1、大模型技术发展历程
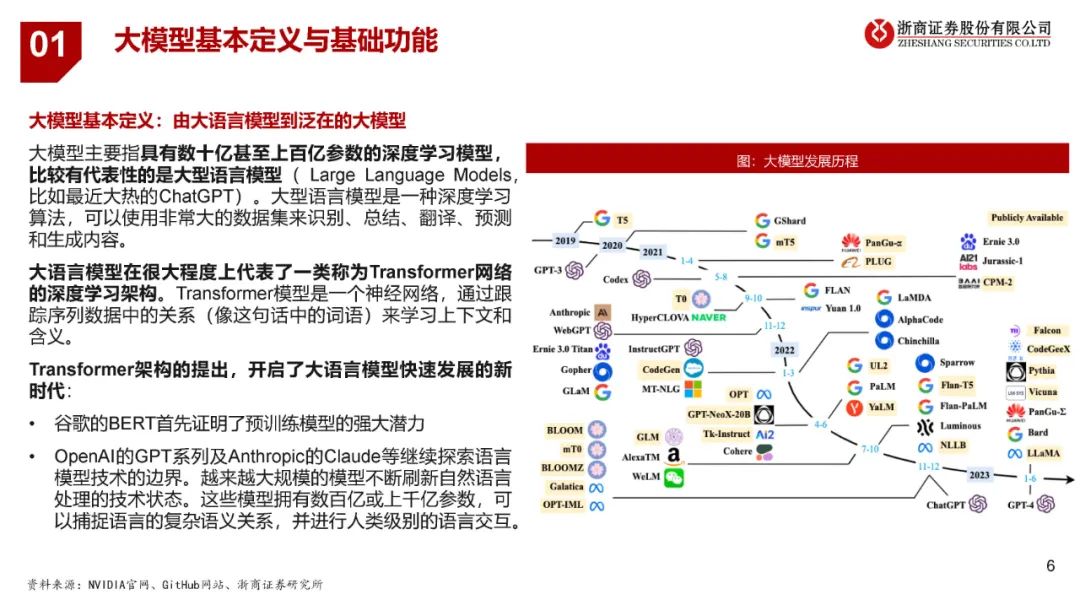
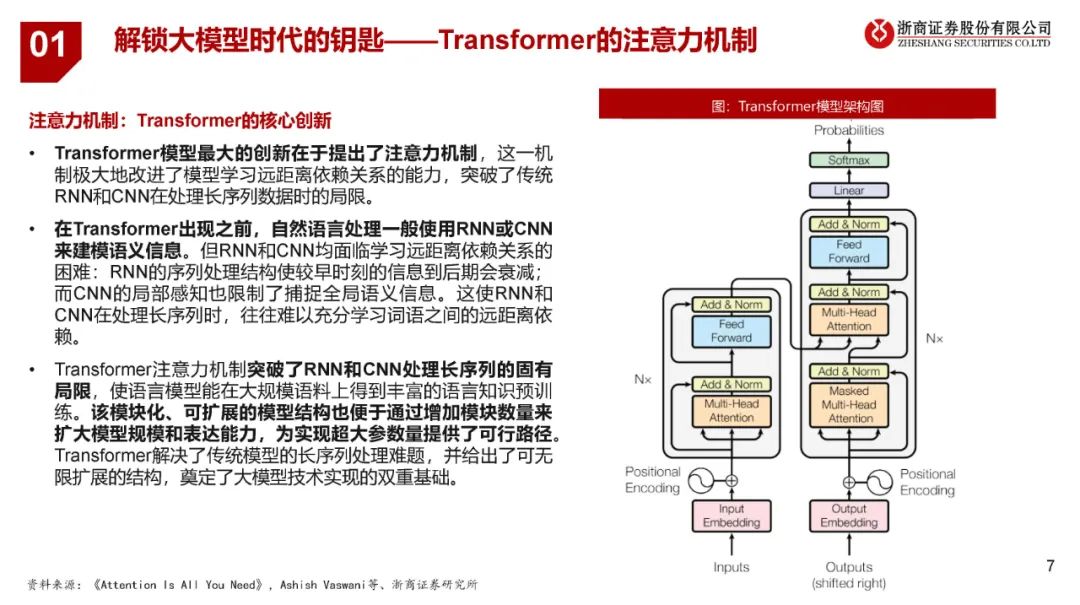
大模型泛指具有数十亿甚至上百亿参数的深度学习模型,而大语言模型是大模型的一个典型分支(以ChatGPT为代表)。Transformer架构的提出引入了注意力机制,突破了RNN和CNN处理长序列的固有局限,使语言模型能在大规模语料上得到丰富的语言知识预训练,一方面,开启了大语言模型快速发展的新时代;另一方面奠定了大模型技术实现的基础,为其他领域模型通过增大参数量提升模型效果提供了参考思路。 复杂性、高维度、多样性和个性化要求使得大型模型在自动驾驶、量化交易、医疗诊断和图像分析、自然语言处理和智能对话任务上更易获得出色的建模能力。 2、自动驾驶模型迭代路径 自动驾驶算法模块可分为感知、决策和规划控制三个环节,其中感知模块为关键的组成部分,经历了多样化的模型迭代:CNN(2011-2016)——RNN+GAN(2016-2018)——BEV(2018-2020)——Transformer+BEV(2020至今)——占用网络(2022至今)。 特斯拉自动驾驶技术路径的演进可视为自动驾驶技术迭代的风向标,呈现全栈自研、出软硬件的协同发展趋势:软件层面从采用Mobileye到自研Transformer+BEV和占用网络;硬件层面从与Mobileye、英伟达合作到自研FSD芯片方案。 3、大模型对自动驾驶行业的赋能与影响 自动驾驶领域的大模型发展相对大语言模型滞后,大约始于2019年,吸取了GPT等模型成功经验。大模型的应用加速模型端的成熟,为L3/L4级别的自动驾驶技术落地提供了更加明确的预期。 可从成本、技术、监管与安全四个层面对于L3及以上级别自动驾驶落地的展望,其中:成本仍有下降空间;技术的发展仍将沿着算法和硬件两条主线并进;法规政策还在逐步完善之中;安全性成为自动驾驶汽车实现商业化落地必不可少的重要因素。 各主机厂自2021年开始加速对L2+自动驾驶的布局,且预计在2024年左右实现L2++(接近L3)或者更高级别的自动驾驶功能的落地,其中政策有望成为主要催化。