
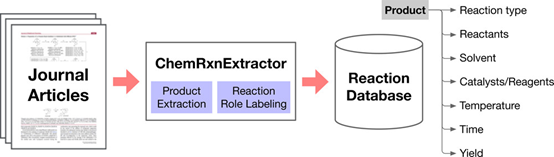
科学文献(如期刊文章和专利)一直是药物化学家寻找特定化学反应或感兴趣的合成方法的重要信息来源。目前,基于非结构化文献中构建结构化数据库的Reaxys和SciFinder已经成功投入商业化多年。这些数据库通常是手工提取文献内容,成本高、耗时长且专业知识密集,已经难以跟上科学文献的指数增长速度。Regina Barzilay课题组设计了一个统一的结构化语义架构表征化学反应,将两个深度神经网络构建的“产物提取模块”与“反应角色标签模块”结合,自动解析期刊文章中的化学反应并提取到与Reaxys和SciFinder数据库一致的架构中。该数据为药物化学家提供结构化的反应信息,并可直接用于计算机辅助化学、反应结果预测、反应条件筛选和自动合成设计等方面。该项工作近日发表于美国化学会出版的化学信息学权威期刊Journal of Chemical Information and Modeling【1】。 目前,化学领域的信息提取主要集中在命名实体识别(NER)和相关性质的提取上,如OSCAR和ChemDataExtractor。较少的工作针对化学反应的提取,NER有助于将化合物和文本联系起来,由此开发了目前两个代表性工具包ChemicalTagger和OPSIN。OPSIN基于ChemicalTagger的标记和解析输出一组规则来识别产物。 理想的反应架构应该具有反应原料、结果、反应条件和后处理等足够的信息来反映该化学反应,且架构简洁明了。作者引入了一个统一的语义架构表征反应,包含作为中心因素的产物和八个相关的反应角色(反应物、反应类型、催化剂/试剂、加工试剂、溶剂、温度、时间和产量)。使用ChemDataExtractor工具对从1906年至2016年在多种化学期刊上发表的200,000篇文章中的反应描述段落进行预处理(如句子切割、标记等)。随后将所有预处理过的段落进行人工注释工作,最终按照8:1:1的比例将语料库分为训练、开发和测试集。产物提取与反应角色标签标记
基于以上的思路,作者提出的两阶段架构,即产物提取模块和反应角色标签模块来提取反应。产物提取模块从给定文本中识别所有可能的产物,再对每个产物的上下文中出现的反应角色进行标记,以输入文本和给定的产物为条件,制定一个序列标签任务,并最终构成化学反应。 在输入中添加特殊标记,把目标产物告知Transformer编码器,计算每个词块的隐藏表征,同时将每个单词的第一个单词片段作为条件随机字段(CRF)的输入用于序列标记的解码器。使用“BIO”标记方案对所有剩余标记执行序列标记,以识别相关的反应角色。
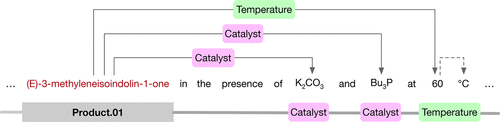
图1. 反应角色的提取与反应角色标签标记
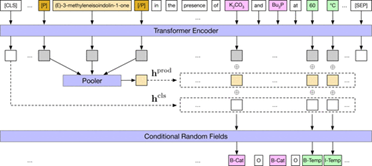
图2. 反应角色提取的模型架构ChemBERT****和ChemRxnBERT预训练
作者试图减少对深度神经模型监督训练的大量标记数据的依赖,采用pretraining-and-finetuning的范式来训练产物提取和角色标签模型。首先使用无监督目标在大规模无标签文本上预训练Transformer编码器,然后在规模有限的特定任务标签训练数据上对其进行微调。因此,作者提出一个级联的自适应预训练方法,由两个阶段组成:领域自适应预训练,产生一个针对化学领域的预训练编码器(ChemBERT);任务自适应预训练,产生一个针对任务的预训练编码器(ChemRxnBERT)。这两个产生的编码器分别用于产物提取和反应角色的标记。 其中ChemRxnBERT的预训练需要一个更有约束性的化学文本集,与目标任务更加一致。为了解决这个问题,作者使用产物提取模型作为文本检索器,从整个化学文本空间中自动识别反应相关的数据,即选择至少包含一个产物的句子。 最终,ChemBERT在F1上比报道过的BERT模型取得了10.27%的绝对改进,而ChemRxnBERT仅收获2%的改进,原因可能是ChemRxnBERT是通过句子级的屏蔽语言建模来适应ChemBERT,若用更大的语言规模进行预训练应该能有更优的表现。与Reaxys的比较
最后,将提取后的反应与人工构建的Reaxys数据库进行了定性比较。例如图3中的反应,最明显的是“DMSO”被ChemRxnExtractor系统识别为溶剂,这符合文本描述。但Reaxys将“DMSO”归为反应物,因为其确实作为硫源参与了这个反应。Reaxys报告的反应产率值是四舍五入的,与此相反,该系统设计为文章中精确数值。 但是,因为该系统提取的内容是基于有限的段落,无法提取前后文中的特定反应角色。如图3中,Reaxys提供的反应时间、反应过程等信息,均在该系统中缺失。
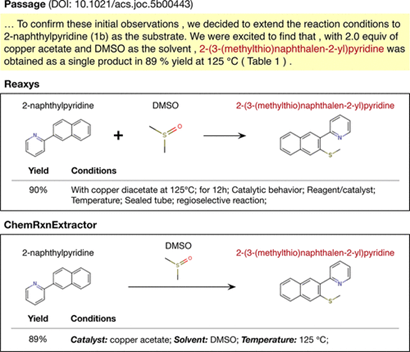
图3. ChemRxnExtractor提取与Reaxys中手动抽象的单一反应的简单反应的比较 该自动化表征系统与额外的光学化学结构识别(OCSR)工具结合起来,进行化学实体的确认。如图4,Reaxys往往会忽略失败反应或副反应,该化学文献系统能够提取这些数据,给科研工作者提供更多的参考价值。 针对多步骤的反应(第一个反应的产物是第二个反应的原料),传统的提取方法和该系统均无法处理,因此均未被收录在Reaxys和该系统中。
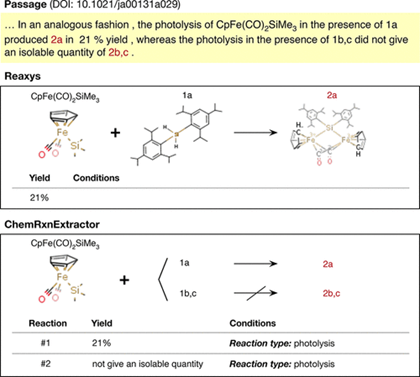
图4. ChemRxnExtractor提取与Reaxys中手动抽取CpFe(CO)2 SiMe3在与不同的反应物偶合时得到不同的结果的比较总结
该工作构建了一个从文献中提取化学反应的自动化系统,该系统由建立在编码器-解码器的架构上的产物提取和反应角色标签两个单独模块组成,达到与现有人工收集的商业数据库一样的效果。该系统通过领域和任务相关的无标签数据进行自适应训练,使检索到的句子与反应数据吻合,并能精确解析文本中复杂的产物-反应角色关系,但受文本内容限制容易出现区分催化剂和试剂的错误。未来,随着反应描述更加公式化和该系统识别性能优化,该方法必将能更高效的提取日益庞大的期刊数据,也能侧面启示现有商业数据库的功能提升与改进。参考文献【1】Jiang Guo, A. Santiago Ibanez-Lopez, Hanyu Gao, Victor Quach, Connor W. Coley, Klavs F. Jensen, and Regina Barzilay. Automated Chemical Reaction Extraction from Scientific Literature. J. Chem. Inf. Model. 2022, 62, 9, 2035-2045.

