【导读】关于《深度学习系统优化》综述论文
深度学习(Deep Learning, DL)模型在视觉、语言、医疗、商业广告、娱乐等许多应用领域都取得了优异的表现。随着DL应用和底层服务硬件的快速发展,都显示出了强大的扩展趋势,即模型扩展和计算扩展,例如,最近的预训练模型具有数千亿参数,内存消耗约TB级,以及提供数百个TFLOPS的最新GPU加速器。随着规模化趋势的出现,DL推理服务系统出现了新的问题和挑战,逐步向大规模深度学习服务系统发展。本综述旨在总结和分类大规模深度学习服务系统出现的挑战和优化机会。通过提供一种新颖的分类方法,总结计算范式,阐述最新的技术进展,我们希望本综述能够揭示新的优化视角,激发大规模深度学习系统优化的新工作。
https://www.zhuanzhi.ai/paper/9ee7ca2cf6457080794f9b6608f09e7a
深度学习(DEEP Learning, DL)模型,如CNN[15,36,44],Transformers[2,7,10,29]和推荐模型[31,41]在许多认知任务,如视觉、语音和语言应用中取得了优异的表现,这在许多领域产生重要的应用,如医学图像分析[38],照片造型[34],机器翻译[40],产品推荐[31]、定制广告[13]、游戏[21]等。这种广泛的DL应用带来了巨大的市场价值,也带来了大量的DL服务流量。例如,FB有18.2亿的日活跃用户[11]。广告推荐查询的数量可以达到每秒10M查询。消费者生成数据的巨大增长和DL服务的使用也推动了对以人工智能为中心的数据中心(如亚马逊AWS[27]和微软Azure[6])的需求,以及对GPU等强大的DL加速器的日益采用。根据[35]的报告,2018年,GPU在全球数据中心加速器市场上以298300万美元的份额占据了85%的主要份额。到2025年,该产品将达到298.19亿美元。
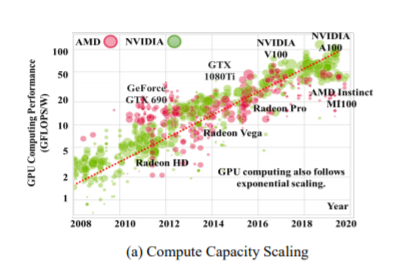
随着市场需求的不断增长,DL应用和底层服务硬件在计算可扩展(例如,增加计算并行性、内存和存储以服务于更大的模型)和模型扩展(例如,更高的结构复杂性、计算工作量、参数大小以获得更好的精度),这大大复杂化了服务系统的管理和优化。一方面,如图1 (a)所示,在计算扩展趋势下,具有大规模计算并行性的GPU已成为近年来数据中心DL计算加速器的主要类型之一,并保持着持续的指数级性能缩放。最近的GPU如NVIDIA Tesla V100提供每秒130拉浮点运算(TFLOPS),和900 GB / s内存带宽, 和这些数字进一步增加到312 TFLOPS和1.6 TB / s内存带宽,可以提供数万DL模型如ResNet50[15]同时提供更高的效率(性能/瓦特)。另一方面,如图1 (b)所示,模型规模已经被证明是获得更好的精度的最重要的因素之一,其有效性在实践中一致显示在所有领域的工业超大模型,如视觉模型BiT [22], NLP模型BERT [7],GPT3[2]和深度学习推荐模型DLRM[31]。例如,最近的超大型模型MT-NLG[29]已经实现了5300亿参数。工业级商用DLRM[31]已达到~ TB模型大小,大大超过了单机存储能力,需要多个设备才能进行协同计算。
在这样的背景下,我们观察到目前的DL系统社区对大规模深度学习系统(LDS)仍然缺乏足够的认识和关注,忽视了出现的挑战和机遇: 传统的DL系统优化通常集中在单模型单机推理设置(即一对一映射)。然而,LDS具有更大的DL模型和更强大的硬件,能够实现更灵活的推理计算,将多实例到单设备、一实例到多设备、甚至多实例到多设备映射变为现实。例如,计算缩放(如GPU、TPU)促使许多研究工作在单个设备上进行多模型推理,例如将一个GPU划分为多个容器化vGPU或多实例GPU (MIG),以获得更好的硬件利用率、更高的服务吞吐量和成本效率。考虑到实际的成本管理(例如,总拥有成本,TCO),服务大量推理查询的数据中心也倾向于迁移到多租户推理服务,例如,将多个推理查询放置在同一设备上,从而产生新的优化目标(例如,每秒服务的总查询,以及来自传统单租户推断的约束(例如,服务水平协议、SLA)。类似地,模型扩展也提出了新的一对多推理场景的要求。目前的超大型模型(如DLRM)在推理过程中需要耗费大量的内存(∼TB不量化),这需要新的协同计算范式,如异构计算或分布式推理。这种协作服务涉及远程进程调用(RPC)和低带宽通信,这带来了与传统的单设备推理截然不同的瓶颈。由于涉及到以上所有场景,现代数据中心面临更复杂的多对多场景,需要专门的推理查询调度,如服务路由器和计算设备管理,以获得更好的服务性能,如延迟、吞吐量和成本等。
在本文中,我们提出了一种新的计算范式分类法,总结了新的优化目标,阐述了新的技术设计视角,并为未来的LDS优化提供了见解。
-
多对多计算范式以DNN实例(I)和计算设备(D)之间的关系为特征,新兴的LDS计算范式除了单实例单设备(SISD)外,还可以分为三个新的类别,即多实例单设备(MISD),单实例多设备(SIMD)和多实例多设备(MIMD),如图2所示。与专注于单模型性能的SISD不同,LDS工作有不同的优化目标,包括推理延迟、服务吞吐量、成本、可扩展性、服务质量等。例如,多租户推理(multi-tenant inference, MISD)的目标是提高服务吞吐量和电力效率,而超大规模模型推理服务的目标是以低成本提高硬件可伸缩性。
-
大规模设计和技术由于推理服务的规模,LDS工作也在算法创新、运行时调度和资源管理方面面临许多优化挑战和机遇。例如,多租户推理优化寻求细粒度的硬件资源分区和作业调度,例如空间/时间共享,以提供QoS保证。由于延迟通信瓶颈,分布式推理需要专门的模型-硬件协同优化,例如高效的模型分片和平衡协作等。
通过对现有工作的总结,我们旨在对出现的挑战、机遇和创新提供一个全面的调研,从而推动LDS运营和优化的新创新。调研的其余部分组织如下:第2节介绍了研究的初步内容,包括我们对LDS的分类,并说明了本次调研的范围。第3节总结了在多实例单设备(MISD)优化方面面临的挑战和最近的工作;第4节总结了单实例多设备(SIMD)优化方面的研究工作;第5节总结了这项工作。