南洋理工阿里巴巴等首篇《神经开放信息抽取》综述论文,系统阐述最新神经信息抽取关键技术
最新神经信息抽取综述论文

开放信息抽取(OpenIE)有助于从大型语料库中独立于领域的关系事实发现。该技术非常适合许多开放世界的自然语言理解场景,如自动知识库构建、开放领域问题回答和显式推理。由于深度学习技术的快速发展,许多神经OpenIE架构被提出,并取得了相当大的性能提升。在这项综述中,我们提供了最先进的神经OpenIE模型的广泛概述,它们的关键设计决策,优点和缺点。然后,我们讨论了当前解决方案的局限性和OpenIE问题本身的开放性问题。最后,我们列出了有助于扩大其范围和适用性的最新趋势,为OpenIE的未来研究奠定了良好的方向。据我们所知,这是关于神经OpenIE的第一篇综述。
https://www.zhuanzhi.ai/paper/12abd9cf76dadf37a0ae75527019ba31
OpenIE(开放信息抽取)以n元关系元组的形式提取事实,即(arg1, predicate, arg2,…, argn),从非结构化文本,而不依赖预定义的本体模式[Niklaus等人,2018]。图1显示了从给定句子中提取的示例OpenIE元组。与传统的(或封闭的)IE系统要求预定义关系相比,OpenIE减少了设计复杂的、领域相关的关系模式的人力劳动。因此,它有可能在最少的人工干预下处理异构语料库。通过OpenIE,可以开发Web规模的无约束IE系统,获取大量的知识。然后,收集的知识可以集成并用于广泛的自然语言处理(NLP)应用,如文本蕴积[Berant et al., 2011],总结[Stanovsky et al., 2015],问题回答[Fader et al., 2014; Mausam, 2016]和显性推理[Fu et al., 2019]。

在深度学习之前,传统的OpenIE系统要么基于统计,要么基于规则,并且严重依赖于语法模式的分析[Niklaus et al., 2018]。最近,由于大规模OIE基准(如OIE2016 [Stanovsky and Dagan, 2016], CaRB [Bhardwaj et al., 2019]),以及基于神经的模型在各种NLP任务上的巨大成功(如NER [Li et al.,2022],机器翻译[Yang et al.,2020]),神经OpenIE解决方案变得流行起来。从Stanovsky等人2018年和Cui等人2018年开始,基于神经的方法主导了OpenIE研究,因为它们在多个OpenIE基准上具有良好的提取质量。神经解决方案主要将OpenIE定义为序列标记问题或序列生成问题。基于标记的方法将句子中的标记或span标记为参数或谓词[Stanovsky et al.,2018;Kolluru et al.,2020a;詹和赵,2020]。生成方法使用自回归神经结构从句子输入中生成提取[Cui et al.,2018;Kolluru et al.,2020b]。最近的一些工作侧重于通过引入新的损失来校准神经模型参数[Jiang et al.,2019年],或通过引入新的目标来实现语法上合理和语义上一致的提取[Tang et al.,2020年]。
本文系统地回顾了神经OpenIE系统。现有的OpenIE综述[Niklaus et al., 2018; Glauber and Claro, 2018; Claro et al., 2019]关注传统解决方案,并没有很好地涵盖最近的基于神经的方法。由于范式的改变,OpenIE未来研究机会的潜在途径也需要重新考虑。在这项综述中,我们总结了最近的研究进展,分类现有的神经OpenIE方法,确定剩余的问题,并讨论开放的问题和未来的方向。本文的主要贡献如下: 1) 基于神经OpenIE模型的任务公式,提出了神经OpenIE模型的分类方法。然后我们讨论他们的优点和缺点; 2) 我们对OpenIE的背景和评估方法进行了有益的讨论。我们还提供了当前SOTA方法的详细比较;3) 我们讨论了制约OpenIE发展的三个挑战:评估、注释和应用。在此基础上,我们突出未来的方向: 更开放、更专注、更统一。
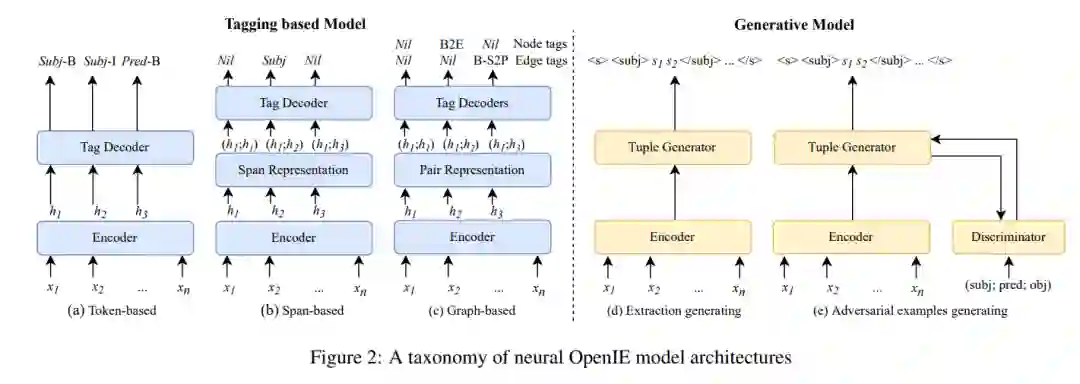
神经OpenIE解决方案
标记模型 Tagging-based Models
基于标记的模型将OpenIE定义为序列标记任务。给定一组标记,其中每个标记表示一个标记或标记跨度的一个角色(例如,参数,谓词),模型学习每个标记或标记跨度以句子为条件的标记的概率分布。然后,OpenIE系统根据预测的标记输出元组。基于标记的OpenIE模型与NLP中用于序列标记任务的其他神经模型(例如,NER NER [Li et al., 2022])共享类似的架构。一个模型通常包含三个模块: 生成标记的分布式表示的嵌入层,生成上下文感知的标记表示的编码器,以及基于标记表示和标记方案预测标记的标记解码器。该嵌入层通常将词嵌入与句法特征嵌入相结合,以更好地捕获句子中的句法信息。最近,预训练语言模型(PLMs)在各种NLP任务中表现出了卓越的性能[Devlin et al,2019]。因为PLM产生上下文感知的令牌表示,它们既可以用于产生令牌嵌入,也可以用作编码器。根据标记方案,我们将模型分为基于token的模型、基于span的模型和基于图的模型。
生成式模型 Generative Models
生成模型将OpenIE定义为一个序列生成问题,它读取一个句子并输出一系列的提取。图2(d)给出了生成序列的示例。形式上,给定一个令牌序列S和期望的提取序列Y = (y1, y2,…, ym),模型使条件概率Q P(Y |S) = IIp(yi |y1, y2, . . . , yi−1; S); 也有生成对抗性元组的工作,目的是使分类器难以将它们与真实元组区分开来。
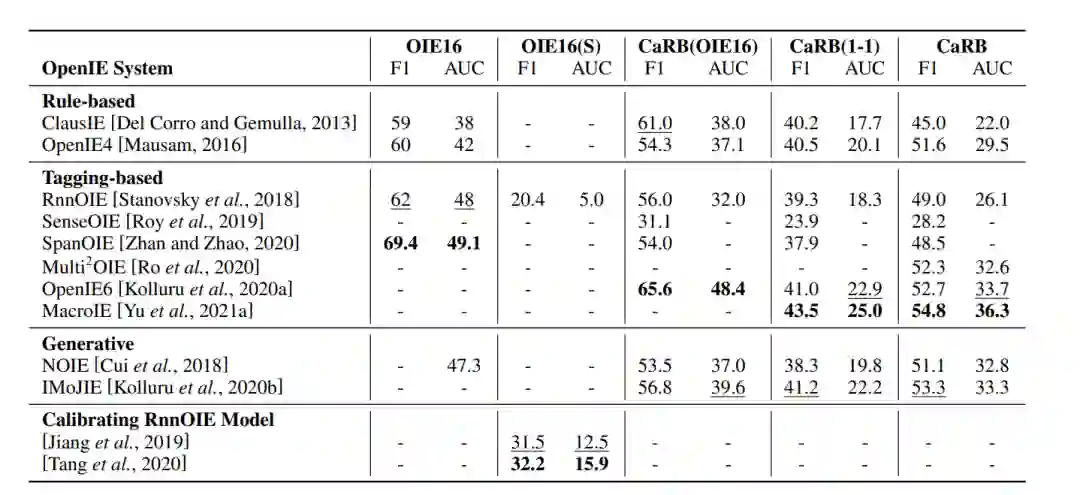
模型结果比较
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NIE” 就可以获取《南洋理工阿里巴巴等首篇《神经开放信息抽取》综述论文,系统阐述最新神经信息抽取关键技术》专知下载链接



