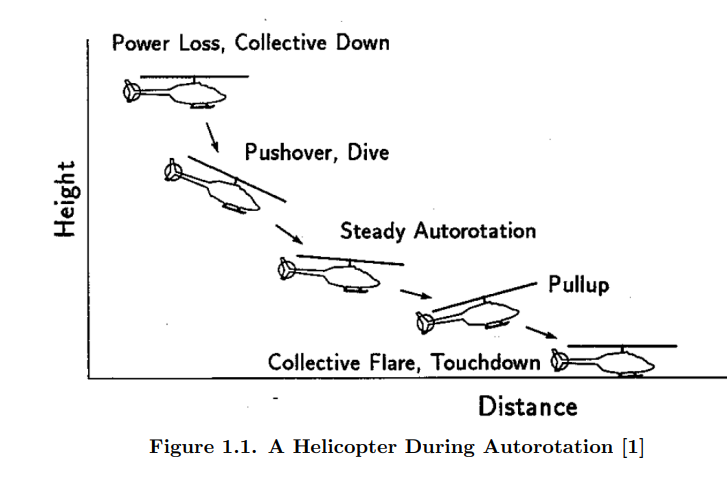
在美空军之前开展的工作中,成功实施了 GPOPS-II(一种伪谱最优控制求解器),用于在完全功率损失情况下寻找直升机的最优控制和最优轨迹。GPOPS-II 被认为是生成飞行前数据(如 HV 图,又称 “死亡曲线”)的有用工具,尽管由于程序的功能,解决方案仅以时间历史形式提供,无法生成明确的控制法则(如 u=f(x,t))。此外,GPOPS-II 不适用于实时应急,因为计算时间大约为几分钟。理想情况下,在实时紧急情况下的应用包括将算法解决方案映射到驾驶舱内的可视化辅助设备上,可能会显示在 HUD 或 MFD 上。由于上述局限性,最近开展了一项研究,利用深度强化学习算法为这种情况下的直升机生成最佳控制法则,如果证明成功,最终将允许设计各种驾驶舱驾驶辅助工具。据预测,此类驾驶辅助系统可减少在执行紧急无动力着陆时飞行员的工作量,并从总体上提高在此类事件中安全着陆的概率。提出的课题讨论了如何使用近端策略优化(PPO)算法,为直升机在完全失去动力紧急着陆的情况下找到最佳控制策略。任务包括使用 PPO 算法设计和训练一个行动者神经网络和一个批判者神经网络,同时开发直升机的动态运动方程,定义奖励结构并调整相关的超参数。事实证明,PPO 算法总体上是可行的,它可以在各种初始飞行条件下,使简单建模的直升机安全着陆。
本章介绍了自动引航和HV图,并简要讨论了减少工作量的可视化引航辅助工具。此外,本章还介绍了本研究的主要目标。第 2 章介绍了之前使用伪光谱优化方法和 DRL 方法估算直升机在总功率损失情况下最佳控制路径的研究背景。此外,第 2 章还介绍了 PPO 算法的基础,从经典的强化学习(RL)和马尔可夫决策过程到策略梯度算法的推导。第 3 章推导了直升机模型的动态运动方程,并解释了调整和训练 PPO 智能体的方法。第 4 章介绍了 PPO 算法在直升机模型环境下的超参数选择阶段、训练阶段和测试阶段的结果。最后,第 5 章阐述了本研究的结论和对未来研究的建议。