
每年,在PubMed等公开网站上发表的数以千计的临床前研究中描述了大量的非结构化医学知识。这些知识的汇总在各种医学应用中起着重要的作用,如循证医学中的疗法开发,即根据迄今为止文献中发表的最佳可用证据做出决定。然而,由于它们的自然语言格式,对现有信息的手工汇总是繁琐和耗时的,研究人员很难做到。针对这个问题,我们关注的是在支持循证决策的详细程度上对结构化知识的自动信息提取。具体来说,我们关注的是用描述脊髓损伤领域实验结果的临床前研究的信息来自动填充深度领域知识图。一个重要的挑战是,一项研究包含了由总共7816个(依赖)研究参数描述的多个结果。由于联合提取所有这些参数的问题到目前为止是难以解决的,我们提出了一个分层结构,以自下而上的方式预测递增的可行子结构,依靠统计推理和条件随机场作为我们系统的核心。这项工作的主要贡献是开发了一种机器学习方法,该方法被整合到一个整体的领域适应性信息提取系统中,能够预测以自然语言编写的临床前研究中描述的实验结果的全部细节。我们提出了一种根植于结构预测和模型完整文本理解范式的提取深度嵌套结构的一般方法。我们进一步确定了特定领域的挑战,并提供了相应的解决方案。我们展示了如何有效地评估由我们系统预测的复杂嵌套结构,并提出了一个全面的评估,以了解它在多大程度上可以用于支持证据聚合所需的深度。我们表明,对于我们领域本体的许多类,信息提取的结果是令人满意的,并确定了那些需要进一步研究的内容。

第1章 简介
本章概述:在这一章中,我们将介绍并激励我们的主要研究课题:用从自然语言文本中自动提取的信息填充深层领域知识图。我们提供了对一般问题的非正式描述,并根据一个简化的例子勾勒出挑战和要求。这使我们能够在接下来的时间里阐述我们的贡献和研究问题。在引言的最后,我们对其余各章和本论文主要基于的已发表的工作进行了概述。
1.1 动机
每年,在PubMed等公开网站上发表的数以千计的医学研究报告中都描述了大量的非结构化知识。这种信息库是一种宝贵的资源,在各种医学应用中发挥着重要的作用,如治疗方法的开发或循证医学,在这种情况下,要根据迄今为止在文献中发表的最佳可用证据做出决定[1]。医学知识以聚合的形式提供给研究人员,其好处不仅限于临床环境,而且在临床前领域也发挥着重要作用。动物实验是昂贵的,而且往往在道德上存在争议。在这里,现有的证据可以为临床前研究的设计提供参考,从而减少不必要的试验数量。此外,汇总的知识支持将临床前研究结果转化为临床实践,特别是对于那些尚无有效治疗方法的疗法[2]。
然而,相关的信息很少以结构化的形式出现,这样就可以很容易地进行知识的汇总,因此其获取通常是基于手工审查数百份出版物。由于信息的自然语言格式,这种手动过程是一项繁琐而耗时的工作。此外,它需要相当多的领域知识,研究小组很难完成,更不用说个人研究人员了,因此有整个组织和社区致力于这项任务,例如Cochrane基金会。虽然,有一些尝试鼓励研究人员以结构化的形式发表他们的研究结果,但常见的出版做法仍然是使用自然语言对有价值的知识进行 "编码"。因此,进行系统综述需要付出很大的努力,而且随着可用信息库的不断增加,手工汇总现有知识成为一项不可行的任务。
解决这一缺陷的一个办法是依靠能够自动处理成千上万的文件的机器学习方法。为了开发通过结构化知识提供大量证据的算法,我们关注医学领域自然语言文本的自动信息提取(IE)。具体来说,我们专注于描述脊髓损伤(SCI)领域实验结果的临床前研究,旨在为基于证据的决策提供必要的细节水平。SCI描述了意外(临床领域)或实验(临床前领域)对脊柱造成的损害,除其他健康限制外,往往导致受影响的人部分瘫痪。尽管仍然缺乏临床SCI流行病学的可靠数据,但在发达国家,SCI的发病率从每百万人中的13.1到163.4不等,并且在全世界范围内每年增加约17000人[3]。尽管人们的兴趣和研究不断增加,在2020年共有75,475篇同行评议的PubMed列出的临床和临床前出版物,尽管有一些单例报告,但没有对照的临床试验证明可重复的治疗成功[2]。
在某一领域成功进行知识聚合的一个重要前提是,这些信息对人类领域专家和机器来说都是容易获取和理解的。也就是说,不是以压缩的文本形式(如摘要)或半结构化的形式(如富含标记语言的文本)提供信息,而是必须完全结构化并遵循一致的特定领域词汇。这使得机器可以对数据进行明确的操作,这样一旦有足够的数据,就可以用高级访问工具(半)自动进行知识提供、过滤和元分析。
在脊髓损伤领域,临床前试验有高度控制的实验设置,研究方案具体到最后的细节,描述了实验结果的所有必要的关键参数。这些结果为新研究的设计提供了重要的信息来源,因此是临床医生和研究人员的宝贵资源。为了使提取的知识尽可能的有利可图,有必要将这些实验结果以一种结构化的、一致的形式表示出来。这种格式必须基于特定领域的词汇,易于被SCI专家理解,支持必要的细节水平,并促进机器的可操作性。定义符合上述要求的感兴趣的领域的一个常用方法是依靠本体的概念[4]。领域本体描述了与研究领域相关的类、属性、分类学依赖性和类/属性约束。在这项工作中,我们依靠Brazda等人开发的脊髓损伤本体(SCIO)[5, 6],它全面地定义了临床前结果的结构和词汇,包括所有的关键参数,如比较的实验动物组,造成的伤害类型,研究的治疗和测试,以及客观结果等。此外,SCIO是许多与问题相关的应用(见第8章)和我们在这项工作中开发的核心方法(见第5章)的骨干,因为它通过定义要提取的结构来指导推理过程。总之,我们的系统旨在预测本体的相关类和属性所描述的知识结构,这些结构随后被用来填充所谓的深域知识图谱(DDKG)。
1.2 深度领域知识图谱的填充
在本论文中,我们遵循Paulheim等人对知识图谱(KG)的一般定义[7],即知识图谱基本上由两部分组成,一是包含类和关系词汇的描述性数据图谱,二是数据本身,基本上是关于存储在知识图谱中的实例的断言[8]。经典的知识图谱以机器可读的格式存储人类知识,包括代表基本信息单元(BIU)的节点和代表这些节点之间关系的边。虽然这种基本的数据表示是相当简单的,但任意复杂的知识结构都可以被有效地描述[9]。因此,KG中的一个数据点由一个所谓的h s, p, oi三重体表示,该三重体包括一个主语(s)和一个宾语(o),两者都对应于知识图谱的节点,以及一个反映s和o之间关系的谓词(p)。一般来说,节点对应于现实世界的实体或字面价值,而谓词表示这种实体的特定属性/特性。请看下面的例句:
"巴拉克-奥巴马生于1961年。"。这个句子中包含的人类知识可以表示为一个三联体,即h dbr:Barack Obama, dbo:birthYear, "1961 "i 。命名空间dbr:(DBpedia资源)和dbo:(DBpedia本体)提供了重要的信息,因为它们将提及的 "Barack Obama "和 "was born "分辨为正确的现实世界实体http://dbpedia.org/resource/Barack Obama和属性http://dbpedia.org/ontology/birthYear,分别在相应的本体,DBpedia中。
我们的目的是用从自然语言文本中自动提取的信息填充深层领域知识图谱(DDKG),重点是SCIO所描述的深层关系领域结构的整体提取。因此,我们把我们的任务称为从文本中提取深层领域知识图谱,下面将详细解释这个术语。
领域与开放:存储在领域知识图谱(DKG)中的信息被严格限制在一个特定的词汇中。因此,图的可能元素,即节点(实体和字词)和边(关系),强烈依赖于特定的领域。原则上,对领域的规范没有限制,所以在文献中出现了各种DKGs,例如,针对生物医学数据[10]、脊髓损伤元数据[11],甚至是中国的娱乐活动[12]。与之相反的是开放或通用领域知识图谱的范式,它存储各种类型的人类知识,不一定遵循某种结构或领域[13-16]。在开放领域的突出例子是。DBpedia[17], Freebase[18], 和WikiData[19]。
深度与浅度:受 "深 "这个术语的常见人工智能含义的启发,一般指的是深层神经网络架构[20](DNN;许多隐藏层),我们正在调整这个术语,以指我们旨在提取的复杂关系和(深度)嵌套领域结构。因此,深层领域知识图是一个由多层定义良好的子图组成的图,其依赖关系是由特定领域词汇预先定义的。我们在图1.1中描述了浅层知识图和深层领域知识图之间的结构差异。主要区别在于,DDKG中的每个节点并非都是指一个基本的信息单元。某类子图的内在语义是以其整个相关的三要素/属性为整体基础的。在下文中,我们把这种子图称为基本结构单元(BSU)。
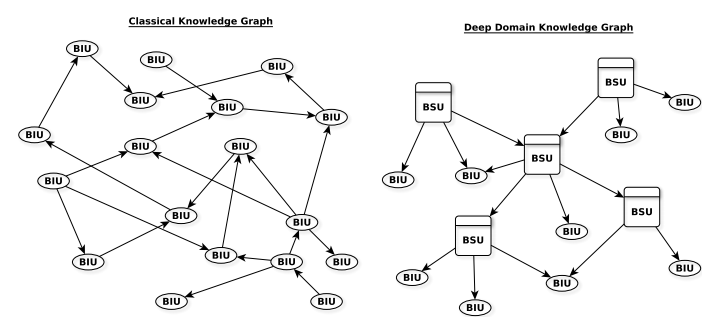
图1.1: 浅层和深层领域知识图的结构比较。左边显示的是经典结构,其中每个节点指的是一个基本信息单元,如实体和字词(BIU;椭圆)。右边显示的是深层领域结构,其中只有叶子节点被认为是BIU,整体定义的子图被称为基本结构单元(BSU;方块)。
1.2.1 简化实例
知识图谱群(KGP)的原理描述了从自然语言文本中自动提取结构化信息,通常是以三元组的形式。KGP指的是 "填充 "一个图的任务,数据结构是预定义的,不会改变。考虑以下图1.2左侧描述的医学治疗领域的例子。一个治疗方法的定义是:i)化合物,ii)剂量,和iii)给药方法,进一步定义为 1)持续时间,2)地点,和3)给药类型。相应的数据模式提供了两种不同类型的位置,即胸腔和腰部,(仅)一种给药方式,即注射。此外,这个领域有两种不同的化合物,即雌激素和生理盐水,而剂量和持续时间可以是任意的文字值。
给出以下例子的输入文本,根据领域包含有价值的信息,目标是捕捉文本中关于领域可表达的所有信息,而忽略那些不表达的意义方面。
- "我们比较了20毫克和25毫克的不同雌激素剂量的治疗效果。两种溶液都是在胸腔水平注射的。高剂量在3秒的时间内应用,而低剂量在2秒内应用。"
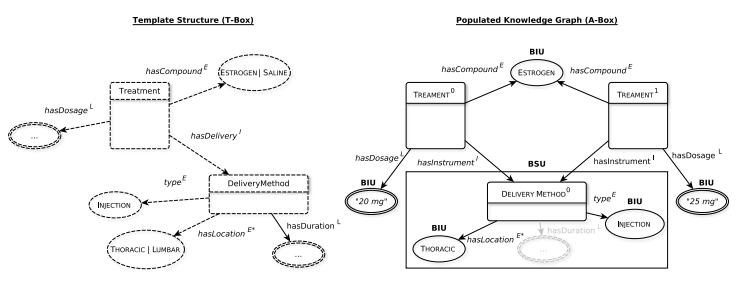
图1.2:一个领域和一个填充的知识图谱的描述示例。左边显示的是这个描述治疗方法的示例领域的模板结构。右侧显示的是由两个治疗实例和一个给药方法实例组成的深度领域知识图。
图1.2的右侧显示了用相关信息填充的深度领域知识图。根据数据结构,输入文本中包含的信息描述了两种不同的治疗方法和两种不同的给药方法。两种治疗方法都使用相同的雌激素化合物,但在提到的剂量上有所不同,即20毫克和25毫克。请注意,根据领域规范,这个例子文本中的每个信息都没有正确地反映在填充的图表中。这两种治疗方法错误地(!)共享相同的给药方法,因为持续时间的描述缺失影响了知识图谱中不同给药方法的数量。我们在第1.2.3节中详细讨论这个问题。
1.2.2 术语和符号
在下文中,我们将通过与前面的知识图谱相关的例子来介绍我们的术语和符号。
实体 实体是知识图谱中的一个简单的叶子节点,它没有进一步的出站边。实体节点指的是数据架构中描述的现实世界的实体。一个实体的信息价值不是它的相关文字描述(如果有的话),而是它的特定实体类型。在下文中,我们把实体称为文件中的特定实例,把实体类型称为其概念语义。我们用小写字母来表示它们。在我们的例子中,有5种不同的实体类型,即。雌激素、盐水、胸腔、腰部和注射。
字词 字词是知识图谱中另一个基本的叶子节点。与实体不同,它们的信息值是以字符串的形式表示的。当存在无限可能的表达式或数值时,通常会将特定的信息建模为字面意义,例如在建模自然数或事物的名称时。因此,使用字词的主要动机是为了节省领域建模的复杂性。在知识图谱中,特别是在知识聚合的背景下,使用字词的主要缺点是,它们通常不能自动解释,这也是聚合或过滤数据(例如,显示剂量小于20毫克的雌激素治疗)或其他元数据分析的需要。与实体不同,字面类型原则上是不相关的,因为字面内的文本包含了所有的相关信息。因此,在本工作的提醒中,我们通常省略字面的类型。我们用斜体表示字面,周围有引号。在我们的例子中,"25毫克 "和 "20毫克 "是代表雌激素治疗剂量的字面值。
实例 实例是深度领域知识图谱中最核心的元素。在图本身中,它被表示为一个基本的结构单元,由各种三要素组成,整体上定义了实例的内在语义。一个给定类的实例是由相应的特定领域的数据结构描述的,并由一组属性定义。在许多情况下,一个实例与一个特定的实体类型有关,这反映在某个属性中。因此,我们用小写字母表示一个特定类别/实体类型的实例,并在上标中补充一个独特的实例ID。这个知识图例包含三个实例。两个治疗方法,即Treatment0和Treatment1,以及一个交付方法的实例,即DeliveryMethod0。此外,我们区分了六种不同类型的属性:实体类型、字面类型和实例类型,它们可以是单值或多值的。
实体类型的属性 实体类型的属性(ETP)是一个实例的属性槽,可以用数据结构定义的特定类型的实体来填充。在知识图谱中,实体类型的边连接着一个实例的头部节点和一个实体节点。我们用斜体表示ETP,用E或E∗的后缀分别表示单值和多值属性。在我们的例子中,hasCompoundE和typeE是单值的ETP,而hasLocationE∗是多值的ETP。
文字型属性 文字型属性(LTP)是一个实例的属性槽,它充满了基于字符串的文字值。在知识图谱中,LTP边连接了一个实例的头部节点和一个字面值。我们用斜体字表示LTP,后缀为L或L∗。在我们的例子中,hasDosageL表示这样一个LTP,它存储了一个治疗的剂量,例如 "20毫克"。
实体类型属性 实体类型属性(Instance-Typeed Property,ITP)是一个实例的属性槽,它被填充到一个特定类别的另一个实例中,导致知识图谱的深层关系结构。与ETP类似,ITP的可能值集被限制在由数据链定义的某一组实体类型/类中。在知识图谱中,一个ITP连接着两个实例头节点。我们用斜体字表示一个ITP,后缀为I或I∗。在我们的例子中,实例类型的属性hasDeliveryI将两个治疗实例Treatment0和Treatment1连接到交付方法实例DeliveryMethod0。
缩进式注解 在本论文中,我们使用以下缩进式注解来表示例子中的具体实例。上述例子中的三个实例被写成:

1.2.3 涉及的任务
用自然语言文本中的信息自动填充深层领域知识图,原则上可以表述为:。
- "在一个给定的输入文本中描述了多少和哪些特定类别的实例?"。
回答这个问题需要解决几个自然语言处理(NLP)问题,这些问题可以大致归纳为三个主要任务。首先,命名实体识别和链接(NERL)处理实体和字词等基本信息单元的检测和消歧义。第二,关系提取(RE)涉及识别实例、实体和字词之间的关系,以形成基本的结构单元,即实例化和填充特定领域的模板。第三,共同参照解析(CRR)关注的是确定哪些信息单元属于同一等价类。在下文中,我们将进一步详细勾勒出挑战和要求。
命名实体识别和链接 NERL描述了标记文本中与某些知识库中的特定实体相对应的词或短语(识别任务)的任务(链接或消歧义任务)。由于识别实体在许多下游应用中的普遍重要性,NERL是NLP中一个广泛研究的领域[21, 22]。与经典的NERL相比,文献中只有少数作品专门关注字面价值的建模、识别或解释[23-25]。这些工作大多是在基于本体的信息提取背景下发表的[23, 26]。字面意义和实体共同构成了基本的信息单元,定义了文本中包含的信息范围。在这项工作中,我们的数据模型包含了670多种实体类型和8种相关的文字类型。
关系抽取 有几个任务定义和关系抽取的方法[27]。最基本的关系提取被表述为预测两个实体之间是否存在二元关系[28],虽然在早期的研究中,NERL和RE的任务被孤立地处理[29-31],但近年来,它们经常被一起处理[32-34],通常会导致更高的性能。大多数研究发生在开放领域,因此在实体分类和关系层次方面处于非常浅的结构水平。将其应用于特定领域的资源是具有挑战性的:依赖领域的任务通常具有更高的复杂性,需要更多的数据来可靠地训练普通的监督机器学习系统。同时,对资源进行注释是一项费力的工作,需要领域的专业知识。在特定领域背景下提取多个从属关系的一种方法是将任务制定为一个填槽问题[35],即用文本中的字面价值填充一个预定义的模板。这样做的好处是,多个关系可以被共同看待,从而受益于相互信息。与一般在开放领域考虑的二元关系提取不同,填槽大多在特定领域考虑,因为这种模板通常是该领域所需信息的模型[36]。经典的填槽法与我们的工作非常相关,可以被认为是解决深层领域知识图谱问题的一个很有前景的方法。然而,为了解决我们问题的复杂性,我们不能将填槽限制在从文本中提取的字符串字面。相反,必须考虑实体或嵌套实例,目的是在文档层面而不是文本层面提取知识。我们的数据模型总共包含了10个嵌套实例类和26个不同的关系。
协同参考解析 为了回答在推理过程中需要实例化多少个实例来填充深层领域知识图谱的问题,原则上有三种类型的协同参考解析任务需要解决。
首先,解决命名实体的共同参照问题。在实体识别和链接过程中,这一点经常被隐含地解决,因为两个与同一类型相关的公认的实体提法也指的是同一个现实世界的实体。
第二,解决字词的共同参照,如某些实例的 "名称 "或 "提及",如在整个临床前研究的文本描述中以多种形式出现的实验组名称。例如,"对照组 "和 "对照动物 "这两个名称是指同一个实验组的实例。这种类型的共同参照解析与经典意义高度相关,但重点在于领域的具体提及。此外,具有上下文语义的字词之间的共同参照也需要被解决。例如,考虑到 "低剂量"、"高剂量"、"10毫克"、"20毫克 "这四个提法。预测 "低剂量 "实际上是指 "10毫克",需要系统理解10在数学上小于20,而低这个词在语义上小于高。
第三,心数预测的任务,即文本中描述了某些类别(如结果、实验组、动物模型、治疗等)的多少个实例。这需要解决所谓的未命名实体或未命名实例的共同参考。对于那些没有提到现实世界中任何现有实体,而且通常在文本中没有明确提到的实例,其等价类的识别完全基于它们的描述性属性,这就要求信息提取系统 "理解 "所需要的知识,并推断出即使没有被明确提到的实例。这与那些自下而上的、不受底层数据架构指导的方法形成了对比,因此,这些方法仅限于提取命名实体之间的(二元)关系。然而,在复杂的领域中,比如我们在这里考虑的领域,有许多未命名的实体是高度相关的,仅仅依靠NERL的方法是不可能检测出来的。在我们的领域中,未命名实体的主要实例类是一项研究中描述的实验结果,这些实验结果通常没有命名,即每个结果都有一个名称。然而,为了知识聚合的目的,提取所有的主要结果和它们的参数是很重要的。
方法 为了在一个系统中解决上述任务,我们的方法依赖于领域本体的指导,该本体定义了系统需要提取的知识结构,反映了一项研究的整体设计、方案和关键结果。在本工作所讨论的脊髓损伤的背景下,一项研究描述了1到92个(平均21个)结果,每个结果由28到198个(平均76个)因果变量(结果参数)规定。6由于联合提取所有这些变量的问题到目前为止是难以解决的,我们提出了一个分层管道架构,以自下而上的方式预测逐步可行的子结构。我们的方法的核心是一种统计推理方法,它依靠条件随机场(CRF)从输入文本中推断出最可能的领域模型实例。我们把这项任务称为模型完整文本理解(MCTC),在我们以前的工作中已经介绍过[37]。深度领域知识图谱的自动生成需要大量的文本理解,这在迄今为止的文献中尚未得到解决,这使得它成为一项有趣的NLP研究任务。
我们的方法的主要好处是,它支持:i)通过一个适当的工具(我们称之为SCIExplorer)探索知识,ii)回答能力问题,以及iii)自动分级治疗,这项工作通常是以手工方式进行的[38]。除了支持证据的按需汇总外,我们的方法还有一个优势,即通过提供迄今为止所进行的实验的系统概述,可以避免多余的研究,优化计划研究的实验设计,并指导新假设的开发。
1.3 内容概述
以下部分对本论文进行了简要概述。我们总结了我们用从自然语言文本中自动提取的信息填充深度领域知识图的任务的主要挑战。我们提出了我们要回答的相关研究问题,并介绍了我们的主要贡献和次要贡献。
1.3.1 挑战和研究问题
从自然语言文本中自动提取复杂的嵌套结构以填充深度领域知识图是一个具有挑战性的NLP问题,因为它涉及到各种经典的NLP任务,如识别和消除输入文本中的实体和字词,提取它们之间的多种关系,解决它们的共同引用,并预测结构的卡特尔。所有这些任务本身都是具有挑战性的研究领域,处理常见的NLP问题,如模糊性、含义、表达性等。在一个能够完成所有这些任务的整体系统中,机器学习方法的发展带来了进一步的概念性挑战,我们将在下文中讨论。基于上述给定的问题描述、例子和所涉及的NLP任务,接下来的四段将讨论这些挑战,并通过制定精确的研究问题来总结这些挑战。
挑战1:问题建模 我们的信息提取方法植根于模型-完整文本理解范式[37],旨在从自然语言文本中自动提取多个深度嵌套结构。特别是,我们将这一任务作为一个结构预测问题来处理,并用条件随机场和因子图建立概率推理模型。在这种情况下出现的一个挑战是对机器学习模型进行适当的建模。这涉及到以语法方式对问题进行建模,回答如何在CRF和因子图中表示和处理嵌套结构的问题,也涉及到以语义方式回答如何产生足够的统计数据以产生有意义的预测特征描述的问题。
在句法方面,相应的研究问题可以精确表述为:
-
问题1.1: 我们如何将深度嵌套结构表现为结构预测问题?
-
问题1.2:我们如何在嵌套结构表示中对基数进行建模?
捕捉预测结构的语义是一项具有挑战性的任务,因为它需要对目标随机变量进行充分的特征描述,这是一项耗时的工作,需要一定的领域知识。相应的研究问题可以精确表述为。
- 问题1.3:我们如何建立充分的统计模型,捕捉多个嵌套结构的重要关键信息?
挑战2:可操作的推理 在高度关系型和多变量数据中进行精确推理通常是不可操作的,因为它随着要预测的目标变量的数量呈指数级增长。在深层领域知识图谱的背景下,这个数字可能在每份文件的几百到几千之间。因此,总体的挑战是设计出可操作的近似推理,同时又不限制系统预测所需结构的全部复杂性的能力。相应的研究问题可以精确地表述为。
- 问题2.1:我们如何对复杂的嵌套结构建立可操作的推理模型,以满足深度领域知识图谱的要求?
最近的研究经常证明,当多个NLP问题被联合处理而不是在一个管道中处理时,(概率)预测的性能会增加。另一方面,一个主要的缺点是,联合模型往往需要更多的训练数据,因为问题的复杂性通常会呈指数级增长。考虑到与深层领域知识图谱相关的各种NLP任务,挑战在于如何在考虑到可用的标记训练数据量的情况下,在利用联合能力和复杂性之间找到一个平衡的权衡。在推理方面出现的一个特别的挑战是探索cardinalities的问题。由于对文件中提到的信息量没有自然的限制,例如研究结果、实验组等的cardinality,这里的一个挑战是推断结构和多值属性的cardinality。相应的研究问题可以精确地表述为。
- 问题2.2: 我们能在多大程度上以及如何有效地建立联合推理模型?
最后,最重要的是对未命名的实体进行推理建模,即在文件中没有明确提到头部实体的结构化实例,因此基于NER的经典方法是众所周知的失败。相应的研究问题可以精确地表述为。
- 问题2.3:我们如何对未命名的实体进行推理?
挑战3:领域问题分解 深入的领域知识图谱需要解决几个自然语言任务,如实体识别、实体链接、关系提取、共同参照解析和心量预测。此外,我们的目标是全面的文本理解,捕获不同的信息结构,如动物模型、伤害模型等,这些定义分布在整个文档中。因此,进一步的挑战是设计一个整体提取问题的适当分解,对语义相关的变量进行联合推理,同时在没有必要进行直接信息交换的情况下放宽独立假设。相应的研究问题可以更准确地表述为。
- 问题3.1:我们如何才能有效地将复杂结构的整体提取问题分解为可操作的、可有效解决的子任务?
鉴于将我们开发的方法应用于脊髓损伤领域提取临床前结果的具体领域,重要的是解决与领域相关的困难,设计启发式方法以克服分解的最终缺陷。
- 问题3.2:哪些问题特别出现在脊髓损伤领域,如何解决这些问题?
我们的总体挑战是建立一个全面的系统,i)整合所有分解的组件,ii)解决上述的NLP任务,以及iii)输出最可能的结构,包含临床前研究的 "真正 "信息内容的全部细节。相应的研究问题可以被表述为。
- 问题3.3:在脊髓损伤领域的临床前研究中,我们如何建立一个全面的领域知识图群系统?
挑战4:评估 最后,我们要解决的挑战是评估我们在这项工作中旨在预测的深度嵌套结构。在推理和模型参数学习过程中,适当的评估对于计算更新-德尔塔和产生适当的学习信号起着关键的作用。在推理过程中,执行模型更新是一个经常被调用的子程序,因此是一个时间关键性的操作。另一方面,一个不准确的学习信号会导致错误的参数更新和不准确的模型学习。此外,我们有兴趣在最终评估中评价我们提出的方法和系统结构的优点和缺点,以了解我们的系统在多大程度上可以用于支持证据汇总所需的深度和可靠性的研究。相应的研究问题可以表述为。
- 问题4.1: 我们如何有效地评估深度嵌套结构?
为了深入了解我们系统的性能和产生的输出错误,必须了解单个组件的故障。这就引出了研究问题。
- 问题4.2:系统的各个组件在真实世界的应用场景中的表现如何?
从文本中获取知识图谱的一个重要部分是识别输入文件中的实体和字词。它们在指导推理和降低搜索空间的复杂性方面起着重要作用。由于它们的特殊重要性,我们研究了我们提出的命名实体识别和链接方法对整个系统性能的影响,从而提出了研究问题。
- 问题4.3: 提出的实体识别和链接方法的影响是什么?
除了实体和字词的识别,预测它们的关系也是一个重要的子任务。为了更好地了解我们的系统在这方面产生的错误,我们调查了我们系统中关系提取的影响。这就引出了研究问题。
- 问题4.4: 提出的关系提取方法的影响是什么?
然而,我们系统的所有组件并不是纯粹基于我们提出的机器学习模型,而是遵循启发式的方法。为了了解系统的弱点和优势,有必要正确评估这些方法和启发式方法,并调查它们对导致研究问题的整体评估性能的影响。
- 问题4.5: 我们提出的针对特定领域问题的启发式解决方案的表现如何,它们的影响是什么?
1.3.2 贡献
这项工作的主要贡献是开发了一个全面而深入的适应领域的信息提取系统,该系统可以根据领域本体提供的数据模型,预测用自然语言编写的临床前研究的全部细节。我们表明,这是一个复杂的NLP-信息提取问题,到目前为止,文献中还没有考虑到它的全部复杂性。我们的目标是填充一个深层次的领域知识图,将提取的信息以结构化和明确的形式储存起来,以便进一步使用,如自动知识聚合、治疗分级和开发。
我们的主要贡献可以总结为:
-
我们建立了一个与领域无关的机器学习方法的模型,该方法能够在结构预测范式中提取深度嵌套结构,用于从自然语言文本中提取信息。见第5.1节。
-
我们为多实例预测任务提出了一个可操作的联合推理策略。见第5.2节。
-
我们设计了一个与领域无关的特征集,为各种不同的实例类型建立足够的统计模型。见第5.4节。
-
我们为高度复杂的本体类和依赖关系提出了一个数据模型驱动和领域无关的问题分解策略。见第6.1.1节。
-
我们将开发的方法应用于脊髓损伤的具体领域,并提出一个具有单向信息流的整体系统架构,以平衡推理和变量联合建模的计算成本。在此背景下,我们描述了领域的具体问题并提出了启发式的解决方案。见第6.1.2节。
-
我们提出了一个专门针对比较深度嵌套结构的任务的评价方法,该方法可作为机器学习信号以及我们的最终评价。见第7.1节。
-
最后,我们提出了对我们的系统、我们开发的方法和启发式方法的广泛评价,以了解我们的系统在多大程度上可以用于支持证据聚合所需的深度研究。我们表明,对于许多类别的SCIO来说,信息提取的结果是令人满意的,并确定了那些需要进一步研究的类别。见第7.2节。
这项工作产生的进一步的子贡献包括。
-
我们将我们开发的系统应用于一个新的未见过的数据语料库,包括大约5,700篇描述脊髓损伤临床前结果的全文文章,并对填充的深度领域知识图谱进行统计。
-
我们展示了存储在知识图谱中的信息如何被轻松过滤和汇总,以便进一步进行元数据分析、疗法开发和疗法分级。领域专家可以使用探索工具SCIExplorer[39]有效地搜索知识图谱。见第8.3节、第8.4节和第8.5节。
-
我们介绍了注释工具SANTO[40],它是我们为高度关系型数据的注释而开发的。见第8.1节。
1.3.3 概要
整篇论文分为9章。这一章对我们的工作做了总体介绍,包括我们的主要动机和对我们任务的非正式描述。我们简要地介绍了我们处理所述问题的方法,以及这项工作的挑战和范围。最后,我们提出了我们旨在回答的相关研究问题,并总结了我们工作的贡献。本论文的其余部分组织如下。
-
在第二章中,我们介绍了我们论文中使用的方法的基础,包括一般语义网元素的背景,如知识图谱、本体,以及协议和查询语言。第二部分着重介绍了所实现的概率图模型的基础,即条件随机场和因子图。
-
在第三章中,我们介绍了知识图谱群体的相关工作,并简要介绍了信息提取领域的历史背景,重点介绍了基于规则、概率和神经方法这三个主要领域,以确定我们系统的方法的位置。第二部分讨论了知识图谱群体中出现的相关自然语言处理问题。最后,我们介绍了(生物)医学领域的相关工作,并简要地讨论了现有的方法。
-
在第四章,我们介绍了我们的应用环境的领域背景。我们描述了我们旨在预测的脊髓损伤数据模型。我们通过一个详细的现实世界的信息提取问题的例子来激励这种复杂程度。最后一部分描述了用于训练和评估我们的方法和开发的系统的数据集。
-
在第五章中,我们描述了所开发的机器学习方法,它是我们系统的主要组成部分。我们解释了如何将一般的信息提取任务表述为用条件随机场和因子图进行结构预测。我们详细介绍了机器学习方法的实现,并描述了主要的元素,如目标函数、推理策略、特征工程和实体候选生成方法。
-
在第六章中,我们对我们考虑的领域和整个信息提取问题进行了复杂性分析。我们介绍了我们提出的问题分解,对整个任务的某些方面的重点选择,以及扩展主要方法的已实现的启发式算法。最后,我们介绍了我们的系统结构,解释了所有组件的互动。
-
在第七章中,我们详细描述了我们进行的实验和预测临床前脊髓损伤结果的主要评估结果。我们对系统的每个主要组成部分进行了详细的错误分析。这包括在一个必须预测实体和关系的真实世界应用场景中的表现。我们进一步分析了该系统所犯的错误,并将其与两个上界设置进行了比较,其中关系或候选人由神谕提供。
-
在第八章中,我们简要描述了在这项工作的背景下开发的几个应用,这些应用强调了(自动填充的)深度领域知识图的相关性。我们还描述了我们的系统在新的、未见过的数据上的应用,用几千个文档的知识填充一个大型知识图谱。
-
在第九章,我们总结了我们工作的主要方面,并回答了提出的研究问题。本章最后简要讨论了剩余的问题和对未来工作的建议。
1.4 出版物
本论文的主要内容基于以下经同行评议的发表论文。
[41] ter Horst, H., Hartung, M., & Cimiano, P. (2017, June). 使用无定向概率图模型在技术领域进行联合实体识别和链接。In International Conference on Language, Data and Knowledge (pp. 166-180). Springer, Cham.
[42] ter Horst, H., Hartung, M., Klinger, R., Brazda, N., M¨uller, H. W., & Cimiano, P. (2018, June)。评估基于模板的信息提取的因素图模型中单一和成对槽约束的影响。In International Conference on Applications of Natural Language to Information Systems (pp. 179- 190). Springer, Cham.
[43] ter Horst, H., Hartung, M., & Cimiano, P. (2018, September). 使用基于本体的信息提取与条件随机场的冷启动知识库人口。In Reasoning Web International Summer School (pp. 78-109). Springer, Cham.
[44] ter Horst, H., Hartung, M., Cimiano, P., Brazda, N., M¨uller, H. W., & Klinger, R. (2020). 在基于模板的信息提取的因素图模型中学习软领域约束。数据与知识工程,125,101764。
[37] ter Horst, H., & Cimiano, P. (2020, November). 在模型完整的文本理解中,结构化预测用于联合类心率和实体属性推理。In Proceedings of the Fourth Workshop on Structured Prediction for NLP (pp. 22-32).
[45] ter Horst, H., & Cimiano, P. (2020). 将从知识图谱中提取的语义依赖关系纳入基于联合推理模板的信息提取。在2020年欧洲人工智能会议上。
在整个论文中,我使用人称代词we来感谢我的合作者。然而,在之前的所有论文中,我在概念化、实施和评估等主要方面做出了贡献。
在本论文研究过程中形成并发表的其他出版物有:。
[46] Hakimov, S., ter Horst, H., Jebbara, S., Hartung, M., & Cimiano, P. (2016, November). 结合文本和基于图的特征,使用无定向概率图模型进行命名实体消歧。In European Knowledge Acquisition Workshop (pp. 288-302). Springer, Cham.
[5] Brazda, N., Estrada, V., Kirchhoffer, T., ter Horst, H., Hartung, M., Wiljes, C., ... & M¨uller, H. W. (2016). SCIO。脊髓损伤本体论,从脊髓损伤研究的出版物中自动提取数据的先决条件。在第18届脊柱研究网络会议(ISRT 2016)的论文集中。
[6] Brazda, N., ter Horst, H., Hartung, M., Wiljes, C., Estrada, V., Klinger, R., ... & Cimiano, P. (2017). SCIO:一个支持临床前脊髓损伤实验正规化的本体论。在第三届联合本体研讨会(JOWO)的会议上。生命科学中的本体和数据(第2050卷)。
[39] Borowi, A., ter Horst, H., Hartung, M., Estrada, V., Brazda, N., M¨uller, H. W., & Cimiano, P. (2017). 本体论驱动的脊髓损伤领域临床前研究数据的视觉探索。2017年SEMANTICS海报和演示论文集》,2044。
[40] Hartung, M., ter Horst, H., Grimm, F., Diekmann, T., Klinger, R., & Cimiano, P. (2018, July). SANTO:一个基于网络的注释工具,用于本体驱动的槽位填充。在计算语言学协会2018年会议上,系统演示(第68-73页)。
[47] Schwitteck, A., ter Horst, H., & Hartung, M. (2018). 核心推理链对(前期)临床试验中的实验组有何启示。In Proceedings of DGfS/CL Poster Session.

