华东师大最新《无数据知识迁移》综述论文,阐述知识蒸馏和无监督领域适应进展
如何在数据不可访问下进行知识迁移是现在关注的一个焦点。华东师大发布最新《无数据知识迁移》综述论文,从知识蒸馏和无监督领域适应的角度对无数据知识迁移的研究进行了全面的综述,值得关注!

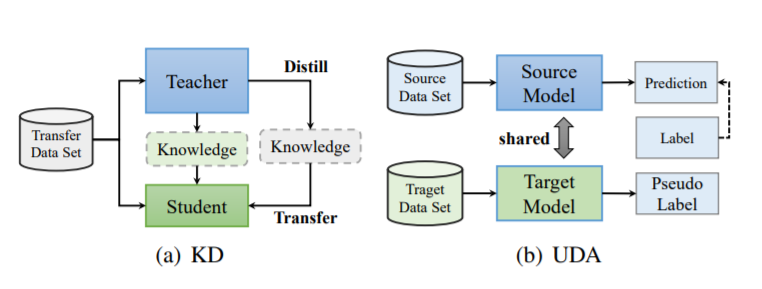
图1. 知识蒸馏(KD)和无监督领域自适应(UDA)综述
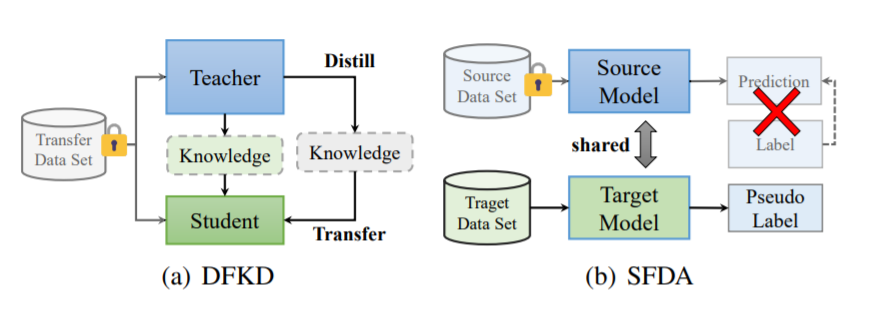
图2. 无数据知识蒸馏(DFKD)和无源领域适应(SFDA)概述
为了解决模型的深度部署问题,对[11]模型进行压缩以降低存储和计算成本,包括剪枝[12]、量化[13]和知识蒸馏[14]。知识蒸馏(Knowledge精馏,KD)[14]是一种流行的模型压缩方法,它将有价值的信息从一个繁琐的教师网络传输到一个紧凑的学生网络中。作为如图1(a)所示的通用师生知识传递框架,它可以与其他模型压缩方法相结合,无需进行任何具体设计[15],[16]。学生网络以训练数据为输入,模拟训练良好的教师网络,与人类的学习方案非常相似。大多数的蒸馏方法都是从教师网络的中间特征图或预测中提取和传递知识。在模型压缩方面,近年来知识蒸馏技术的快速发展对半监督学习[17]、[18]、增量学习[19]、[20]、隐私保护[21]、[22]等产生了巨大的影响。
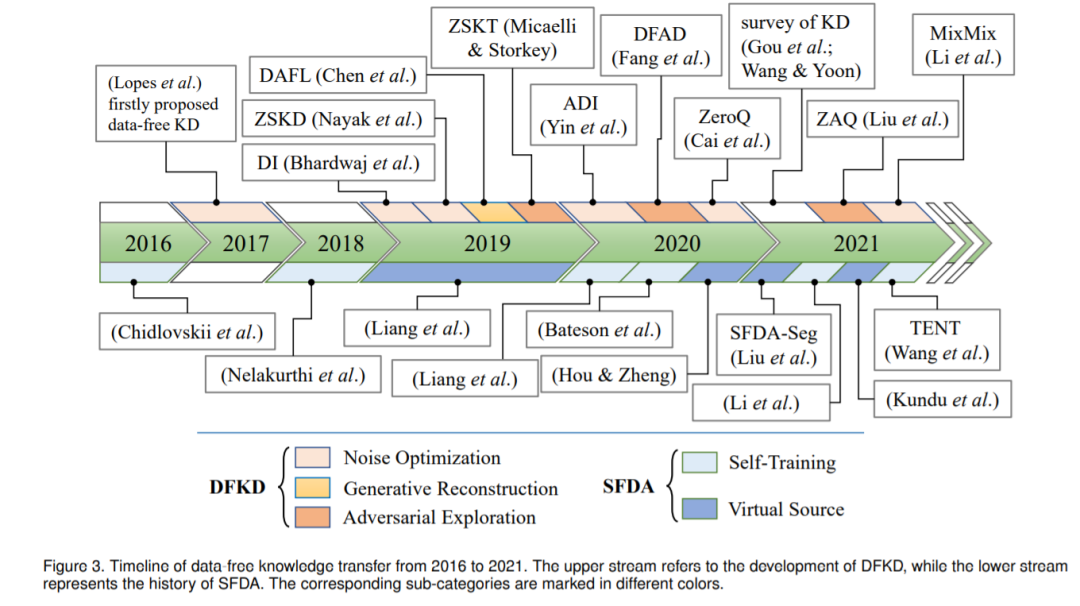
图3. 2016 - 2021年无数据知识迁移工作发展
除了繁琐的网络架构外,大规模数据集的高成本标注也限制了深度学习的应用。例如,手动注释cityscape[23]图像进行语义分割需要大约90分钟。解决这个问题的一种直观的方法是,利用来自相关领域(源领域)的特定知识来研究被考虑的目标领域,这是受到人类研究能力的启发。领域自适应[24]是一种很有前途的迁移学习范式,如图1(b)所示。它旨在将知识从源领域转移到目标领域,避免了劳动密集型的数据注释。根据目标域数据的标注率,可以将域自适应进一步分为无监督域自适应、半监督域自适应和弱监督域自适应。实际上,只有UDA方法完全避免了标注的代价,本文主要考虑的是UDA的设置。
综上所述,知识蒸馏和领域自适应是将有价值的知识从训练良好的深度神经网络迁移到域内或跨域网络的两个主要研究课题。上述方法都是基于数据驱动的,并依赖于原始数据或源数据可访问的前提下进行蒸馏或域适应。然而,由于隐私或版权的原因,在很多实际案例中,原始的训练数据是不可用的。例如,一些知名社区[26]-[29]发布了大量的预训练的深度学习模型[4]、[5]、[7]、[25]。但并不是所有的训练数据都可以用于压缩或使其适应新的领域。此外,医疗或面部数据是公共或第三方机构无法访问的,因为它涉及到患者或用户的隐私。因此,如何利用训练良好的模型(没有训练数据)进行知识迁移成为一个新的研究课题。将其概括为图2所示的“无数据知识迁移(Data-Free Knowledge Transfer, DFKT)”。特别地,该方法还涉及两个主要的研究领域:(1)没有训练数据的知识蒸馏方法称为无数据知识蒸馏(data - free knowledge精馏,DFKD);(2)没有源数据的域适应方法称为无源数据域适应(source -free domain adaptation, SFDA)。DFKD的目标是将训练数据集的原始信息提取并转换为一个紧凑的学生模型,SFDA的目标是通过目标数据查询和探索跨领域的知识。换句话说,DFKD在两个模型之间传递域内知识,而SFDA通过体系结构共享模型传递跨域知识。
近年来,无数据知识转移范式在深度学习的各个领域引起了人们的关注,特别是计算机视觉(包括图像分类[30]-[32]、目标检测[33]-[35]和超分辨率[36])。无数据知识转移的时间轴如图3所示。我们分别描述了DFKD和SFDA在上游和下游的发展。Lopes等人[37]在2016年首次提出了DNN的无数据知识蒸馏。它利用网络激活的摘要来重建其训练集。随着生成式对抗网络的兴起,2019年以来,一些生成式DFKD方法如雨后春笋般涌现,试图合成替代样本进行知识转移。还有一些研究是在[37]的基础上,利用激活状态总结[41]或批归一化统计量(BNS)[32]、[42]从噪声中恢复出原始图像数据。此外,2021年还发布了两个知识蒸馏综述[43]、[44]。SFDA方面,Chidlovskii等人[45]在这方面做了开拓性的工作。2018年至2020年,研究人员主要关注分类[30]、[46]、[47]的无源域自适应。SFDA的语义分割算法[48]、[49]和目标检测算法[33]、[35]从2020年开始研发。毫无疑问,未来将会有更多关于DFKT的研究发表。
虽然传统的数据驱动的知识迁移一直是计算机视觉领域的一个长期挑战,在模型压缩和数据标注的成本降低方面取得了很大的成功,但大多数工作都忽视了数据隐私和商业版权问题,这些问题越来越受到关注。一些研究人员对传统的数据驱动知识蒸馏[43]、[44]、[50]和领域适应[24]、[51]-[53]进行了全面、详细的综述,其中DFKD或SFDA只是冰山一角。然而,随着DFKT的不断成熟,相关的研究也越来越多,这使得研究和产业界都难以跟上新进展的步伐。有鉴于此,我们迫切需要对现有的工作进行调研,这对社区是有益的。在本综述中,我们重点在一个统一的无数据知识迁移框架下,对现有的DFKD和SFDA方法进行分类和分析。我们分别讨论了无数据知识蒸馏和无源领域自适应,并从数据重构算法和知识迁移策略两个方面对它们进行了连接和比较。为了便于理解,我们根据DFKD和SFDA的实现对它们进行了分层分类,如图4所示,并展示了我们调研的组织结构。总之,我们的贡献有三方面:
我们对无数据知识迁移进行了系统的概述,包括分类、定义、两类方法的DFKD和SFDA以及各种应用。据我们所知,这是第一次对DFKT进行调研。
从领域内和跨领域知识迁移的角度,提出了一种新的分类方法,将无数据的知识提炼和无源的领域适应结合起来。
全面总结了每种方法的优势或面临的挑战,并分析了一些有前景的研究方向。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DFKT” 就可以获取《华东师大最新《无数据知识迁移》综述论文,阐述知识蒸馏和无监督领域适应进展》专知下载链接



