

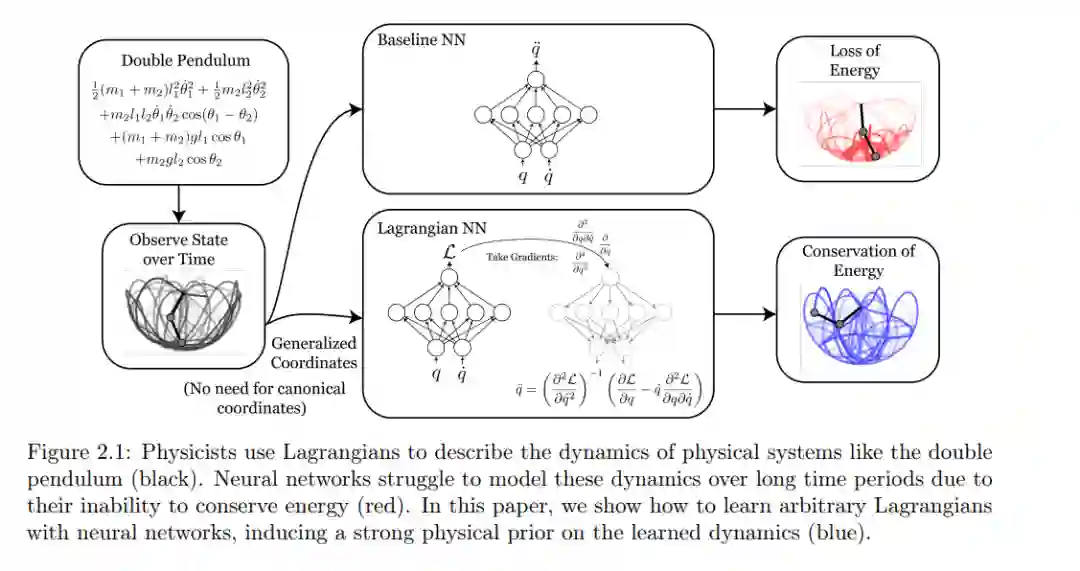
如果1609年已经有机器学习技术,开普勒会发现他的定律吗?还是他会满足于黑盒回归模型的准确性,导致牛顿没有灵感去发现万有引力定律?在这篇论文中,我将对物理科学领域中机器学习及其用例进行回顾。我将强调科学应用中面临的一个主要问题:缺乏可解释性。过度参数化的黑盒模型容易在训练数据中记住伪相关。这不仅威胁到使用机器学习取得的研究进展,而且剥夺了科学家最强大的工具箱:符号操纵和逻辑推理。考虑到这一点,我将展示一个可解释机器学习框架,使用物理驱动的归纳偏差和一种名为“符号提炼”的新技术。这些方法的结合使从业者可以将训练好的神经网络模型转换为可解释的符号表达式。首先,我将讨论执行这种提炼的深度学习策略,然后回顾“符号回归”,这是一种使用进化算法优化符号表达式的算法。尤其是,我将描述我的PySR/SymbolicRegression.jl软件包,它是一个易于使用的高性能符号回归包,适用于Python和Julia。与此相关,我将讨论一些使这种技术更有效的物理驱动的归纳偏差。在论文的下半部分,我将回顾这种和其他可解释机器学习技术在天体物理问题上的各种应用。这些包括:宇宙学中的宇宙空洞、计算流体动力学中的子网格尺度建模、最优望远镜时间分配、恒星和引力波天文学中人口模型的灵活建模,以及学习有效且概率严格的行星不稳定性模型。





成为VIP会员查看完整内容
相关内容

普林斯顿大学,又译
普林斯敦大学,常被直接称为
普林斯顿,是美国一所私立研究型大学,现为八所常青藤学校之一,绰号为老虎。
Arxiv
0+阅读 · 2023年6月3日
Arxiv
0+阅读 · 2023年6月1日



相关VIP内容
相关资讯