传统的药物研发是一个耗时耗力的过程。据统计,一款新药从研发到上市平均需要花费至少十年的时间,成功开发一款新药平均需要花费数十亿美元。在早期研发过程中化学家们可能会筛选上千万的化合物,但最终仅有10%的新药能被批准进入临床研究,更小比例的药物分子获批上市。因此,临床阶段前的分子设计是药物发现过程中的关键问题。 过去几年人工智能(AI)技术已成功应用于药物发现中,特别是有大量工作致力于开发深度生成模型来探索和挖掘广阔的药物分子空间,以加速药物设计过程并降低成本。相比于传统要求化学家从广阔的化学空间中通过实验来筛选和验证候选分子的方法,深度生成模型能以一种既经济又高效的方式自动获得新颖且具有理想性质的分子。 最近,由湖南大学曾湘祥教授、康奈尔大学王飞教授、西北大学Luo yuan教授、IBM TJ Watson研究中心Seung-gu Kang教授及Wendy Cornell教授、Mila唐建教授、劳伦斯利弗莫尔国家实验室Felice C. Lightstone教授、奥斯陆大学Evandro F. Fang教授、特拉维夫大学Ruth Nussinov教授等知名学者共同完成的一篇发表在**Cell Reports Medicine****(IF: 16.988)**的文章“Deep Generative Molecular Design Reshapes Drug Discovery”,系统介绍了深度生成模型的基础知识及其在药物设计中的应用,并讨论了当前该领域发展的局限及未来的发展方向。

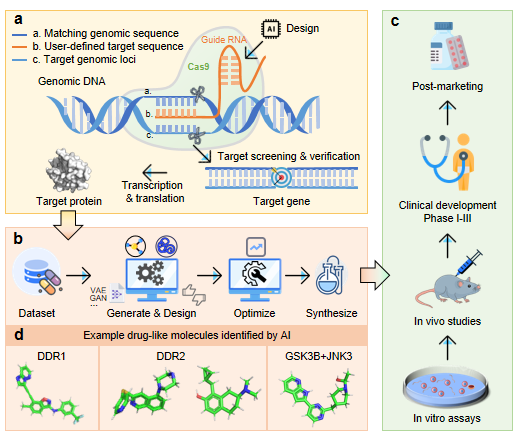
图1. 药物发现流程总览图。 a.人工智能辅助靶标选择和验证;b.分子设计,先导化合物优化和化学合成;c.生物评估(体外和体内),临床开发和上市后监测;d.由人工智能设计进入临床阶段的几个成功分子实例。
深度生成工具的基础
1. 用于药物发现的大型生物医学数据集首先简要概述几种常用的化学生物信息学数据库,它们提供标记与未标记的数据来训练和测试药物发现社区的深度生成模型。
制药公司内部专有数据库——包含两至三百万的化合物以及过去药物发现中的相关数据。
ZINC数据库——包含近20亿中可购买、用于计算机筛选的“类药物”化合物。
ChEMBL数据库——包含近150万的生物活性分子,且每个分子都至少有一个实验生物活性测量结果,它们可用于训练模型来生成具有特定性质的分子。
GDB-17数据库——包含多达17个碳、氮、氧、硫和卤素重原子的大多数有机分子(1664亿)。
Enamine数据库**(https://enamine.net)和****realdb数据库**——数十亿个通过化学信息学方法的可合成化合物。 除了小分子资源,一些大分子数据库为大分子设计中的生成模型训练提供了丰富的数据,例如Protein Data Bank(PDB)。 2. 分子表示分子的表示形式对于生成模型至关重要。目前有三种类型的表示形式(图2):(a)基于一维序列的表示;(b)基于图的表示;(c)基于三维结构的表示。 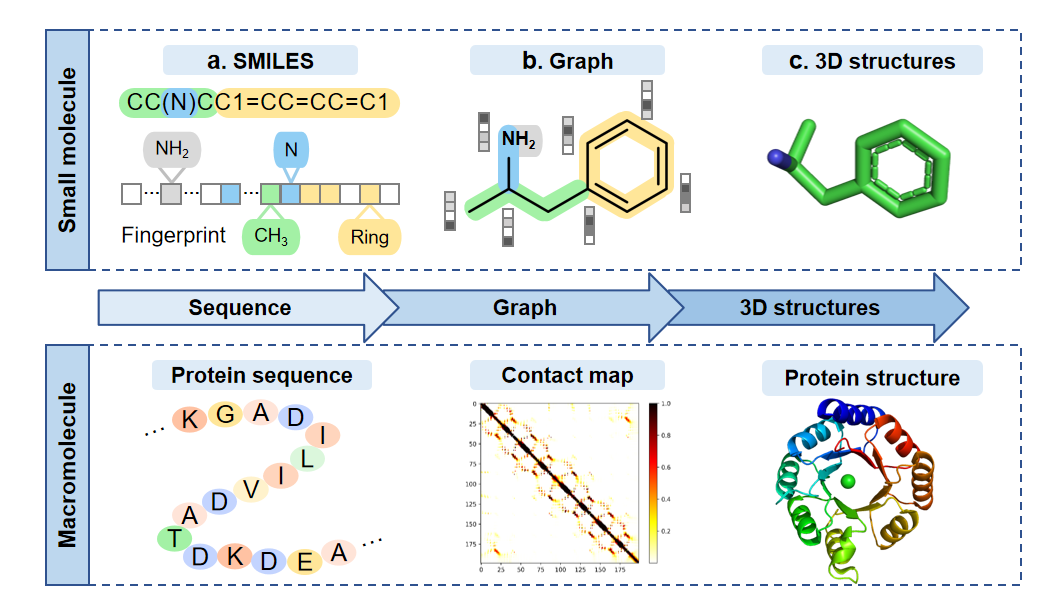
****3. 递归神经网络(RNN)****RNN非常适合对时序型数据建模,并通过以下方式生成SMILES(即“c1cc…c1”)。RNN接收第一个字符“c”,并为可能的下一个字符分配不同的概率:其中字符“1”被高概率接收,作为下一个字符。随后“1”作为当前时刻的起始字符预测下一个字符。这个过程循环往复,直到遇到结束标志' \n '。

图3. RNN生成过程图
****4. 变分自编码器(VAE)****编码器将分子映射至从高斯分布中采样的低维潜在向量,再由解码器将潜在向量映射至输入的分子,其中潜在向量设定为遵从概率分布(通常为高斯分布),因此分子被表示为潜在空间上的显式概率分布,而解码器的输出重构出输入分子的概率分布。
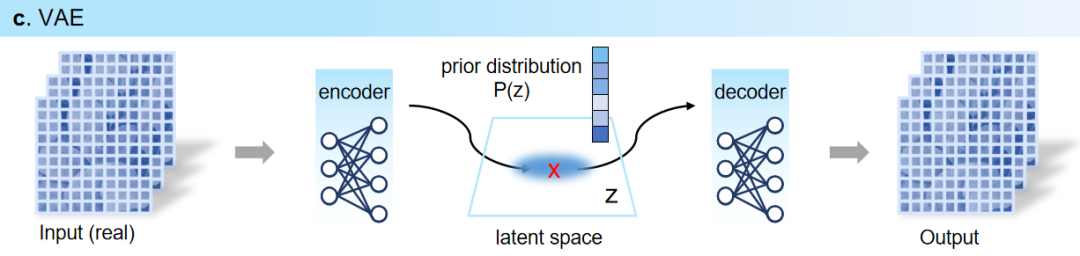
图4. VAE生成过程图
**5. 生成对抗网络(GAN)**GAN不使用明确的概率密度函数,而是提供由生成器和判别器组成的对抗训练框架。判别器训练一个分类模型,旨在最大限度地区分真实数据和生成数据,生成器和判别器在零和博弈中进行对抗训练,直至判别器无法辨别真假,这时生成器生成的分子就达到了“以假乱真”的目的。
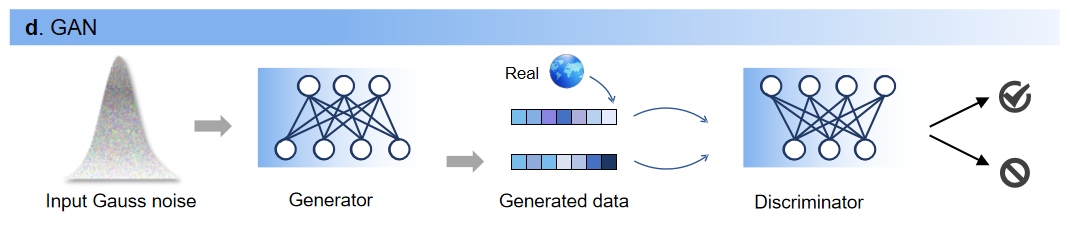
图5. GAN生成过程图
6. 流模型流模型通过利用规范化流解决显式密度估计问题,其中规范化流是原始数据空间和潜在空间之间的可逆确定性转换。由于超参数调整过程复杂,流模型通常会非常耗时。
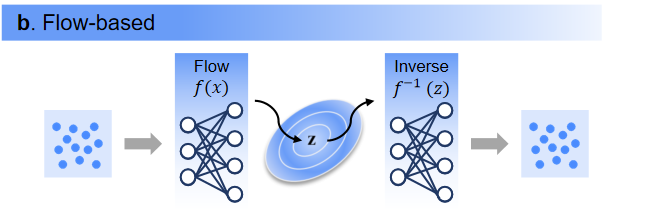
图6. 流模型生成过程图。
****7.强化学习(RL)****RL是一种通过动态决策过程探索化学空间的潜在方法,可作为一种微调目标属性的技术,
它由Agent、Reward和Environment组成,旨在朝用户导向的目标进行优化。Agent选择下一个操作,Reward根据Environment(特定于域的规则)评估操作的质量,并向Agent提供反馈。
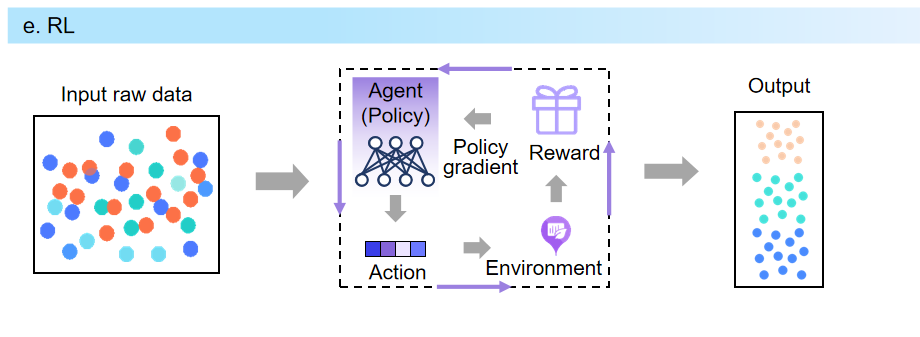
图7 强化学习生成过程图。
小分子药物设计中的应用
像虚拟筛选这类传统方法需要作用在规模很大的化学空间中进行,带来了时间和成本问题。为此,深度生成模型提供了解决方案,它在小分子药物设计中的发展可分为以下几个阶段。 1. 生成有效小分子随着用于小分子从头设计的深度生成模型的出现,起初很多研究关注于如何生成有效的分子,特别是小分子的语法和语义正确。代表工作有SD-VAE,JT-VAE等。 2. 生成具有药物性质的分子随着生成模型的逐渐成熟,分子生成模型不再满足于生成有效的分子,致力于寻找具有特定性质的分子如类药性,生物活性和合成可及性。代表工作有GENTRL,PGFS等。 3. 生成具有多目标类药物性质的分子从头设计的生成模型能够设计具有多种约束的分子,这类分子能够更好地满足药物研发的要求。代表工作有RationaleRL等。
4. 优化生成更好的生物可利用性分子
分子优化的目的是为给定的分子期望的属性,这个过程类似于计算机视觉中的图像到图像的转换(例如,将马变成斑马)或自然语言处理中的风格转换。代表工作有Mol-CycleGAN等。
大分子药物设计中的应用
除了设计小分子外,人工智能还可用于大分子药物设计中,例如设计抗菌肽、治疗蛋白和CRISPR/Cas9系统设计和优化。对于抗菌肽的生成,Das等人用分子动力学信息扩充了VAE的变体,以生成具有广谱效力和低毒性的抗菌肽 。此外,新冠肺炎的治疗中使用过一种蛋白质,它是由一种从头设计策略通过复制人类血管紧张素I转换酶2(hACE2)的蛋白质界面快速准确生产的一类诱饵蛋白质。最近的研究也证明了深度学习算法(如CNN和RNN)在设计和优化CRISPR/Cas9系统方面的有很大作用,如DeepCRISPR,DeepHF等。
问题、观点和未来方向尽管人工智能赋能的药物发现取得很大进展,但问题和挑战依然存在。药物发现中使用的大多数机器学习模型需要大量数据用于训练和验证,尤其是深度学习模型。缺乏足够的质量和健壮的数据共享实践仍然是机器学习模型积极影响药物发现的关键障碍。接下来,文章简要讨论了几个挑战和潜在的未来方向。 1. 可解释生成模型虽然生成模型和其他基于深度学习的方法具有巨大潜力,但它们对于使用者来说是一个“黑匣子”,因此提高模型的可解释性至关重要。一种方式为扰动模型中的输入或参数,并观察结果如何变化。例如通过扰动解纠缠分解潜在空间得到的独立因素来观测对应的每个属性的变化,这样就可以生成具有所需特性的分子。另一种解决方法是设计模型使其显示更多的语义信息,然后解释结果来得到因果关系。分子结构和药物性质之间关系的推理可以指导分子生成之后因果图的构建,模型也可以变得透明。 2. 小样本生成模型当前AI技术依赖于从大量数据中学习,但由于数据隐私、伦理或罕见疾病等多方原因,可获得的数据往往在数量上并不平衡。小样本学习的相关研究为缓解这类问题提供了参考。例如可以通过数据增强的方式直接扩充样本数量。此外,迁移学习旨在将一个域上学到的知识转移到与源域相关的目标域,以解决目标域的数据稀缺性,这种方法可以很好地解决肽或蛋白质设计中特定靶点训练数据不足的问题。 3.多模态生成模型多种模态的数据可以为深度生成模型提供多种互补的信息,这种模型具有更显著的优势。因此,如何充分利用多样性和异质性的生物数据是一个值得探讨的问题。一种方案是“模态对齐”,即将结构模态与其他模态连接起来,最后在中间空间对齐所有模态。另一种是“模态融合”,它在前一种的基础上去掉中间模态转换器,所有模态都直接映射到一个共同的潜在空间中,并用一种通用的混合表示数据。
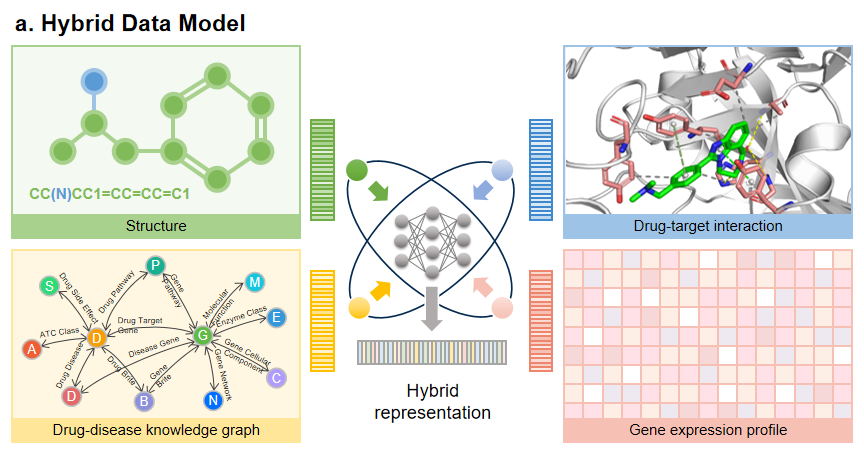
图8. 混合数据模型。上述方法建立在各模态数据平衡情况下,但现实中往往我们需要考虑补全缺失的模态。一种可能的方法是通过涵盖生物活性与分子的药代动力学和药效学属性的模态间的联系构建合成的模态。
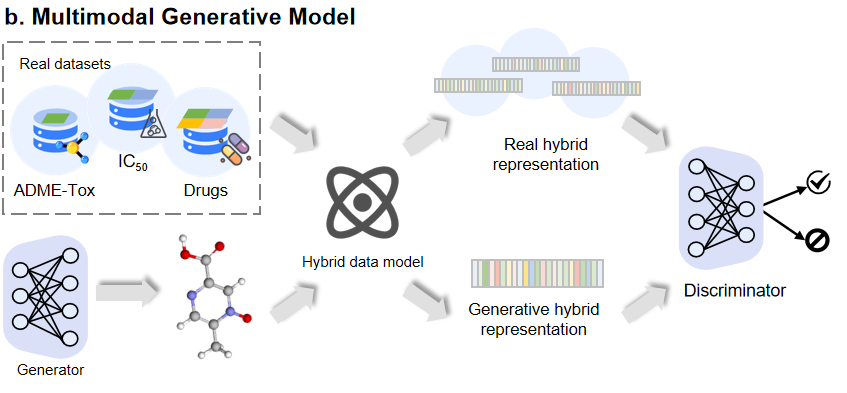
图9. 多模态生成模型。
4. 从数据消费者到数据生产者的生成模型除深度学习算法的出现和GPU的高性能计算的进步之外,前所未有的数据提供量也对于推动数据驱动的药物发现至关重要。但仅凭高质量数据的数量并不能保证在药物发现中提供可操作决策。另一个问题是尽管认识到热力学和动力学特性的重要性,但在药物设计的深度学习模型中,热力学和动力学性质还远未做到常规应用。目前有一种采用基于VAE的生成网络来学习低维非线性嵌入的方法,它通过重构时滞构象的非线性嵌入,揭示了随即蛋白质运动的缓慢动力学。还有一种是使用修改的VAE,通过最大化预测信息瓶颈框架优化的加权反应坐标,有效地知道偏差模拟,来捕获段轨迹中的罕见事件以及计算自由能和运动学。 生成网络与植根于物理学的分子模拟相结合,不仅可以提供有意义的见解,而且还可以为药物发现(包括COVID-19)生成统计上可靠的蛋白质动力学数据提供宝贵的框架。虽然目前的药物发现主要致力于小分子设计,但如果蛋白质构象动力学数据变得更加可行,药物设计将朝着提高安全性和有效性的方向发展。
总结与展望药物发现平台日益工业化,AI在各种疾病防治方面(如新冠肺炎等)的发展也鼓励我们迎接医疗应用中进一步优化和验证AI方法的挑战。增加企业架构和基础设施,是行业、学术界和政府药物发现数据战略的优先事项。此外,强大的数据管理实践能够实现互操作性和遵守标准,强烈推荐三条规则:一、数据管理人员必须确保数据所有权(为数据共享模型奠定基础)是可操作的,并考虑到数据获取、使用和分发实践。二、规定具有代表性的数据(包括不同的化学和目标覆盖范围)在确保没有数据偏差的情况下,再把深度学习模型覆盖到实际应用。三、大数据的数量、多样性、速度和准确性需得到自动化且严格的数据协调和验证。总的来说,快速发展的深度生成分子设计为药物发现带来了新的动力,但依然需要研究人员进一步深入研究,例如不可访问性、可解释性等等。迫切需要在现实的药物发现环境中进一步开发和评估智能生成模型,以便发挥其全部潜力。在这种驱动下,智能生成模型范式将有潜力从理论研究转变为治疗学的实际生成,并为化学家和化学建模人员的日常工作提供便利。 ·END ·