最后,我们提出了这个检测任务面临的突出挑战和可能的未来方向。
我们的贡献如下: • 我们提供了机器生成文本检测的一般方法的概览。 • 我们概述了专门针对检测ChatGPT生成文本的研究,以及这与一般方法之间的关系。 • 我们展示了为这一检测任务创建和使用的数据集。 • 我们总结了这些最近的作品提供的定性分析,并尝试给出一般性的见解。
检测ChatGPT生成的文本
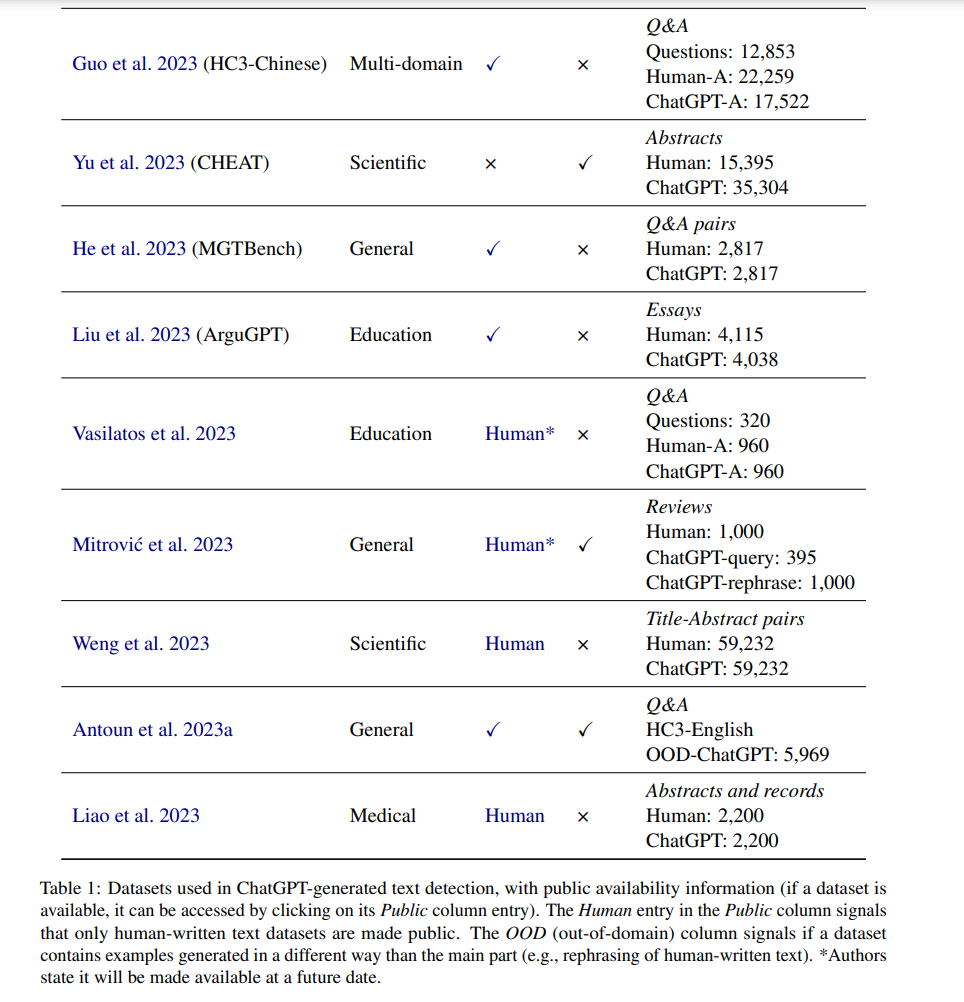
表1展示了可以用于执行分析或训练模型以区分人类和ChatGPT编写的文本的数据集。我们描述了它们是如何收集的,并提供有关它们领域和公开可用性的进一步信息。
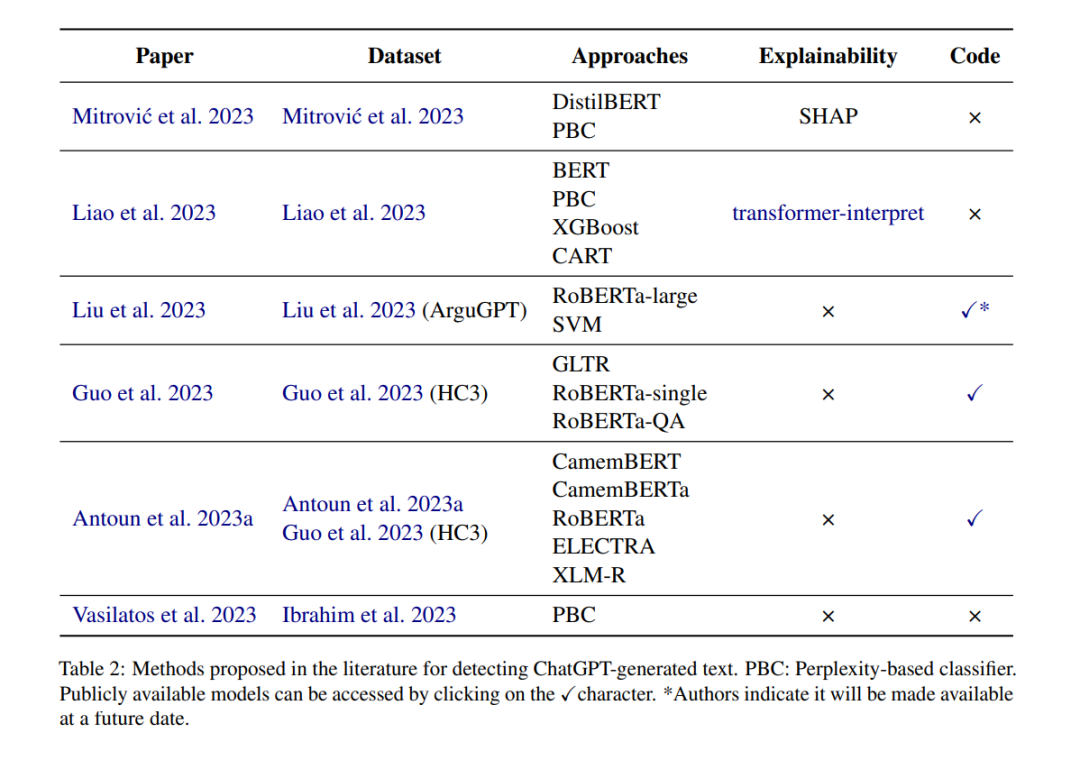
在本节中,我们报告了用于检测ChatGPT生成文本的各种方法。这篇综述的范围不包括对这些方法所获得结果的评估或比较。这一限制主要源于缺乏通用的实验设置以及使用不同数据集和度量标准。表2提供了这些近期方法的概览。 一些先前的工作已经使用基于变换器(transformer)的模型来分类由ChatGPT生成和人类编写的文本,正如Mitrovic等人(2023年)所示。他们的方法包括两个组成部分:一个检测模型和一个用于解释该模型决策的框架。他们首先对DistilBERT(Sanh等人,2019年)的不区分大小写版本进行微调,然后使用SHAP提供以特征重要性分数形式的局部解释,以深入了解模型结果中不同输入特征的重要性。作为基线比较,他们实现了一个基于困惑度(perplexity)的分类器,该分类器根据其困惑度分数对文本进行分类,其中GPT-2用于计算困惑度分数。他们的结果表明,基于DistilBERT的检测器的性能优于基于困惑度的分类器。然而,当考虑到由ChatGPT重新构词的数据集时,其性能下降。
在Liao等人(2023年)的研究中,提出了不同的模型来检测由ChatGPT生成的医学文本:一个微调过的BERT模型(Devlin等人,2019年),一个基于分类和回归树(CART)的模型,一个XGBoost模型(Chen和Guestrin,2016年)以及一个使用BioGPT(Luo等人,2022年)来计算文本困惑度的困惑度分类器。通过可视化样本的局部特征来解释BERT模型的预测,其中可以看到,使用连词(conjuncts)是该模型将医学文本分类为机器生成的一个关键特征。 Liu等人(2023年)微调了RoBERTa,以检测由不同GPT模型(包括ChatGPT)生成的论证性文章,并评估其在文档、段落和句子级别分类方面的性能。这些文章被拆分成段落和句子,以进行段落和句子级别的分类。他们使用不同的语言特征来训练和比较SVM模型的性能。这些模型作为与RoBERTa模型进行比较的基线,以及理解哪些语言特征能区分人类和ChatGPT生成的文本。
Guo等人(2023年)实现了一种基于机器学习和深度学习的检测器。他们使用了一个在GLTR Test-2数据集(Gehrmann等人,2019年)上训练的逻辑回归模型,以及两个基于对预训练的变换器模型RoBERTa进行微调的深度分类器。一个深度分类器是专门为单一文本检测设计的,而另一个则是为QA检测设计的。作者构建了各种不同版本的训练和测试数据集,以评估模型的鲁棒性。他们创建了全文、句子级和混合子集的收集语料库。每个子集都有一个原始版本和一个过滤版本,其中显著的指示词(如“Nope”和“Hmm”)或ChatGPT词语(如“AI助手”)被移除。模型的评估显示,基于RoBERTa的模型在性能方面优于GLTR,并表现出更强的抗干扰能力。此外,基于RoBERTa的模型不受指示词的影响。
继Guo等人(2023年)的工作之后,Antoun等人(2023a年)提出了一种用于开发能够在不同语言中检测ChatGPT生成文本的鲁棒检测器的方法,重点关注法语。他们的方法包括对预训练的基于变换器的模型在英语、法语和多语言数据集上进行微调。他们在英文数据集上训练了RoBERTa和ELECTRA(Clark等人,2020年)模型,在法文数据集上训练了CamemBERT(Martin等人,2020年)和CamemBERTa(Antoun等人,2023b年),以及在合并的英文和法文数据集上训练了XLM-R(Conneau等人,2020年)。他们评估了这些模型对对抗性攻击(如用同形异义字替换字符和添加拼写错误的词)的鲁棒性。考虑到领域内文本,他们的结果显示法文模型在检测机器生成文本方面表现良好,但被英文模型超过,而XLM-R则为英文和法文提供了对抗性攻击最佳和最具弹性的性能。然而,当在领域外文本上进行评估时,这种性能会下降。Vasilatos等人(2023年)提出的另一种用于检测ChatGPT生成文本的方法是一种基于度量的方法,通过使用GPT-2计算困惑度得分来检测机器生成的学生作业。他们表明,具有类别明智的阈值(从数据集元数据派生)比仅有一个阈值产生更好的检测性能。
结论
ChatGPT在生成高质量和令人信服的文本方面的出色能力引发了人们对其在不同领域中不当使用所带来风险的关注。因此,可靠地检测由ChatGPT生成的文本已成为一项重要任务。为了解决这一问题,已经提出了许多数据集和检测方法。在本文中,我们简要概述了创建的各种数据集,提出的方法,以及将人工写作的文本与ChatGPT生成的文本进行比较的定性见解。
在我们讨论的论文中,我们看到了各种各样的方法和数据集。一方面,这是好事,因为许多因素,如领域、语言或格式,都会影响检测任务。另一方面,我们也看到实验和数据集设置方面的巨大差异。一些工作使用对抗性示例,而其他工作则没有。有些允许由ChatGPT对人类文本进行改写,而其他则使用纯粹的人与机器生成的文本。有些工作包括用于生成数据的提示和ChatGPT版本;其他工作则没有。这些等其他差异使得进行比较变得困难,这也是我们在这次调查中不包括评分的一个原因。这也凸显了重要的未来工作,即在不同数据集之间测试方法,以及在不同方法之间测试数据集。
另一个需要考虑的因素是文本的领域。我们讨论的数据集涵盖了至少两个受ChatGPT风险影响的重要领域:健康和教育。一个值得注意的我们没有遇到的领域是(假)新闻。尽管这是NLP领域本身的一个大课题,但我们预计在ChatGPT的背景下会更多地关注它。未来的工作肯定可以在这方面有所帮助。文本的格式与领域有关,也是需要考虑的另一个重要因素。例如,我们提到的共享任务提供了推文、新闻文章或评论作为其格式。系统地查看与ChatGPT有关的格式和领域影响可能是宝贵的未来工作。
多语言性是另一个未解决的问题。与几乎所有NLP任务一样,我们看到英语不幸地是数据集中的主导语言。在不同语言之间进行实验和收集数据集是重要的未来方向。当前的任务还可以从机器翻译领域汲取灵感。该领域有着长期并持续不断地尝试检测(糟糕的)翻译文本,即所谓的“translationese”(Baroni和Bernardini,2006),这可以用于或者适应于检测一般机器生成的文本。
最后,一个我们还没有看到过多讨论的重要因素是ChatGPT的时间方面。输出可能会随着时间的推移而改变,尤其是因为它是一个封闭源系统。这就需要不断地进行反复测试,以确保检测方法的性能没有下降。机器生成的文本检测也是一场猫与老鼠的游戏;由于模型被优化以模仿人类语言,检测变得越来越困难。

