

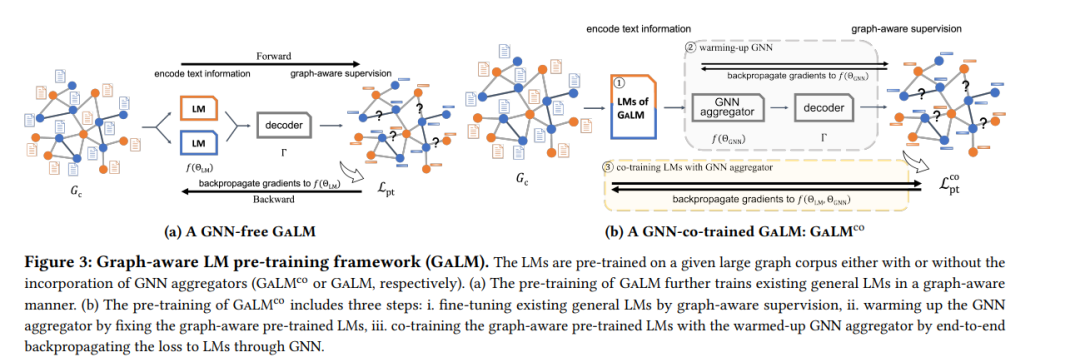
大规模文本语料库上的模型预训练已经被证明在NLP领域的各种下游应用中非常有效。在图挖掘领域,也可以类比预训练图模型在大规模图上,以期望从中获益于下游图应用,这也被一些最近的研究所探索。然而,现有的研究从未研究过在具有丰富文本信息的大型异构图(也就是大型图谱语料库)上预训练文本加图模型,然后在具有不同图模式的不同相关下游应用上对模型进行微调。为了解决这个问题,我们提出了一个在大型图谱语料库上进行图感知语言模型预训练(GaLM)的框架,该框架结合了大型语言模型和图神经网络,并在下游应用上提供了各种微调方法。我们在亚马逊的真实内部数据集和大型公共数据集上进行了广泛的实验。全面的实证结果和深入的分析证明了我们提出的方法的有效性,以及我们从中学到的经验。
成为VIP会员查看完整内容
相关内容
Arxiv
20+阅读 · 2023年3月21日
Arxiv
13+阅读 · 2019年5月22日

相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2023年3月21日
Arxiv
13+阅读 · 2019年5月22日