

语言模型,特别是预训练的大型语言模型,在作为少示例上下文学习者(ICL)方面展示了显著的能力,擅长仅通过输入上下文中的几个示例适应新任务。然而,模型执行ICL的能力对少示例演示的选择非常敏感。与其使用固定的示例集,一种新的发展趋势是检索针对每个输入查询定制的示例。演示检索的实现相对直接,利用现有的数据库和检索系统。这不仅提高了学习过程的效率和可扩展性,而且已显示出减少手动示例选择中固有偏见的潜力。鉴于这些鼓舞人心的结果和使用检索示例的ICL领域的研究日益增长,我们进行了这一领域研究的广泛综述。在这篇综述中,我们讨论并比较了不同的检索模型设计选择、检索训练程序和推理算法。
少示例上下文学习(ICL)是大型语言模型(LLMs)在给定新任务的几个输入-输出示例或演示以及实际任务输入时,执行新任务的能力。重要的是,模型参数不需要针对新任务进行微调。ICL的流行源于对预训练大型语言模型的研究,这些模型可以在没有被训练执行ICL的情况下执行ICL(Brown et al., 2020),尽管较小的语言模型也可以被明确训练以执行ICL(Min et al., 2022a)。ICL相较于传统方法(即先进行初始预训练,然后进行下游任务的微调)在适应语言模型到下游任务方面有几个优势。ICL的一个显著优点是避免了微调,这在由于无法访问模型参数或计算资源限制的情况下可能无法实现(Brown et al., 2020)。此外,ICL避免了微调常见的问题,例如过拟合(Ying, 2019; Kazemi et al., 2023a)。与参数高效微调方法(PEFT)相比(Hu et al., 2021; Dettmers et al., 2023; Lester et al., 2021),ICL在计算上更经济,且保持模型参数不变,从而保持了LLMs的通用性。早期ICL实现使用针对每个目标任务的固定示例集。这些示例可以由人工精心制作(Hendrycks et al., 2021; Wei et al., 2022; Kazemi et al., 2023b),从训练数据中随机选择(Brown et al., 2020; Lewkowycz et al., 2022),或基于复杂度或信息内容等指标选择(Fu et al., 2022; Hongjin et al., 2022; Li and Qiu, 2023a; Wang et al., 2023b)。此类示例的有效性受到示例质量、数量和排序等因素的影响。重要的是,这些示例保持与上下文无关(即不管查询如何,都使用相同的示例),这可能阻碍释放LLMs的真正潜力。
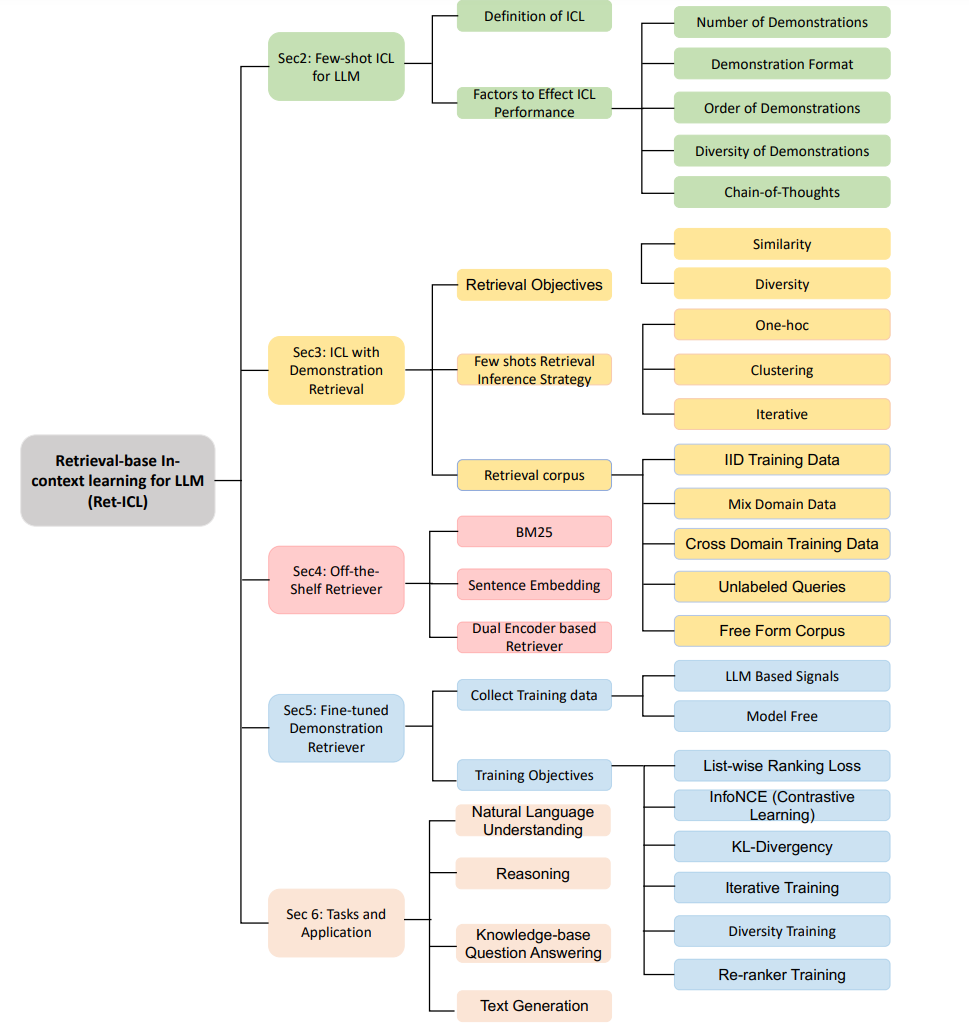
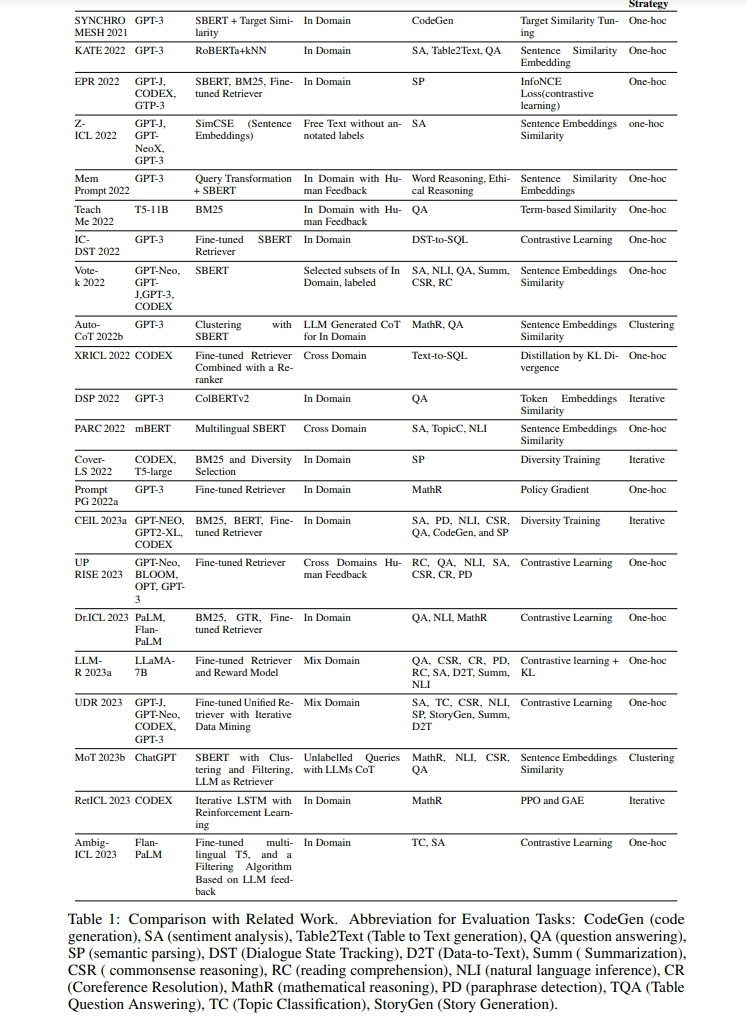
基于检索的ICL(RetICL)在优化语言模型性能方面呈现了一种范式转变,从静态、预定义的示例集转向动态、与上下文敏感的方法。这一创新的核心是自适应示例选择的概念,其中专门的检索器为每个具体任务输入智能地策划定制示例。这种方法不仅一致地优于依赖随机或静态手工制作示例的方法,而且还显示出对多种影响因素的显著抵抗力。RetICL的有效性取决于所选示例的“相关性”和“有用性”,这一过程受到多个因素的复杂影响。这些包括检索器的性质(从通用的现成模型到精细调整的特定领域变体)、检索语料库的来源和多样性、检索器的目标(专注于相似性或多样性)以及集成多个示例的策略。在过去两年中,众多有时并行的研究已经研究了RetICL,每个研究使用不同的术语,并在问题定义和随后的方法论上有所不同,使得理解RetICL的当前研究和实践状态,特别是对于该领域的新手来说,变得困难。在这篇全面的综述中,我们详细分析了RetICL领域的22篇开创性论文(如表1所示),并对其主要构建模块进行了分类(见图1)。我们的工作不仅提供了现有研究的全面综合,而且强调了RetICL在超越以往ICL方法方面的重要领域,并为该领域未来的创新照亮了许多前进的道路,因此成为ICL的关键资源。
少样本上下文学习的语言模型神经语言模型(LM)的增强能力催生了一种新的自然语言处理(NLP)问题学习范式。从历史上看,NLP问题的主导学习范式是从头开始对特定任务的数据进行模型训练。因此,对于每一个新任务,模型都必须从头开始学习。这通常导致泛化能力较差,尤其是在测试时遇到之前未观察到的词汇的情况下。在随后的范式中,首先在大量文本语料库上预训练一个LM,使其了解语言如何运作并获得关于世界的大量知识(Petroni et al., 2019; Lin et al., 2020; Sung et al., 2021; Yuan et al., 2023);然后再在新任务的数据上进一步对预训练的LM(PLM)进行微调(Sarzynska-Wawer et al., 2021; Devlin et al., 2018),从而教会通用的PLM新任务的特定内容。这一范式通常导致学习速度更快和预测性能更高。后来的研究表明,对PLM进行多任务微调可以更好地实现任务间知识转移,并可能导致在新任务上的性能提升(Raffel et al., 2020)。随着预训练大型语言模型(LLMs)的规模和用于预训练这些模型的数据集规模的增大,人们发现预训练的LLMs(为简洁起见,以下简称为LLMs)具有通过少量示例在上下文中学习的显著能力(Brown et al., 2020)。也就是说,LLMs被证明能够仅通过在输入中看到几个新任务的示例来适应新任务,而不需要额外的训练数据或微调。这通常被称为少示例上下文学习。

与上述涉及预训练后进行微调的大型语言模型(LLMs)使用方法相比,上下文学习(ICL)提供了几个关键优势。首先,由于对LLM的访问受限、计算资源不足或数据标记不充分(Brown et al., 2020),微调可能并不总是可行的,而ICL则需要更少的资源、更少的数据,并且通过API调用更易于服务。此外,ICL避免了常与微调相关的问题,如过拟合或冲击(Ying, 2019; Kazemi et al., 2023a),因为它不修改模型的参数,使其保持通用性。
**什么构成了好的演示?**许多研究试图提供理论上的解释和洞见,来说明大型语言模型(LLMs)是如何从少量上下文演示中学习的(Xie et al., 2021; Garg et al., 2022; Von Oswald et al., 2023)。然而,这种能力背后的确切原因仍然不甚明了,这使得选择最佳的少示例演示变得困难。幸运的是,各种实证结果展示了少示例演示对LLMs预测准确性的影响,并就准备它们的最佳实践提供了建议。这些研究还展示了LLMs在选择、格式和少示例演示顺序方面的脆弱性。在此,我们描述了其中一些更为显著的研究。
演示数量:大型语言模型(LLMs)通常受益于更多的演示,但随着演示数量的增加,改进的速度通常会减少(Brown et al., 2020; Ye et al., 2023b; Min et al., 2022b)。生成任务比分类任务更能从增加的演示数量中受益(Li et al., 2023)。增加演示数量的一个障碍是LLM的最大上下文大小。尽管随着新型LLM的出现,上下文的大小一直在增加,但对于文本输入较长的数据集或分类数据集中类别较多的情况,这可能仍然是个问题。
演示格式:不同的工作表明,提示的格式和措辞在LLM的性能中起着至关重要的作用(Jiang et al., 2020; Shin et al., 2020; Kojima et al.; Yang et al., 2023)。例如,Kojima等人展示了仅在提示中添加“让我们一步一步思考”可以使LLM逐步推理并解决更多问题,Weller等人(2023)展示了在提示中添加“根据维基百科”可以使其更具事实性。此外,Min et al.(2022b)指出,除了文本格式,标签空间和演示中的输入文本分布也非常重要。
演示顺序:演示的顺序已被证明会显著影响模型性能。例如,Lu et al.(2022b)表明,在某些任务上,模型性能可能会根据提示的顺序从接近随机到最先进水平不等,而Zhao et al.(2021)表明,在提示的末尾出现的答案更可能被模型预测。演示多样性:少示例学习成功的另一个重要因素是演示的多样性。Naik et al.(2023)提出了DiversePrompting方法,其中对于演示的问题,使用LLM生成解决问题的不同方法,然后将这些解决方案用于提示。Zhang et al.(2022b)建议选择一个多样化的问题集作为少示例。Ma et al.(2023)提出了一个公平性指标用于选择演示,鼓励选择多样化的少示例演示,以产生对语义自由输入的近似均匀预测分布。
思维链(CoT):已有研究表明,包含答案的理由显著提高了模型性能,尤其是对于超过特定大小的模型(Suzgun et al., 2022)。这种理由通常被称为思维链(CoT)(Wei et al., 2022)。在CoT提示的情况下,演示通常格式化为: 查询:qi,理由:ri,答案:ai其中理由出现在最终答案之前。已有多项研究探讨了CoT提示的有效性原因以及如何改进提示和理由(Wang et al., 2022a; Lanham et al., 2023)。
使用检索演示的上下文学习传统上,所有查询都使用相同的少示例演示集,这在查询之间存在高度变化时可能并不理想。另一种方法是检索针对当前查询定制的少示例演示。先前的工作表明,与手工策划或随机选择的演示相比,演示检索在任务指标上带来了显著改进(Luo et al., 2023; Ye et al., 2023a)。此外,当使用检索的演示时,已经证明大型语言模型(LLMs)对于演示顺序等因素(第2.2节)变得不那么敏感(Li et al., 2023)。本节提供了基于检索的上下文学习(RetICL)的概述。我们首先定义了使用检索演示的上下文学习。正式地,给定一个查询q∗和一个检索语料库C,演示检索器DR选择一组演示{d1, . . . , dk} ∼ C,其中每个演示为di = (qi, ai)。大型语言模型(LLM)的输入序列变为(d1, . . . , dk, q∗)。检索器的目标是选择能最大化正确答案a∗概率的演示。RetICL的成功取决于多个因素。本节探讨了设计选择,包括检索目标、检索推理策略和检索语料库。然后在第4节和第5节中,我们探索了检索器模型以及如何训练它们以适应下游任务。
检索目标:
相似性与多样性为了选择和定制适合大型语言模型(LLMs)的上下文示例,已经探索了各种检索目标(Luo et al., 2023; Rubin et al., 2022; Ye et al., 2023a; Dalvi et al., 2022; Cheng et al., 2023; Li et al., 2023)。选择演示的两个主要检索目标是相似性和多样性。相似性涉及选择最类似于查询的演示,并可基于语言相似性(术语匹配或语义匹配)、结构方面(句子结构、推理结构等)或其他标准。大多数研究关注语言相似性,较少涉及结构相似性,这通常是由于在许多任务中提取查询结构的挑战(Levy et al., 2022)。除了相似性,一些工作发现演示的多样性很重要。多样性的动机包括避免重复的演示(Zhang et al., 2022b),带来不同的视角(Yu et al., 2023),以及最大化演示对测试查询的覆盖,无论是覆盖其词汇还是句法结构(Levy et al., 2022)。衡量多个演示的多样性是一个主要的技术挑战。Ye et al. (2023a) 应用了决定性点过程(DPP)这一概率模型来衡量负相互作用(Kulesza et al., 2012),以衡量多样性。Levy et al. (2022) 发现当模型对输出符号空间不熟悉时,多样性和覆盖是重要的。值得注意的是,研究人员发现,在某些情况下,上下文学习(ICL)更多地从更高复杂性的演示中受益(Fu et al., 2022),其中复杂性是根据查询长度或推理步骤定义的。然而,Fu et al. (2022) 使用启发式规则来定义复杂性并相应地预选演示。他们的研究表明,使用基于相似性的检索器在特定的数学推理任务中提高了性能。这可能表明结合相似性和复杂性考虑可能是增强推理任务方法的一个有前景的策略。
现成演示检索器为了实现上述检索目标,研究人员探索了各种类型的演示检索器。典型的演示检索器将检索语料库中的示例和查询编码为一些向量表示,然后计算候选演示嵌入和查询嵌入之间的相似度度量(例如余弦相似度),以定位最相关的演示。鉴于对检索演示增强大型语言模型(LLMs)性能的底层机制理解有限,最初的研究工作集中在对这一任务现成可用的检索器进行启发式评估。后续研究努力探索了特别为检索演示而定制的基于学习的检索器的设计和开发。本节回顾了代表性的现成模型,我们将在第5节讨论基于学习的模型。
微调的演示检索器尽管现成的检索器在llm的检索演示中显示出了一些希望,但现成的检索器给出的检索演示可能不能代表任务的性质以及一般应如何解决任务。因此,它可能会导致次优性能。因此,研究人员已经开始探索基于学习的方法,以进一步突破边界。设计一个好的演示检索器的典型目标是:如果LLM发现一个演示在用作演示示例时有用,则应该鼓励检索器将演示排序更高。这使得我们可以直接依赖感兴趣任务中的查询和输出对的信号来训练模型,而无需人工注释。为了开发演示检索器,大多数方法利用当前的双编码器模型(Karpukhin等人,2020;Ni et al., 2021)。关键的变化在于收集训练数据和制定训练目标的方法。我们将在后续章节中更详细地探讨这些方面。在这里,我们总结了各种检索器模型的优点和缺点。现成的检索器易于使用,无需进行下游任务的微调,通常表现比随机演示更强大。唯一的例外是在常识推理任务中,Zhang等人(2022b)和Ye等人(2023a)发现对于这些任务,随机演示始终比检索方法更好。Cheng等人(2023)还表明,检索到的演示对常识推理和共指解析任务产生了不利影响。在现成的检索器的三个类别中,如BM25等稀疏检索器更具索引效率。这个特性在处理大量演示和有限的硬件内存时特别有价值,使得在这种情况下BM25成为首选。相比之下,基于句子嵌入相似性的方法和基于双编码器的检索系统,这些方法在语言任务上训练,更擅长捕捉更语义上关注的检索结果。就性能而言,Luo等人(2023)在5个任务中比较了BM25和双编码器(GTR),发现这两者的平均性能非常相似(在0.5%的差异范围内),在某些任务中BM25胜过双编码器,反之亦然。在另一项研究中,Ye等人(2023a)观察到了类似的趋势,强调没有单一的检索器在不同任务中始终表现优于其他检索器。Rubin等人(2022)和Li等人(2023)发现,在语义解析任务中,BM25要优于SBERT,而Li等人(2023)发现,在情感分析任务中,SBERT要优于BM25。然而,经过微调的检索器在性能上表现出优势,相对于现成的检索器。经过微调的检索器的主要缺点在于获取训练数据的成本较高。
此外,采用任务特定的检索器的常见做法使系统变得复杂,并限制了其通用性。Li等人(2023)提出了训练通用检索器的概念,该检索器在大多数任务上表现优于任务特定的演示检索器(例如EPR(Rubin等人,2022))。
结论
本调查集中讨论了使用检索到的示例进行少样本上下文学习(ICL)的方法,这是检索增强生成(RAG)的关键方面。我们概述了各种检索策略、多样化的检索模型、检索池、训练演示检索器的技术以及应用。基于对当前趋势的全面了解,我们提出了增强这一方法的有效性和功能性的一些有前途的未来发展方向。

