

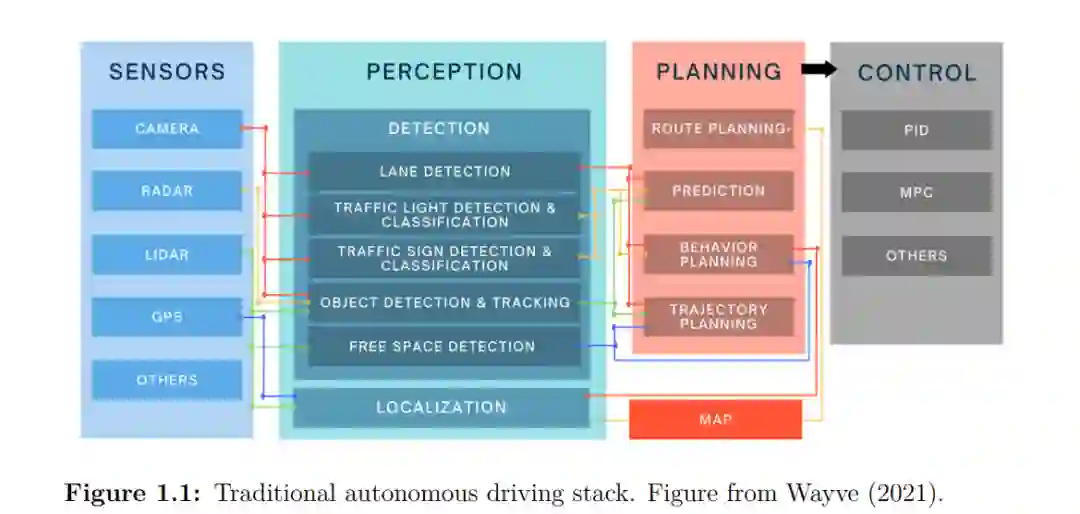
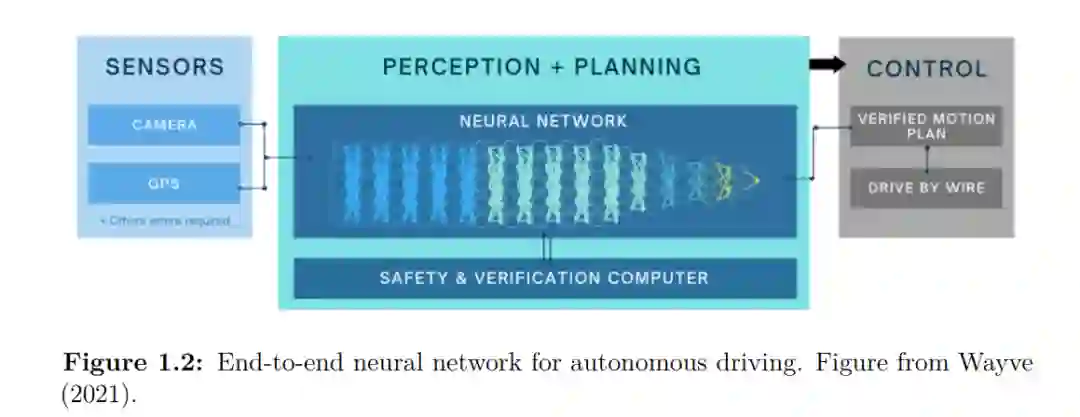
**人类通过被动观察和主动互动来学习世界的心理模型,从而在环境中导航。他们的世界模型允许他们预测接下来可能发生的事情,并根据潜在的目标采取相应的行动。**这样的世界模型在自动驾驶等复杂环境的规划方面具有强大的前景。人类司机或自动驾驶系统用眼睛或相机感知周围环境。他们推断出世界的一种内部表示应该:(i)具有空间记忆(例如遮挡),(ii)填充部分可观测或有噪声的输入(例如被阳光蒙蔽时),以及(iii)能够概率地推理不可观测的事件(例如预测不同的可能的未来)。它们是具身的智能体,可以通过其世界模型在物理世界中预测、计划和行动。本文提出一个通用框架,从摄像机观察和专家演示中训练世界模型和策略,由深度神经网络参数化。利用几何、语义和运动等重要的计算机视觉概念,将世界模型扩展到复杂的城市驾驶场景。**在我们的框架中,我们推导了这种主动推理设置的概率模型,其目标是推断解释主动代理的观察和行动的潜在动力学。**我们通过确保模型预测准确的重建以及合理的操作和过渡来优化日志证据的下界。首先,我们提出了一个模型,预测计算机视觉中的重要量:深度、语义分割和光流。然后,我们使用三维几何作为归纳偏差在鸟瞰空间中操作。我们首次提出了一个模型,可以从360◦环绕单目摄像机鸟瞰动态代理的概率未来轨迹。最后,我们展示了在闭环驾驶中学习世界模型的好处。我们的模型可以联合预测城市驾驶环境中的静态场景、动态场景和自我行为。我们表明,学习世界模型和驾驶策略可以生成超过1小时的预测(比训练序列大小长2000倍)。



成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年3月22日


相关VIP内容
相关资讯