人类正在进入人工智能时代。化学也将被现代的深度学习方法所改变,这需要大量定性数据来进行神经网络训练。
好消息是,化学数据「很好保存」。即使某种化合物最初是在 100 年前合成的,关于其结构、性质和合成方式的信息仍然与今天相关。
坏消息是,没有公认的标准方法来呈现化学公式。化学家通常使用许多技巧以简写符号的方式来表示熟悉的化学基团。但化学家的个人习惯不同,惯例也会改变。对于计算机算法来说,这项任务似乎是不可逾越的。
来自 Skoltech 的初创公司 Syntelly 和莫斯科罗蒙诺索夫国立大学的研究人员开发了
一种基于 Transformer 的人工神经网络,可以将有机结构的图像转换为分子结构。
为了训练这个网络,开发了一个综合数据生成器,它可以随机模拟各种绘图样式、官能团、官能团占位符(R 基)和视觉污染。
该研究以「
Image2SMILES: Transformer-Based Molecular Optical Recognition Engine
」为题,于 2022 年 1 月 11 日发表在
《
Chemistry–Methods
》上。
化学结构识别面临挑战
多年来,文献中发表了大量化学数据。不幸的是,在计算机时代之前,这些有价值的数据仅在纸质资源中出现。当前的挑战是从这些来源中提取和挖掘这些数据。
深度神经网络的广泛发展显著提高了光学识别任务的性能。然而,图形或弱结构信息识别一直是一个具有挑战性的问题。一个常见的例子是化学结构的识别。
首先,化学化合物的绘图风格(原子标签字体、键描绘风格等)在出版商之间没有完全标准化。其次,化合物通常被绘制为马库什(Markush)结构:可以描述许多化合物的支架,马库什结构没有通用的指导方针,这导致了各种各样的 Markush 表示。此外,在某些情况下,化学论文的作者使用使用艺术风格来代表化学结构。
以艺术风格描绘的分子示例。
总而言之,识别化学结构和分子模板是一个具有挑战性的问题,我们相信只有基于人工智能的工具才能解决这个问题。
Transformer 是谷歌团队最初提出的用于神经翻译的架构。然而,该架构及其修改在许多其他任务中表现出出色的性能,例如:在化学中,Transformer 被应用于有机反应结果的预测,SMILES 和 IUPAC 名称之间的转换。可以看出,基于 Transformer 的架构的性能通常高于基于 RNN 的方法。这一观察促使研究人员实现了一个基于 Transformer 的引擎,用于光学识别化学结构。
数据是机器学习的关键。然而,据我们所知,在化学文章上没有带有注释对象的开放访问数据集。获得大型数据集的唯一方法是构建数据生成模型。
该研究所提方法的新颖之处在于强烈关注数据生成方案,并且不仅可以处理有机结构,还可以处理分子模板,因此该方法可以用于实际数据。
在这项工作中,为了训练这个网络
,开发了一个综合数据生成器,它可以随机模拟各种绘图样式、官能团、官能团占位符(R 基)和视觉污染。
PubChem 数据库包含大约 1 亿个分子。选择 RDKit 作为自动绘图工具。
在大多数化学文献中,作者绘制了带有官能团和 R-基取代基的分子。为了生成具有此类取代基的分子,研究人员创建了 100 多个常见官能团的列表。将每个组描述为一个 SMARTS 模板。其增强算法随机替换分子中的官能团以生成增强数据集。
应该注意一些官能团是嵌套的。典型例子是:甲基 (-Me) 和甲氧基 (-OMe) 基团。研究人员设计了一种解析方法,以防止嵌套组重叠。
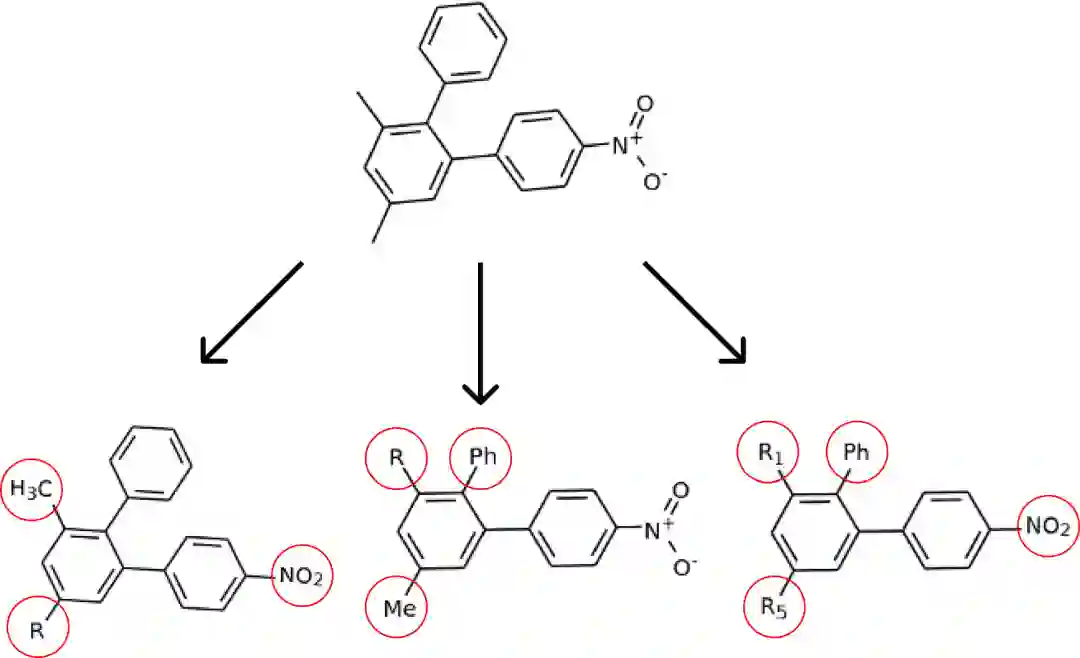
生成的具有官能团和 R 基团的分子示例。
研究人员实现了一种方法来生成具有 R 基在环中可变位置的图像。
可变位置的 R 基示例。
如果环的取代基不超过两个,则 R 基团(R、R1、R2、R'、R'')以 20% 的概率绘制在可变位置,但该算法对一个环进行一次替换,一个分子最多替换两个。添加了一个虚拟键,使 RDKit 将基团放在环键的前面,然后使用 SVG 后处理将两个键替换为单行。下面的例子给出了直观的解释。
在可变位置呈现 R 基。
在标准的 SMILES 中无法表示分子模板
,在此设计了一种修改后的语法,将其命名为 FG-SMILES。
这是标准 SMILES 的扩展,其中取代基或 R 基团可以写成单个伪原子。如果取代基是官能团,FG-SMILES 可以通过替换相应的假原子直接翻译成 SMILES。一个例子:
SMILES: Cc1cc(C)c(-c2ccccc2)c(-c2ccc([N+](=O)[O-])cc2)c1
FG-SMILES: [Me]c1cc([Me])c(-[Ph])c(-c2ccc([NO2])cc2)c1
此外,FG-SMILES 符号允许描述可变的 R 基位置。添加 v 符号来表示芳族系统内的变量 R 基团。
当我们的模型在真实环境中运行时,它会从光学扫描中裁剪出一个区域作为输入。然而,通常分子图像会被其他细节污染,实验表明,即使图像中存在很小的污染也会破坏预测。为了解决这个问题,研究人员提出了一种模拟典型污染的污染增强算法。下图给出了污染增强算法的一些结果示例。
此外,研究人员还使用了在「albumentations」库中实现的标准计算机视觉增强。
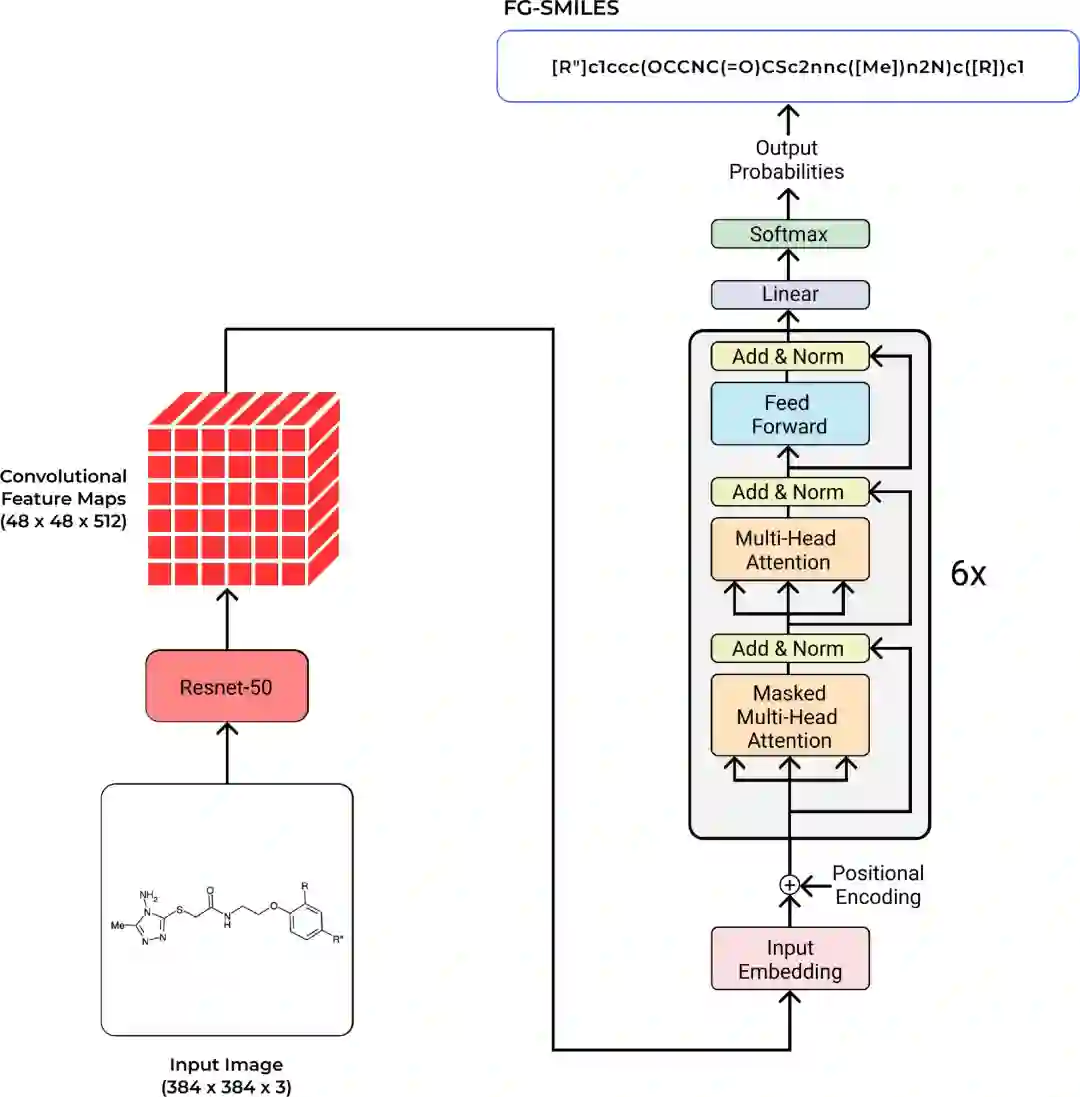
Img2SMILES 模型的输入形状为 384x384。研究人员使用 ResNet-50 作为 CNN 块。ResNet 模块的输出形状为 2048x12x12。Transformer 解码器的其他参数取自经典架构。
Img2SMILES 模型架构图。
研究人员证明了基于 Transformer 的架构可以从发生器中收集化学见解。这意味着,有了 Transformer,人们可以完全专注于数据模拟,来构建一个好的识别模型。该光学识别引擎的网络演示可在 Syntelly 平台在线获得,数据集生成的代码可在 GitHub 上免费获得。
「我们的研究很好地证明了化学结构光学识别正在进行的范式转变。虽然先前的研究主要集中在分子结构识别本身,但现在我们拥有 Transformer 和类似网络的独特能力,我们可以转而致力于创建人工样本生成器,模仿大多数现有类型的分子模板描述。我们的算法结合了分子、官能团、字体、样式,甚至打印缺陷,它引入了一些额外的分子、抽象片段等。即使是化学家也有很难判断该分子是直接来自真实的纸张还是来自发电机。」该研究的首席研究员,初创公司 Syntelly 的首席执行官 Sergey Sosnin 说。
该研究的作者希望他们的方法将构成迈向人工智能系统的重要一步,该系统能够「阅读」和「理解」研究论文,达到高素质化学家的程度。
数据生成器 GitHub 地址:https://github.com/syntelly/img2smiles
论文链接:https://chemistry-europe.onlinelibrary.wiley.com/doi/10.1002/cmtd.202100069
参考内容:
https://techxplore.com/news/2022-02-neural-network-chemical-formulas-papers.html
https://mp.weixin.qq.com/s/oljlC7k5ysGrTXNAAW62fg
公司官网:https://syntelly.com/
人工智能 × [ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。