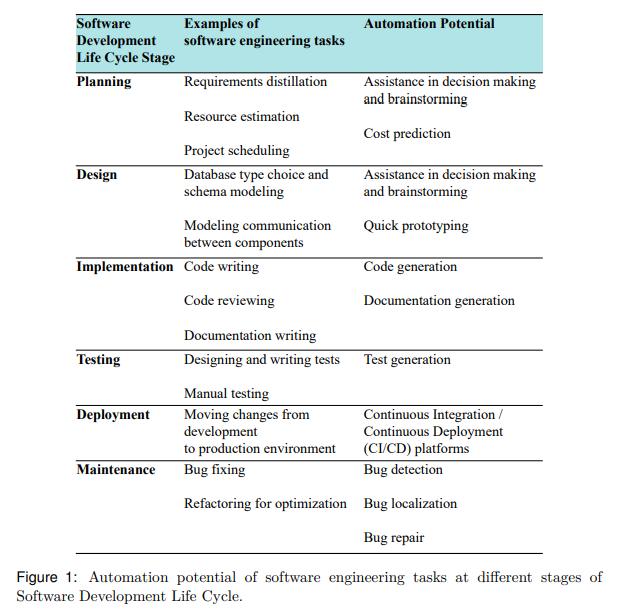
软件质量标准要求严苛,因其驱动全球众多系统且需确保安全稳健。软件开发意味着需遵循高标准并适应需求与依赖项的变更。所幸软件工程的繁重任务可实现部分自动化,尤其随着生成式人工智能的最新进展。本论文探索自动化代码维护方法,聚焦"基于大型语言模型的软件工程"(LLM4SE),通过模型内部优化与模型间通信推进转换器模型在检测修复软件缺陷中的应用。此处"缺陷"涵盖执行故障与源代码错误,"源代码"指软件产品的原始代码或程序。核心贡献包括:开发轻量级转换器变体用于代码分类;提出两套自动化程序修复框架;反思LLM4SE研究的可持续性与透明度。研究首先开发编码器层组合方案(编码器属转换器类型)用于代码分类。实验发现轻量剪枝版CodeBERT变体微调耗时减少至1/3.3(微调指在领域数据上训练模型),且性能更优——缺陷检测准确率最高提升2个百分点(满分100),优于全尺寸模型常规用法。该结果推动语言模型在软件工程中的能效应用,证明全尺寸模型的"通用方案"对代码正确性分类等简单任务并非必需。
除错误检测外,本文呢聚焦生成代码与人写代码的缺陷修复。所提SEIDR框架包含"合成-执行-指导-调试-排序"模块,实现生成代码的实时修复,彰显LLM在"生成-修复"循环中的价值。此循环中,LLM通过代码执行、失败测试用例及错误日志获取反馈,最终生成全功能代码。采用Codex(基于代码训练的GPT-3)的SEIDR在程序合成基准测试中解决25项任务的19项,优于前沿遗传编程算法。论文还提出新型"循环翻译"(RTT)修复管线。与SEIDR不同,RTT专为修复已存在缺陷的生成/人写代码设计,通过将缺陷代码转译至其他编程语言/自然语言再回译至原语言实现修复。其理论依据是:转译过程可能因"均值回归"现象消除缺陷("均值"指模型训练数据中普遍存在的无缺陷代码)。实验证明:LLM驱动的RTT管线在多个基准测试中解决46个微调模型未能修复的独特缺陷。此能力使RTT成为多智能体程序修复体系的候选方案——各智能体以不同方法协同维护无缺陷代码。论文还综述LLM4SE文献,反思能效与模型复用可能性:仅27%的论文共享代码、模型及估算训练能耗所需完整细节,凸显遵循开放可复现研究准则的重要性。鉴于LLM存在随机性等局限,本研究提供实证结果而非理论保证,并讨论过度使用LLM的风险(如工具依赖、生成代码漏检、基准测试数据污染等)。整体而言,本研究推动LLM适配软件工程任务,为多智能体系统与多模态模型的自动化代码修复指明方向。
论文结构
第二章从软件开发生命周期视角综述软件工程自动化背景;第三章概述自然语言处理及LLM架构进展;第四章总结LLM4SE方法、进展与挑战;第五章阐明研究范围与机遇(5.3节详述研究问题、挑战及对应出版物关联,5.4节汇总出版物与问题解答);第六章讨论有效性威胁、局限、科研与产业影响及未来工作;第七章总结核心结论。为提升可读性,各背景小节均附框内摘要,研究问题答案与关键发现亦作相同标注。