

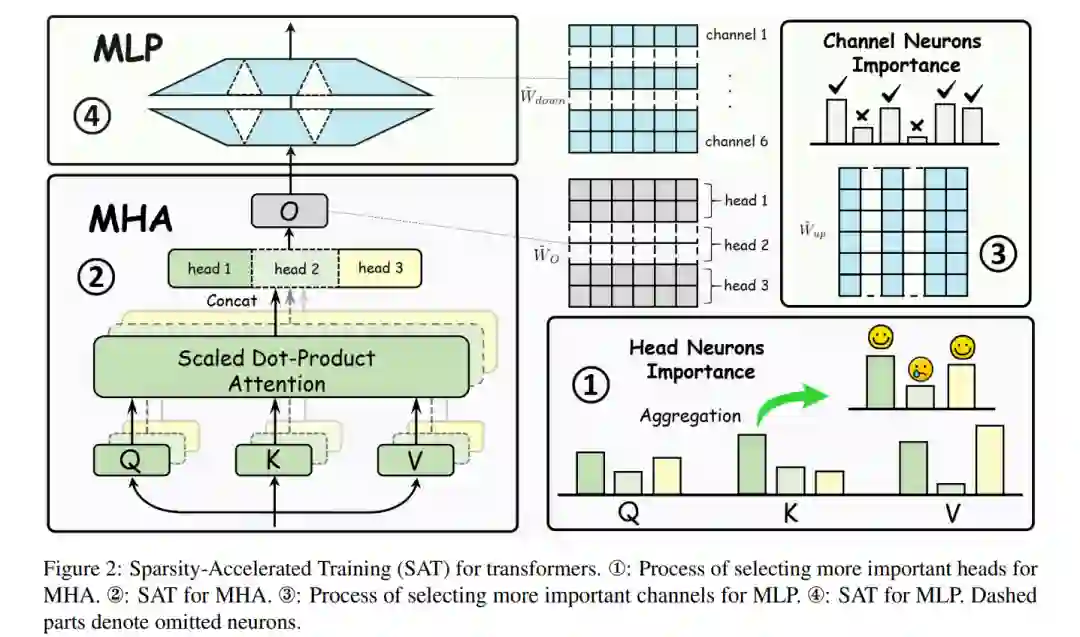
大型语言模型(llm)已经证明了对各种自然语言处理(NLP)任务的熟练程度,但通常需要额外的训练,例如持续的预训练和监督微调。然而,与此相关的成本仍然很高,主要是由于它们的参数数量很大。本文建议在预训练llm中利用稀疏性来加快这一训练过程。通过观察前向迭代中激活神经元的稀疏性,我们通过排除非活动神经元来确定计算加速的潜力。我们通过扩展现有神经元重要性评估指标和引入阶梯遗漏率调度器来解决相关挑战。在Llama-2上的实验表明,稀疏加速训练(SAT)取得了与标准训练相当或更好的性能,同时显著加快了过程。具体来说,SAT在持续预训练中实现了45%的吞吐量提高,在实际的监督微调中节省了38%的训练时间。它为额外的LLM培训提供了一个简单、硬件无关且易于部署的框架。我们的代码可在https://github.com/OpenDFM/SAT上获得。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
225+阅读 · 2023年4月7日