
题目:
Communication-Efficient Distributed Deep Learning: A Comprehensive Survey
简介:
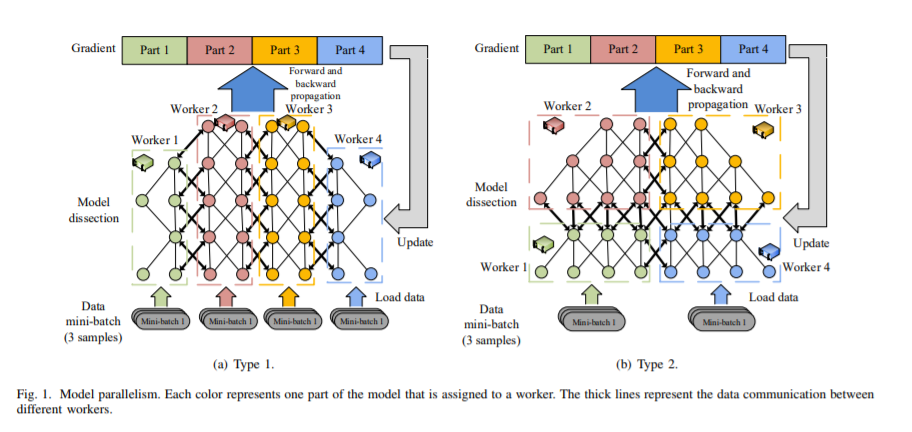
随着深度模型和数据集规模的增加,通过利用多个计算设备(例如GPU / TPU)来减少总体训练时间,分布式深度学习变得非常普遍。但是,计算设备之间的数据通信可能是限制系统可伸缩性的潜在瓶颈。近年来,如何解决分布式深度学习中的交流问题成为研究的热点。在本文中,我们对系统级和算法级优化中的通信有效的分布式训练算法进行了全面的概述。在系统级,我们对系统的设计和实现进行神秘化处理以降低通信成本。在算法级别,我们将不同的算法与理论收敛范围和通信复杂性进行比较。具体来说,我们首先提出数据并行分布式训练算法的分类法,它包含四个主要方面:通信同步,系统架构,压缩技术以及通信和计算的并行性。然后,我们讨论解决四个维度问题的研究,以比较通信成本。我们进一步比较了不同算法的收敛速度,这使我们能够知道算法在迭代方面可以收敛到解决方案的速度。根据系统级通信成本分析和理论收敛速度的比较,我们为读者提供了在特定的分布式环境下哪种算法更有效的方法,并推断出可能的方向以进行进一步的优化。
成为VIP会员查看完整内容

相关内容

专知会员服务
80+阅读 · 2020年3月5日


相关VIP内容
专知会员服务
80+阅读 · 2020年3月5日
相关资讯
相关论文