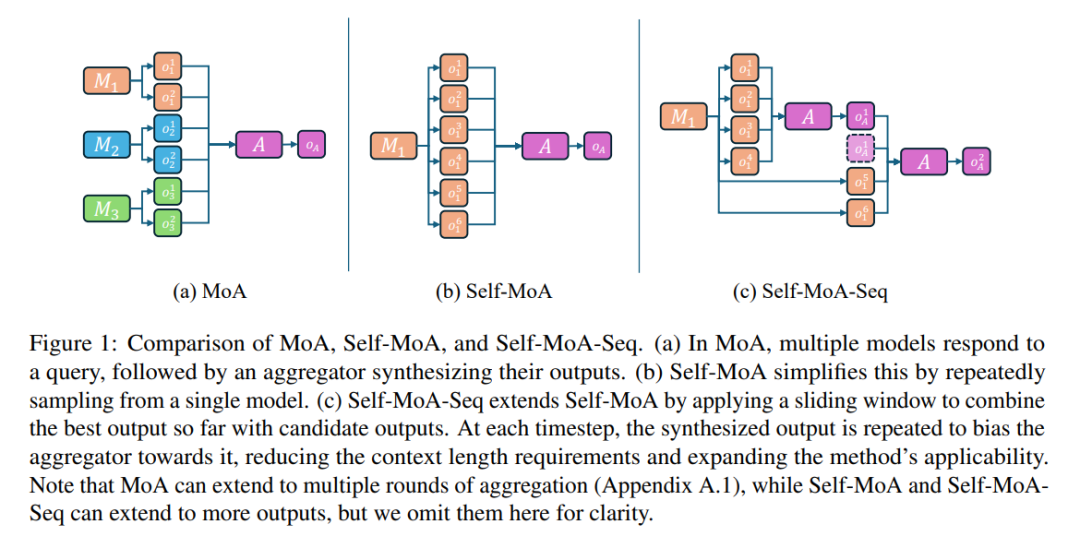
**从不同来源聚合输出是提升性能的直接而有效的方法。代理混合模型(Mixture-of-Agents,MoA)是其中一种流行的集成方法,通过聚合来自多个不同大型语言模型(Large Language Models,LLMs)的输出。本文在语言模型的背景下提出了一个问题:混合不同的大型语言模型真的有益吗?我们提出了Self-MoA——一种仅聚合单一表现最佳大型语言模型输出的集成方法。我们的广泛实验结果显示,令人惊讶的是,Self-MoA在大量场景下超过了标准的MoA方法:在AlpacaEval 2.0基准测试中,Self-MoA相比MoA提高了6.6%,在包括MMLU、CRUX和MATH等多个基准测试中,平均提升了3.8%。将Self-MoA应用于AlpacaEval 2.0中的顶尖模型之一,直接实现了该排行榜上的新最优成绩。**为了理解Self-MoA的有效性,我们系统地研究了在各种MoA设置下,输出的多样性与质量之间的权衡。我们确认MoA的性能对质量非常敏感,混合不同的LLM往往会降低模型的平均质量。为了补充研究,我们还识别出了混合不同LLM可能有益的场景。本文进一步介绍了一种Self-MoA的序列版本,它能够在多轮中动态聚合大量LLM输出,并且与一次性聚合所有输出一样有效。
https://arxiv.org/abs/2502.00674
1. 引言
大型语言模型(LLMs)在提升不同领域的性能方面取得了显著进展,典型的例子包括GPT [Achiam et al., 2023]、Gemini [Team et al., 2023] 和Claude [Anthropic, 2023]。大量的努力已经集中在增加模型的规模和训练数据量上,以提升模型的能力。然而,在训练时进行规模化存在高昂的成本,而在推理过程中进行计算规模化仍然是一个未被充分探索的领域。 利用测试时计算的直接方式之一是集成(Ensembling),其目标是将多个LLM的输出结合起来 [Wang et al., 2024a, Lin et al., 2024, Jiang et al., 2023a, Wang et al., 2024a]。在各种集成方法中,代理混合模型(Mixture-of-Agents,MoA)[Wang et al., 2024a] 引起了广泛关注,在诸如指令跟随 [Wang et al., 2024a]、摘要生成、数据抽取 [OpenPipe, 2024] 和现实世界代码问题解决 [Zhang et al., 2024b] 等具有挑战性的任务中取得了卓越的表现。具体来说,MoA首先查询多个LLM(提议者)生成响应,然后使用另一个LLM(聚合器)对这些响应进行综合和总结,从而生成高质量的最终响应。 以往的研究强调了提议者模型的多样性对于优化MoA性能的重要性,主要集中在如何集成一组多样化的独立模型。我们认为跨模型多样性是指不同模型之间的变化。然而,追求跨模型多样性可能会无意中包含低质量的模型,从而导致质量和多样性之间的权衡。尽管以往的研究主要集中于实现较高的跨模型多样性 [Wang et al., 2024a, Zhang et al., 2024b],我们从整体的角度看待模型多样性,提出了“模型内多样性”(in-model diversity)这一概念,即同一个模型生成的多个响应之间的变化。模型内多样性使我们能够聚合同一模型的多个输出。直观来看,利用表现最好的单一模型的输出,可以更有效地在质量和多样性之间做出权衡,从而创建一个高质量的提议者混合。因此,我们提出了Self-MoA,如图1b所示,它使用与MoA相同的提示模板,但聚合的是从同一模型中反复采样的输出,而不是来自不同模型的输出。为了区分,我们用Mixed-MoA来指代在必要时组合不同独立模型的MoA配置。令人惊讶的是,我们发现,Mixed-MoA通常表现不如Self-MoA,尤其是在提议者之间存在显著质量差异的情况下。具体来说,我们重新进行了Wang et al. [2024a]的MoA实验设置,使用六个开源指令微调模型。与Mixed-MoA聚合所有六个模型的做法相比,Self-MoA在最强模型上的表现,在AlpacaEval 2.0基准测试中实现了比混合模型高出6.6分的提升,展示了在这种情况下,模型内多样性更加有效。此外,Self-MoA在AlpacaEval 2.0上使用表现最好的两个模型,始终取得2到3分的提升,并在排行榜上排名非对抗性方法中的首位,进一步验证了Self-MoA在此任务中的有效性。为了探索MoA中模型多样性的极限,我们将实验扩展到一个包含三个专业化模型的设置,每个模型在特定任务中表现突出。具体来说,我们使用Qwen2-7B-Instruct [Bai et al., 2023] 处理常识问答(MMLU-redux [Gema et al., 2024]),Qwen2-Math-7B-Instruct [Bai et al., 2023] 处理数学任务(MATH [Hendrycks et al., 2020]),以及DeepSeek-Coder-V2-Lite-Instruct [Zhu et al., 2024] 处理编码任务(CRUX [Gu et al., 2024])。我们将Self-MoA与一系列Mixed-MoA策略进行比较,评估13种不同模型组合在三个任务中的平均表现。我们的发现表明,使用任务特定的模型作为Self-MoA的提议者,能够显著超过最佳的Mixed-MoA。此外,即使在一个为Mixed-MoA量身定制的混合任务中,每个单独模型在特定子任务中表现优秀,只有两种Mixed-MoA策略在自MoA上略微超过了0.17%和0.35%。为了更好地理解Self-MoA的有效性,我们进行了全面的实验,探索了MoA中质量与多样性之间的权衡,涉及超过200个实验。我们使用Vendi Score [Dan Friedman 和 Dieng, 2023] 来评估提议者输出的多样性,而提议者的平均性能则作为质量的衡量标准。在第四节中,我们确认了MoA性能与质量和多样性之间的正相关关系。此外,我们清晰地展示了在质量和多样性之间的可实现帕累托前沿的权衡。值得注意的是,我们发现MoA对质量变化非常敏感,通常在质量较高而多样性较低的区域表现最优。这一发现自然解释了Self-MoA的有效性,因为它利用最强模型作为提议者,确保了高质量的输出。最后,我们在增加计算预算的情况下评估了Self-MoA的性能。随着输出数量的增加,Self-MoA的可扩展性受限于聚合器的上下文长度。为了解决这一问题,我们提出了Self-MoA-Seq(图1c),它是一种顺序版本,使用滑动窗口处理样本,使其能够处理任意数量的模型输出。我们的实验结果表明,Self-MoA-Seq至少与Self-MoA一样有效,能够在不妥协最终性能的情况下实现LLM的可扩展集成。总体而言,我们的贡献有三方面:
- 我们介绍了Self-MoA,它通过综合同一模型的多个输出来利用模型内多样性。令人惊讶的是,与强调跨模型多样性的现有Mixed-MoA方法相比,Self-MoA在广泛的基准测试中表现出了优越的性能。
- 通过系统的实验和统计分析,我们揭示了提议者之间在多样性和质量方面的核心权衡,强调了MoA对提议者质量的高度敏感性。这一发现也解释了Self-MoA的成功,它通过利用表现最好的模型的输出,确保了整体质量的提升。
- 我们将Self-MoA扩展为其顺序版本Self-MoA-Seq,它通过逐步集成少量输出来实现。Self-MoA-Seq解锁了受上下文长度限制的LLM,并使推理期间的计算能够扩展。